and the distribution of digital products.
Where does In-context Translation Happen in Large Language Models: Appendix
:::info Authors:
(1) Suzanna Sia, Johns Hopkins University;
(2) David Mueller;
(3) Kevin Duh.
:::
Table of Links- Abstract and 1. Background
- 2. Data and Settings
- 3. Where does In-context MT happen?
- 4. Characterising Redundancy in Layers
- 5. Inference Efficiency
- 6. Further Analysis
- 7. Conclusion, Acknowledgments, and References
- A. Appendix
In addition to the language pairs en → fr and fr → en, we also run experiments on English and Spanish language pairs, both en → es and es → en. Due to space limitations, we plot the results of those experiments here. Overall, we see largely identical trends on both directions of English and Spanish to what we observe on English and French translation tasks, leading us to conclude that our conclusions generalize across different translation tasks.
A.4. Autoregressive Decoder only TransformerThe transformer consists of stacked blocks of self-attention, which itself consists of smaller units of self-attention heads that are concatenated before being fed through a fully connected layer. In autoregressive decoder-only transformers, training and inference adopts a causal mask, where current positions are only able to attend to previous timesteps, instead of being able to attend to the entire input sequence. Unlike encoder-decoder NMT models where source and target sentence have separate processing transformer blocks, decoder-only means that the same model weights are both used to “encode" the source sentence and “decode" the target sentence in a single continuous sequence.
A.5. Training with Autoregressive TranslationThe original language modeling objective in GPT training involves predicting the entire input token sequence which consists of both the source and target sentence (shifted by 1 position). We found this to produce slightly worse results than only minimising the negative log likelihood of predicting the target sentence to be translated, and not the entire sequence. We consider this autoregressive translation training.
A.6. L0 Attention Gate TrainingTraining Details For Section 6.5, We train using Adam Optimizer (β1 = 0.9, β2 = 0.999) with a batch size of 32, and learning rate of 0.001, early stopping patience of 10 and threshold of 0.01. We initialise attention head gates to be 1 instead of random or 0.5 as this leads to faster convergence. We experiment with two different training settings, the 0-prompts Train setting and the 5-prompts Train setting. As described in Section A.5, we train the model by predicting only the target sentence, conditioned on the context. In the 0-prompt setting, the context consists of the instructions and the source sentence to be translated. In the 5-prompt setting, the context consists of the instructions, 5 prompt examples, and the source sentence to be translated.
