and the distribution of digital products.
Why Are Hybrid Smart Contracts the Key to Integrating Off-Chain Data with On-Chain Logic?
 glide.r.xyz
glide.r.xyzVariant analysis is the foundation of a transformative approach to Web3 security exploration, and its importance cannot be underestimated.
Variant analysis, commonly used in open-source smart contracts, uses a known issue, such as a crashing bug or security vulnerability, to identify additional occurrences (or “variants”) across the Web3 landscape.
Have you ever discovered a vulnerability and wondered, “Are there any other contracts deployed that have the same vulnerability?”If so, ever considered how you would go about identifying those on such a large scale? Yes, you can clone any project, then upload extension into vscode, 2nd link -> add key from sourcegraph, select the contract and the AI will be analyzing the structure of your project for you (just like on example) but Glider will be even more powerful tool. Now the possibilities of the tools described earlier are very limited!
Check out Glider: glide.r.xyz!Glider IntroductionGlider is a code query engine designed to run variant and data analysis on smart contracts by providing a framework that gives anyone the ability to query contract code as one would do with data.
The researcher writes a query (called a glide) describing a scenario of code they want to match and runs it against any type of codebase; specifically, now, it can be run against whole blockchains that are integrated into the system.
Example of a glide:from glider import *def query():
# iterate over all of the instructions in the blockchain
# and find the ones that call selfdestruct()
instructions = Instructions().with_callee_function_name('selfdestruct').exec(100)
return instructionsAn example output (from Kovan testnet):{
"contract":"0xcFd05BebB84787EE2EfB2eA633981E44d754485d"
"contract_name":"AdminAuth"
"sol_function":
function kill() public onlyAdmin {
selfdestruct(payable(msg.sender));
}
"sol_instruction":
selfdestruct(payable(msg.sender))
}
This is a playbook example; in fact Glider gives the ability to describe much more complex scenarios (such as traversing CFG/DFG graphs) in smart contract code and to find the ones that match it. The core concepts of the engine are scalability, distribution and reusability.
Glider gives the possibility to do variant analysis and security research on the scale of all open-source (verified) smart contracts across integrated EVM blockchains at breakneck speed. With its taint analysis and other advanced features, Glider represents a paradigm shift in code analysis.
Giving a unified and easy-to-use interface to code, Glider’s main mission is to be a framework that can be distributed to and used by the community for greater impact on the whole industry.
One of the reasons why Glider does not introduce a new language for queries and rather uses Python syntax is to smoothen the learning curve, make it more accessible for everyone and also give more flexibility to the framework to integrate external tools.
The above mentioned concepts make glides reusable, and while the ability to describe scenarios is distributed, the reported glides can be reused by everyone and even be improved by other users and the community!
Comparison With Other ToolsThere are a variety of static analysis tools that one can use for security research purposes. In this page, we will compare Glider to some of the other tools mainly used by researchers.
Semgrep & SolgrepOne of the static analysis tools that address the reusability, ease of use, and distribution aspects is Semgrep (also solgrep which is very similar).
The main difference between Semgrep and Glider is that Semgrep works on the AST of the code and does not have the full potential to use Control Flow and Data Flow graphs of the code. Although Semgrep has taint mode, it is limited.
It only allows declarative logic, while Glider gives the ability to write both declarative and imperative logic, making it much more flexible. While benefiting from a shallow learning curve, it is limited in its functionality.
SlitherIn comparison to Semgrep, SAST tools like Slither can operate on CFG/DFG, do complex taint analysis, and so on, as well as it has well-designed IR (Intermediate Representation), moreover the Glider uses the SlithIR for intermediate representation.
But the overall downside of these kind of tool is its learning curve as well as the inability to do the analysis on a scale, which affects both distribution and scalability aspects.
Writing GlidesA glide code can be separated into two parts: declarative queries (also called online part) and imperative arbitrary logic part (offline part)
Imagine the following glide code:
def query(): # The name query() is constant, and should not be changed# Querying the DB in declarative manner
instructions = Functions()\
.with_one_property([MethodProp.EXTERNAL, MethodProp.PUBLIC])\
.without_properties([MethodProp.HAS_MODIFIERS, MethodProp.IS_CONSTRUCTOR])\
.instructions()\
.with_callee_function_name('selfdestruct')\
.exec() # chain of calls must always end with exec() otherwise the query will not be dispatched
# Arbitrary logic part, where we analyse the CFG/DFG graphs to filter the result
results =[]
for i in instructions: # iterate over instructions that we got from query
if i.has_global_df(): # check that the instruction has a dataflow from global vars
# such as msg.sender, tx.origin, function arguments etc..
# basically we want to check that the selfdestruct's param is controllable by the caller
# use a variable to mark whether the instruction should be included in the result or not
flag = True
# previous_instructions will return all of the instruction that come before in the CFG (control flow graph)
for prev in i.previous_instructions():
#check if its a function call of "if" and that it does not include msg.sender in the expression
if (prev.is_call() or prev.is_if()) and 'msg.sender' in prev.source_code():
flag = False
break
# include the instruction in the resulting set
if flag:
results.append(i)
return results # to see the results the query() function must return a list of objects
Glider compiles and constructs artefacts from source code and places them in a specialized high-performance database.
This gives the ability for query writers to query code as data in a declarative format using Glider’s API. The code part:
instructions = Functions()\.with_one_property([MethodProp.EXTERNAL, MethodProp.PUBLIC])\
.without_properties([MethodProp.HAS_MODIFIERS, MethodProp.IS_CONSTRUCTOR])\
.instructions()\
.with_callee_function_name('selfdestruct')\
.exec()
It showcases the declarative part of the glide, where we use api.Functions class to iterate over all of the functions and filter them, then we continue the chain and "level-down" to the instructions of already filtered functions, and then we filter the instructions. Note that the query chain always ends with exec() call.
Glider leverages the Python environment to give users the possibility to write arbitrary logic on the data received from DB (Arbitrary logic (CFG/DFG/Taint analysis)):
# Arbitrary logic part, where we analyse the CFG/DFG graphs to filter the resultresults =[]
for i in instructions: # iterate over instructions that we got from query
if i.has_global_df(): # check that the instruction has a dataflow from global vars
# such as msg.sender, tx.origin, function arguments etc..
# basically we want to check that the selfdestruct's param is controllable by the caller
# use a variable to mark whether the instruction should be included in the result or not
flag = True
# previous_instructions will return all of the instruction that come before in the CFG (control flow graph)
for prev in i.previous_instructions():
#check if its a function call of "if" and that it does not include msg.sender in the expression
if (prev.is_call() or prev.is_if()) and 'msg.sender' in prev.source_code():
flag = False
break
# include the instruction in the resulting set
if flag:
results.append(i)
As you can see, we use basic Python constructs and Glider’s functionality here to do quite complex filtering of the result.
We check that the instruction we got has a global dataflow (controllable by the caller) and that there is no function call or “if”s containing msg.sender that precedes the selfdestruct call.
This is a playbook example of a query, while it already can yield very good results, the query has a lot of room for improvement, e.g. instead of checking msg.sender to not be part of the expression one should check that the call/if expressions are not tainted from msg.sender. Users can combine declarative and imperative logic in any order and number.
In order to see the results, the query() function must return a list of objects, the types of objects supported for return right now are Contract, Function, Modifier, and Instruction.
Experimental Feature — Print()Glider also has an experimental feature to show you print() outputs that you would place in the query code. This is mainly useful while debugging the query code. Whatever Glider prints during the execution will be aggregated and shown as the last output root in the output (right) window.
Note that the feature is experimental and may be removed in future. Example:
for prev in i.previous_instructions():if (prev.is_call() or prev.is_if()) and 'msg.sender' in prev.procedure_graph_node.expression:
flag = False
print(prev.solidity_callee_names()) # add this line to the code
break
Output:
{"print_output": [
"['require']",
"[]",
"[]",
"[]",
"[]",
"['require']",
"[]",
"['require']",
"['require']",
"['require']",
"['require']",
"['require']",
...
]
}
You can Join our Community of Security Researchers where you can ask your questions, learn more about Glider, stay up to date on latest developments and interact directly with the creators of this powerful tool!
Glider and Declarative Query WritingDeclarative programming is a style of coding where the developer describes what should be done rather than how it should be done. In declarative code, goals or results are expressed, while the details of execution are left to the system or runtime environment.