\ In the 0-prompt setting, the conditional prefix consists of the instructions and the source sentence to be translated. In the 5-prompt setting, the conditional prefix consists of the instruction, 5 source target sentence pairs, and the source sentence to be translated.
\ Data We used the first 10,000 lines of en → fr from WMT06 Europarl (Koehn, 2005) for training.[7] To test the generalisability of trained attention head gates, we use a different test domain, FLORES (Goyal et al., 2021) to reflect the scarcity of in-domain data. We also test an additional language direction en→pt in FLORES to see if training can generalise across languages.
\ Training Details We train using Adam Optimizer (β1 = 0.9, β2 = 0.999) with a batch size of 32, and learning rate of 0.001. We use a large early stopping patience of 10 and threshold of 0.01, and train for up to 100 epochs. This is due to the nature of L0 training; we do not expect performance to improve over many iterations and would like the attention gates to keep training as long as there is no large loss in performance. We initialise attention head gates to be 1 instead of random or 0.5 as this leads to much faster convergence and better performance. For the regularisation weight λ, we search over a hyperparameter set of {0.1, 0.01, 0.001, 0.0001} and found 0.01 performs best on the validation set.
A.7. L0 head masking experiments.Additional experiments on L0 head masking in the fr→ en and es→ en direction.
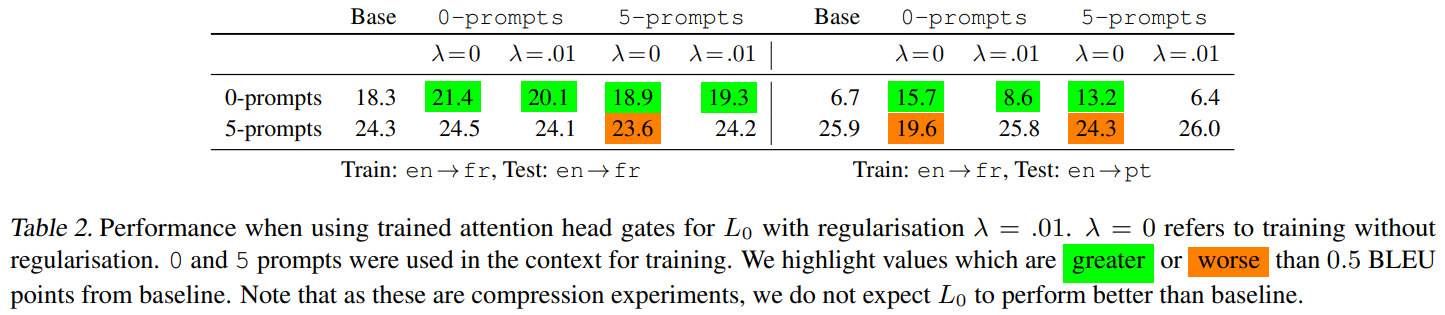
A.8. Generalisability of L0 gate trainingWe experiment with 0-prompts and 5-prompts in training and using λ = 0 (no regularisation) and λ = 0.01. L0 training for the 0-prompts shows some gains for the 0-prompts test case, and with no loss on the 5-prompts test case (Table 2). Notably, this persists in en→pt, a different language direction from training.
\ The robustness of translation performance under multiple testing conditions (number of prompts, datasets, language directions) gives some confidence that the trained discrete attention head gates from L0 support a general ability to translate (Table 2). In contrast, the soft attention head gates without regularisation (λ = 0) appear to overfit as they perform well on some conditions but deteriorate in others.
\ We observe that 0-prompt training for L0(λ = 0.01) also
\
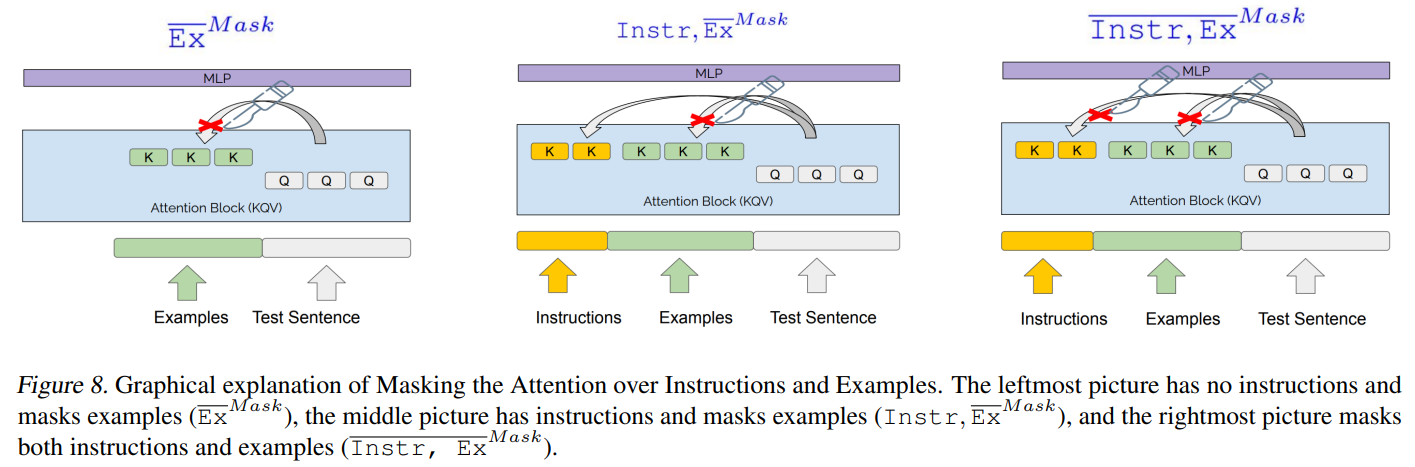
\