Key Characteristics of Declarative Programming- Focus on the Result: Instead of specifying a step-by-step process for completing a task, declarative programming focuses on what needs to be achieved.
- Minimal Explicit Steps: There is no need to describe all intermediate steps of the task; the system determines how to achieve the result on its own.
- SQL: The developer describes what data is needed but does not specify how the database should retrieve it.
- Functional Programming (e.g., Haskell): The developer describes functions and relationships between data without worrying about how they will be executed.
- CSS: The appearance of elements is described, but not how the browser applies these styles. Unlike imperative programming, the declarative style simplifies code, making it easier to write, more readable and easier to modify, especially in complex systems.
- Imperative and declarative approaches to programming differ in how they describe task execution. Here are the main differences between them:
Approach to Describing a Solution:
- Imperative Approach: Focuses on how to perform a task, providing step-by-step instructions to achieve the result.
- Declarative Approach: Describes what needs to be done without specifying how it should be achieved.
Imperative (Python):
numbers = [1, 2, 3, 4, 5, 6]evens = []
for number in numbers:
if number % 2 == 0:
evens.append(number)
print(evens)
Here, the steps are explicitly specified: create a list, iterate through each element, check if it is even, and add it to a new list.
Declarative (Python, list comprehension):
numbers = [1, 2, 3, 4, 5, 6]evens = [number for number in numbers if number % 2 == 0]
print(evens)
We simply specify that we want to get the even numbers from the list, without describing the process step by step.
Readability and Code Maintenance- Imperative Approach: Can become complex to read and maintain as the number of steps and complexity of algorithms increase.
- Declarative Approach: Generally results in more concise, understandable code that is easier to maintain, as it only describes the goal.
- Imperative Approach: Typically operates at a low level of abstraction, as it requires detailed description of each step, including managing the program’s state.
- Declarative Approach: Operates at a higher level of abstraction, as it hides implementation details and focuses on the final goal.
Now that we have covered what declarative coding is, it’s time to move on to Glider! Glider gives the ability to mix declarative and imperative forms to write code queries.
Before the release of Glider 1.0: As the user has filtered Contracts/Functions/Instructions, they received a list of objects they wanted. Then, using imperative methods (e.g., if, for, while), they iterated over these objects to write their query.
This approach, while functional, has several drawbacks: Imperative code is more difficult to read and write. Due to the large number of nested loops and checks, it becomes hard to comprehend. There is a significant amount of duplicated code. Recognizing these issues, the approach to writing queries in Glider 1.0 was completely revised, and it now aligns more closely with the declarative programming style.
We simply specify that we want to get the even numbers from the list, without describing the process step by step.
What Was Changed?Now, the functions of most Glider 1.0 classes return not standard lists, sets, or tuples but new objects of the APIList/APISet/APITuple classes.
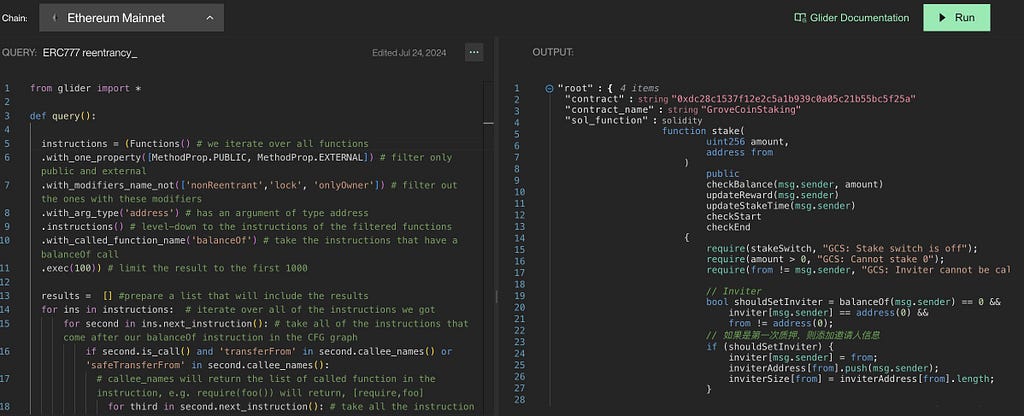
What is useful about these classes? Let’s examine the difference using the example of a query to find reentrancy vulnerabilities in ERC777.
A query without using the declarative approach looks as follows:
from glider import *def query():
"""
@title: ERC777 reentrancy.
@description: The query is designed to find ERC777 reentrancy bugs in contracts, the pattern looks like this.
@author: Hexens team.
@tags: reentrancy, erc777, read-only reentrancy, bridge
@references: https://github.com/Hexens/Smart-Contract-Review-Public-Reports/blob/main/Hexens_Polygon_zkEVM_PUBLIC_27.02.23.pdf
"""
instructions = (
Functions() # we iterate over all functions
.with_one_property([MethodProp.PUBLIC, MethodProp.EXTERNAL]) # filter only public and external
.without_modifier_names(['nonReentrant', 'lock', 'onlyOwner']) # filter out the ones with these modifiers
.with_arg_type('address') # has an argument of type address
.instructions() # level-down to the instructions of the filtered functions
.with_callee_function_name('balanceOf') # take the instructions that have a balanceOf call
.exec(3000)) # limit the result to the first 3000
results = [] # prepare a list that will include the results
for ins in instructions: # iterate over all of the instructions we got
for second in ins.next_instruction(): # take all of the instructions that come after our balanceOf instruction in the CFG graph
if second.is_call() and ('transferFrom' in second.callee_names() or 'safeTransferFrom' in second.callee_names()):
for third in second.next_instruction(): # take all the instructions that come after the transferFrom
if third.is_call() and 'balanceOf' in third.callee_names(): # check that we have a balanceOf once more
results.append(ins) # append to the resulting set
break
return results
In this query, the declarative part is only the fragment where we find all instructions with the function call transferFrom. Additionally, the function where transferFrom is called must be public or external, one of its arguments must be of type address, and it should not contain the modifiers nonReentrant, lock, or onlyOwner.
After we find the corresponding instructions, we use a for loop to iterate through them and, using the next_instruction() function, obtain the next instruction after the balanceOf call. We then check if this instruction contains a call to the transferFrom or safeTransferFrom function. If such a call is present, we move to the next instruction after the transferFrom/safeTransferFrom call and check if the balanceOf function is called there.
If so, we have found the required contracts. We add such instructions to the result list and return it. The entire code for this query takes around 40 lines, uses 3 for loops, and creates one result list.
Now let’s look at the new syntax in Glider 1.0 for declarative query writing. The logic of the query will remain unchanged:
from glider import *def query():
instructions = (
Functions()
.with_one_property([MethodProp.PUBLIC, MethodProp.EXTERNAL])
.without_modifier_names(['nonReentrant', 'lock', 'onlyOwner'])
.with_arg_type("address")
.instructions()
.with_callee_function_name('balanceOf').exec(3000)
.next_instruction()
.filter(lambda x: "transferFrom" in x.callee_names() or 'safeTransferFrom' in x.callee_names())
.next_instruction()
.filter(lambda x: "balanceOf" in x.callee_names())
)
return instructions
The first thing that stands out is the noticeable reduction in the amount of code compared to the initial query.
Let’s explore how it works!
The first part, where we retrieve the necessary instructions, remains the same as in the previous query. However, next, we use the next_instruction function, which is only available for objects of type Instruction. How is this possible? In Glider Engine, after calling the exec() function, you get a list of objects depending on the type of the object on which the exec() method was called.
For example, when exec() is called on an object of type Instructions, the function will return an APIList[Instruction], whereas in the previous version of Glider, it would have returned a List[Instruction]. What is the difference between APIList[type] and List[type]? APIList[type] allows you to apply a method not to the entire list at once, but to each individual element.
Therefore, we can call the next_instruction method, which is defined for Instruction, on the entire list of instructions without using a for loop. One of the key features of the APIList[type], APISet[type], and APITuple[type] structures is their unidimensionality. This means that when calling the next_instructions function, which returns an APIList[Instruction], the result will be a one-dimensional APIList.
In other words, the lists returned from the called functions maintain the same type of structure APIList, APISet, or APITuple with which we started working. This makes it possible to chain functions/properties on the list, as with other declarative parts.
This feature has its pros and cons. The advantage is that we always know exactly the data type we deal with. However, the downside is that sometimes, due to this feature, it may be necessary to use traditional imperative approaches. For example, if you need to filter the list returned by the next_instructions function and select the original instructions based on checks, this might require breaking the query chain and using loops.