\
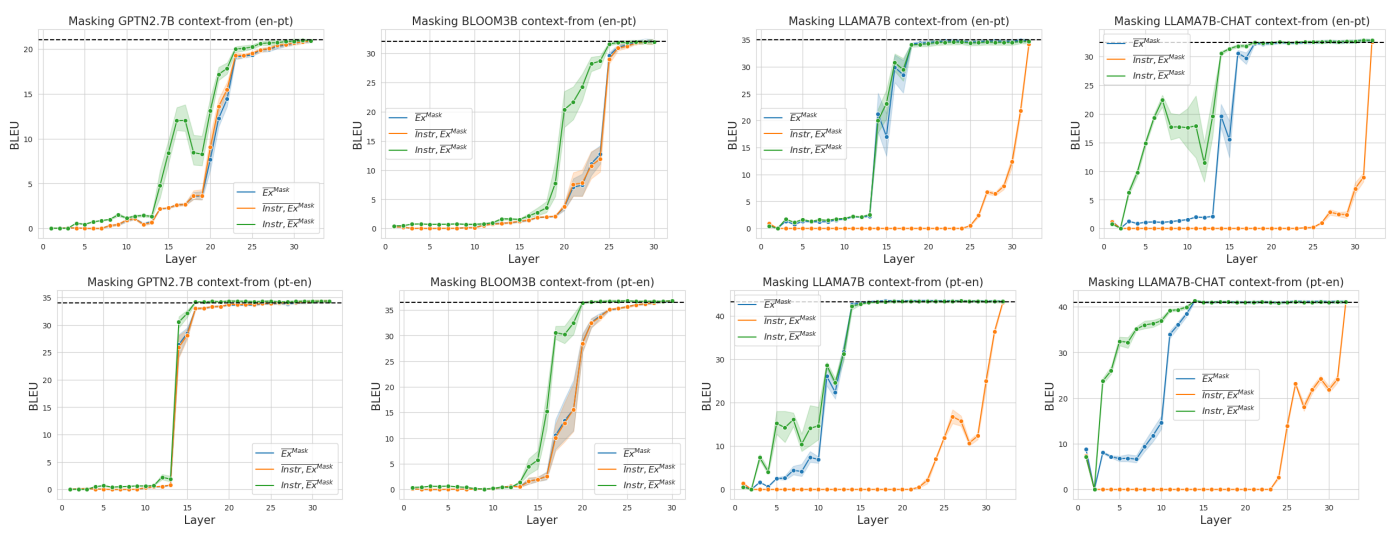

\ BLOOM is observed to be more robust to masking of layers; suggesting that task location is more distributed.
\
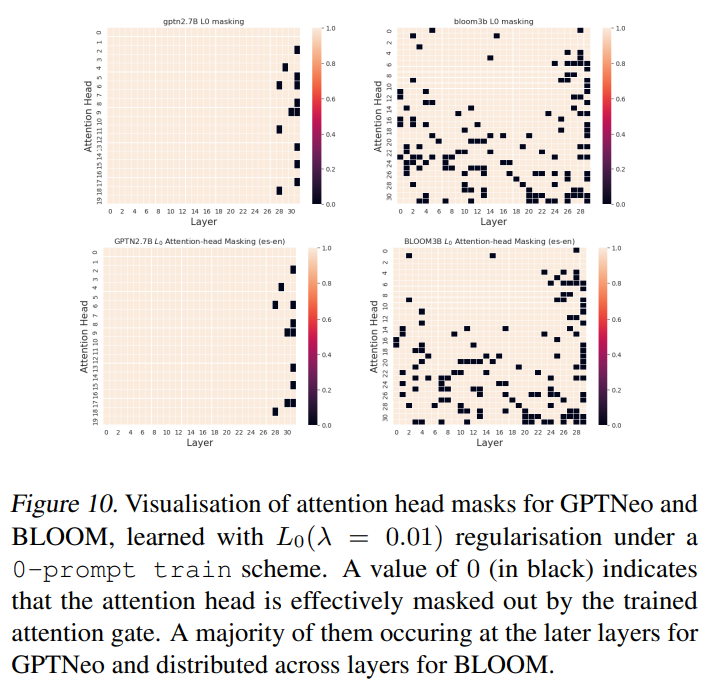
\
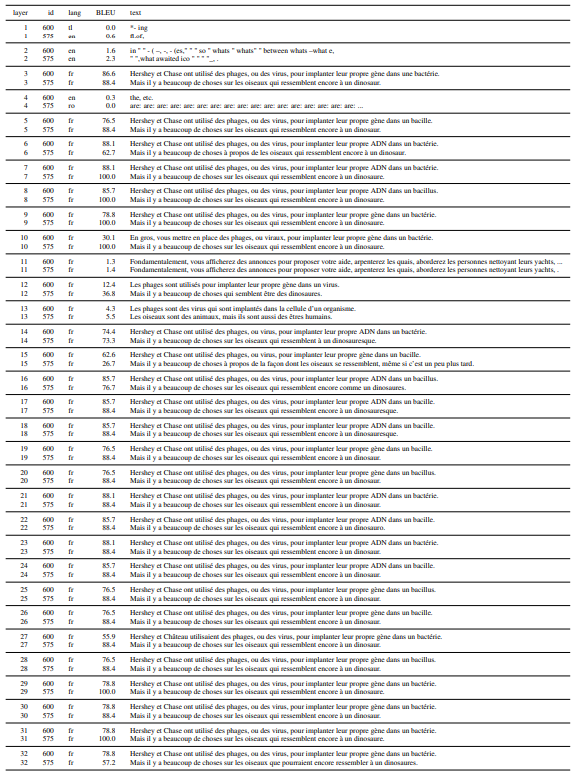
\ For the 5-prompt setting, the performance only decreases very slightly. For the 0-prompt setting, we observe that similar to GPTNEO, performance drops when masking out the middle layers. At the aggregate level, BLOOM appears to still be translating (> 0 BLEU) even when layers are masked. However we observe that the drop in performance is due to around 40 to 50% of the test sentences scoring < 5 BLEU points. There is a clear failure to translate, not simply producing poorer translations.
\

\

\

\
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
[7] Data available from https://www.statmt.org/europarl/