It is important to note that after calling such a method, all objects in APIList[Instruction] will be modified. In our case, APIList[Instruction] will contain all subsequent instructions for the instructions obtained in the first part of our query.
What does this give us? The ability to write queries this way allows for more compact and readable queries, as seen in the examples.
One of the significant updates is the filter() function, which also supports better chaining list filtering during query writing. The filter() function is a higher-order function that takes another function as an argument. The function passed to filter() must be a predicate function, meaning it should return a boolean value (true or false).
This requirement ensures more explicit query behaviour. The filter() function allows the following: if the predicate function is passed to filter() returns true, the object from APIList[type] will remain in the list; if false, the object will be removed. This helps eliminate if statements, making queries shorter and more readable.
Let’s examine the use of the filter() function with an example. In the declarative query, the first call to filter() received a predicate lambda function: lambda x: "transferFrom" in x.callee_names() or 'safeTransferFrom' in x.callee_names(). As an argument, this lambda function automatically receives an instruction from the APIList[Instruction] list. If the lambda function returns true, the instruction remains in the APIList[Instruction]; if false, it is removed.
As a result, the length of the query code is 12 lines. This query does not use for loops or if statements, and no separate result list is created. The readability of the query has significantly increased, and the process of writing it has become simpler.
Variant Analysis & GliderWith it, variant analysis is extremely important in the ever-changing world of Web3. Because smart contracts are open source by design, the ability to identify and address vulnerabilities at scale has become critical. Variant analysis, as a core component of Web3 security, is an effective tool for proactively identifying and mitigating potential risks across integrated EVM blockchains.
daily-glider/articles/handy-scripts/README.md at main · ustas-eth/daily-glider
The implementation of Variant analysis in Web3 security tools is poised to redefine the landscape of cybersecurity practices. By facilitating the systematic discovery of related vulnerabilities and issues, this innovative approach empowers security researchers and developers to enhance the integrity and resilience of decentralized applications, ultimately safeguarding the Web3 ecosystem.
Glider has a powerful declarative query domain-specific language. Any abstraction, such as a line of code, variable, function, or anything else, is presented as an object. Navigate across EVM chains, and catch hidden gems of the Ethereum ecosystem:
- All contracts deployed on a blockchain.
- Focus on specific functions within contracts.
- Identify function-specific modifiers.
- Drill down into low-level instructions.
- We also plan to add an SC state query soon!
The ability to identify, analyze, and mitigate vulnerabilities at scale will not only solidify the foundations of Web3 security but also foster an ecosystem where trust, integrity, and resilience prevail.
GitHub - mrthankyou/eagle-owl: A library designed to aid Gliders when writing glides
Glider allows you to query the functions of a specific contract. Here is how we found an EigenLayer StrategyManager contract and all of its functions:
Glider provides you with API functions to query for Solidity contracts. Here’s a basic query example that finds a smart contract on chain:
This is how “functions” work in Glider:
Eventually, variant analysis, has proven especially important in Web2 environments. Variant analysis, however, becomes even more essential as Web3 smart contracts become more intricate and interconnected.
Glider IDE and Its FunctionalitiesSecurity researchers can now thoroughly examine the source code of smart contracts and uncover potential vulnerabilities and threats more successfully than ever before thanks to Glider’s capacity for complex variant analysis.
Glider IDE:- Glider IDE is a revolutionary research tool that allows developers and researchers to query contracts at scale. Glider allows researchers to query EVM-chain deployed Solidity code for common vulnerabilities, code patterns, and compliance verification to just name a few.
- Glider IDE provides users several key features that include an embedded editor to write Glides, the ability to run Glides against EVM chains, and view Glider documentation.
- Glider IDE is a one-stop shop for researchers interested in finding bugs, collecting statistical data, and developing queries to build implementation standards.
- While some SAST tools allow declarative logic, and others have complex learning curves and no scalability, Glider supports both declarative and imperative logic and runs on the blockchain scale.
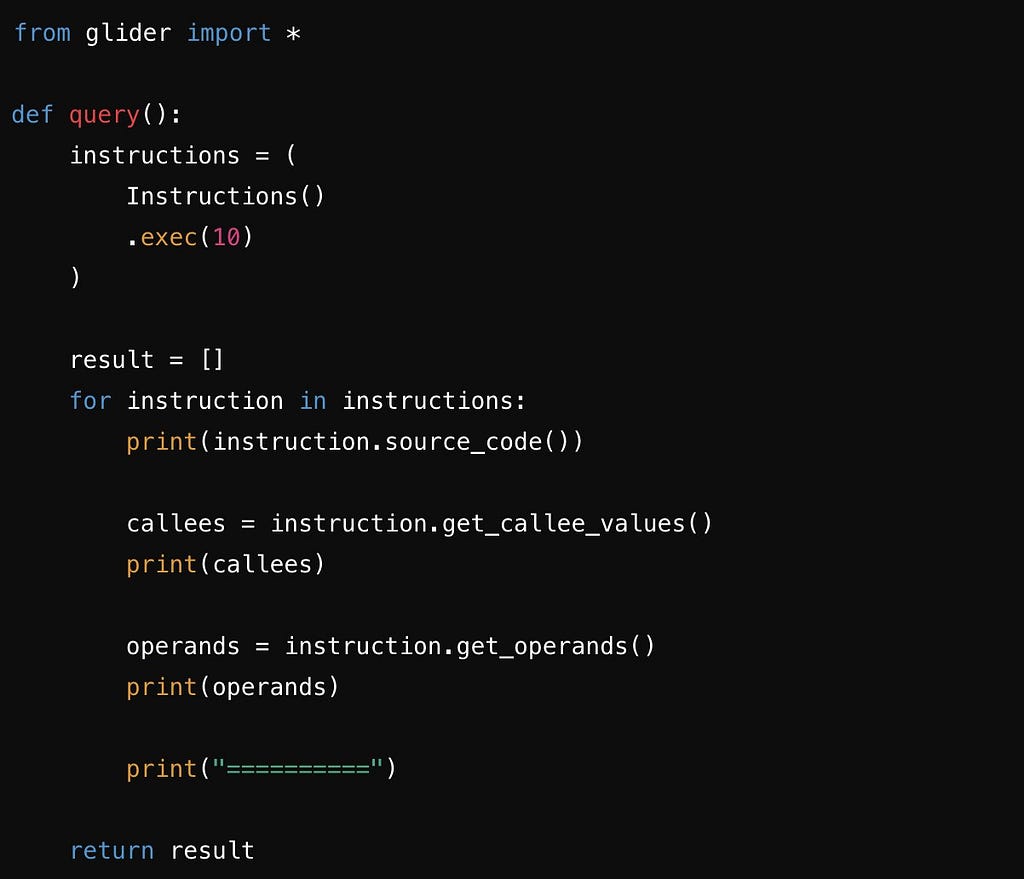
- ‘Instruction’ comes in various forms, such as ‘AssemblyInstruction’, ‘IfInstruction’, ‘NewVariableInstruction’, ‘ReturnInstruction’, and more. Each class represents a specific Solidity instruction, letting you filter and work with precise code segments.
- For example, filtering ‘if’ conditions in Solidity. It isolates ‘IfInstruction’ instances, enabling targeted analysis.
- get_callee_values(): Retrieve all calls within an instruction.
- get_operands(): Break down instructions into individual operands.
- get_parent(): Navigate up to the parent function or modifier.
- .is_storage_read()/.is_storage_write(): Identify storage access within instructions.
- .next_instruction()/.previous_instruction(): Traverse instructions sequentially.
- .backward_df()/.forward_df(): Navigate through data flow to trace how functions are utilized before and after the current instruction.
- Utilizing Glider’s ‘Instruction’ gives you unmatched control over how Solidity code is analyzed and processed. And all of that at a breakneck speed. Explore these advanced methods today to refine your queries and foster your security research.
- This query demonstrates .get_callee_values() and .get_operands() use case, showing how to extract and analyze specific details within instructions. What other tool can do that?
 Daily Glider
Daily GliderWe’re planning to give Glider main-net access to more researchers at the beginning of October. During this period, we are actively improving the user experience based on the feedback of security researchers. If you are interested in early access, please reach out:
Join the Remedy Discord Server!
Stay Safe!Variant Analysis & Glider Tool was originally published in Coinmonks on Medium, where people are continuing the conversation by highlighting and responding to this story.