and the distribution of digital products.
What You Need to Know About Amazon Bedrock’s RAG Evaluation and LLM-as-a-Judge for Advancing AI
What if AI could not only give you the answers but also check itself to ensure those answers were right? Just imagine if an AI system could evaluate its own performance, tweak its approach, and keep learning – all on the fly.
\n Sounds like something straight out of a sci-fi novel, doesn’t it? But the fact is – this is a real deal. In fact, 85% of businesses are investing in AI to improve decision-making, and with AI-generated content adoption expected to grow 20x by 2030, ensuring these systems are accurate, reliable, and self-improving is critical.
\ These goals are becoming a reality thanks to Amazon’s Bedrock and its innovative use of Retrieval-Augmented Generation (RAG) evaluation and LLM-as-a-judge frameworks.
\ Now, I know what you’re thinking: “That sounds impressive, but what does it actually mean for me? Well, buckle up because we’re about to take a deep dive into how these innovations are flipping the script on AI and creating more intelligent, adaptable, and reliable systems.
\n So, whether you are a developer, business leader, or just a curious AI enthusiast, this is one ride you don’t want to miss.
\ In this blog, we will explore how Amazon Bedrock is reshaping AI development with a deep focus on advanced RAG techniques and how Large Language Models are now being empowered to serve as judges for their own performance.
\ Let’s explore the depth of these AI innovations and uncover Bedrock’s true potential.
What is Amazon Bedrock? A Quick OverviewBefore we dive into the technicalities, let’s get a quick lay of the land. Amazon Bedrock is like the Swiss army knife of generative AI. It’s a fully managed service that helps developers and organizations build, scale, and fine-tune AI applications using models from some of the top AI labs like Anthropic, Stability AI, and AI21 Labs. No need to reinvent the wheel—Bedrock gives you a powerful, easy-to-use platform to plug into advanced AI technologies, saving you the headaches of starting from scratch.
Core Features of Amazon Bedrock- Access to Diverse Models: Developers can choose from a variety of pre-trained foundational models tailored to different use cases, including conversational AI, document summarization, and more.
- Serverless Architecture: Bedrock eliminates the need for managing the underlying infrastructure, allowing developers to focus solely on innovation.
- Customizability: Fine-tune models to meet domain-specific requirements using your proprietary data.
- Secure and Scalable: With Amazon’s robust cloud infrastructure, Bedrock ensures enterprise-grade security and the ability to scale with growing demands.
\ But here’s where it gets exciting: Amazon didn’t stop at just making AI accessible—they supercharged it with RAG evaluation and LLM-as-a-Judge. These two features aren’t just bells and whistles—they’re game-changers that’ll make you rethink what AI can do.
Let’s Break It Down: RAG Evaluation – What’s in It for You?Retrieval-Augmented Generation (RAG) is all about helping AI models get smarter, faster, and more accurate. Instead of relying solely on pre-trained knowledge, RAG lets the AI pull in real-time data from external sources like databases, websites, or even other AI systems. This is like giving your AI a search engine to help it make more informed decisions and generate more relevant answers.
\ Imagine asking an AI about the latest trends in Quality Engineering Solutions. With RAG, it doesn’t just give you a generic response—it goes out, finds the latest research, pulls in data from trusted sources, and gives you an answer backed by current facts.
\ For example**, Ada Health**, a leader in AI healthcare, is using Bedrock’s RAG framework to pull the latest research and medical information during consultations. So, when you’re using the platform, it’s like having an AI-powered doctor with access to every medical paper out there – instantly.
Why Is RAG Important?Traditional generative models often produce hallucinations—responses that sound plausible but are factually incorrect. RAG mitigates this by:
\
- Mitigating Hallucinations
Hallucinations produced by Generative can undermine trust in AI applications, especially in critical domains like healthcare or finance. By integrating external knowledge sources, RAG ensures that the AI’s responses are grounded in real-world, up-to-date data.
\ For Example,
A medical chatbot powered by RAG retrieves the latest clinical guidelines or research articles to provide accurate advice instead of relying solely on outdated pre-trained knowledge.
\
- Enhancing Contextual Accuracy
Traditional generative models generate outputs based on the patterns they learned during training, which may not always align with a query’s specific context. By retrieving contextually relevant information, RAG aligns generated outputs with the input query’s specific requirements.
\ For Example,
In legal applications, a RAG-powered AI can retrieve jurisdiction-specific laws and apply them accurately in its generated response.
\
- Providing Traceability
One of the significant limitations of standard generative models is the lack of transparency in their outputs. Users often question the origin of the information provided. Since RAG retrieves information from external sources, it can cite the origin of the data, offering traceability and transparency in responses.
\ For Example,
An e-commerce recommendation engine powered by RAG can explain product suggestions by referencing customer reviews or recent purchases.
\
- Supporting Real-Time Updates
Static pre-trained models cannot adapt to changes in the real world, such as breaking news, policy updates, or emerging trends. RAG systems access external databases and APIs, ensuring that the information used is current and relevant.
\ For Example,
A financial AI tool powered by RAG can provide market insights based on real-time stock performance and news updates.
\
- Tailored and Domain-Specific Applications
Different industries require AI systems to provide highly specialized and accurate responses. Generic generative models may not always meet these needs. By retrieving domain-specific knowledge, RAG ensures that responses are aligned with industry requirements.
\ For Example,
In customer support, RAG-enabled chatbots can pull answers from product-specific knowledge bases, ensuring precise and personalized responses.
\
- Addressing Latency Concerns
While integrating external sources introduces the risk of slower response times, RAG systems have evolved to optimize retrieval mechanisms, balancing accuracy and efficiency. Advanced RAG frameworks, such as those in Amazon Bedrock, incorporate latency optimization techniques to maintain a seamless user experience.
\ For Example,
A real-time language translation system uses RAG to fetch relevant phrases and cultural nuances without compromising speed.
Amazon Bedrock’s RAG Evaluation FrameworkAmazon Bedrock’s RAG Evaluation framework tackles various challenges with a systematic, metrics-driven approach to enhance RAG-enabled applications. Here’s how:
\
- End-to-End Metrics: The framework evaluates both retrieval and generation components, ensuring a seamless pipeline from input query to output response.
- Customizable Benchmarks: Developers can define specific evaluation criteria to suit unique industry or application needs, such as regulatory compliance or customer satisfaction.
- Automated Analysis: Bedrock’s tools assess retrieval accuracy, information relevance, and coherence of generated responses with minimal manual intervention.
- Feedback Loops: Continuous feedback mechanisms help refine retrieval strategies and improve model outputs dynamically over time.
\
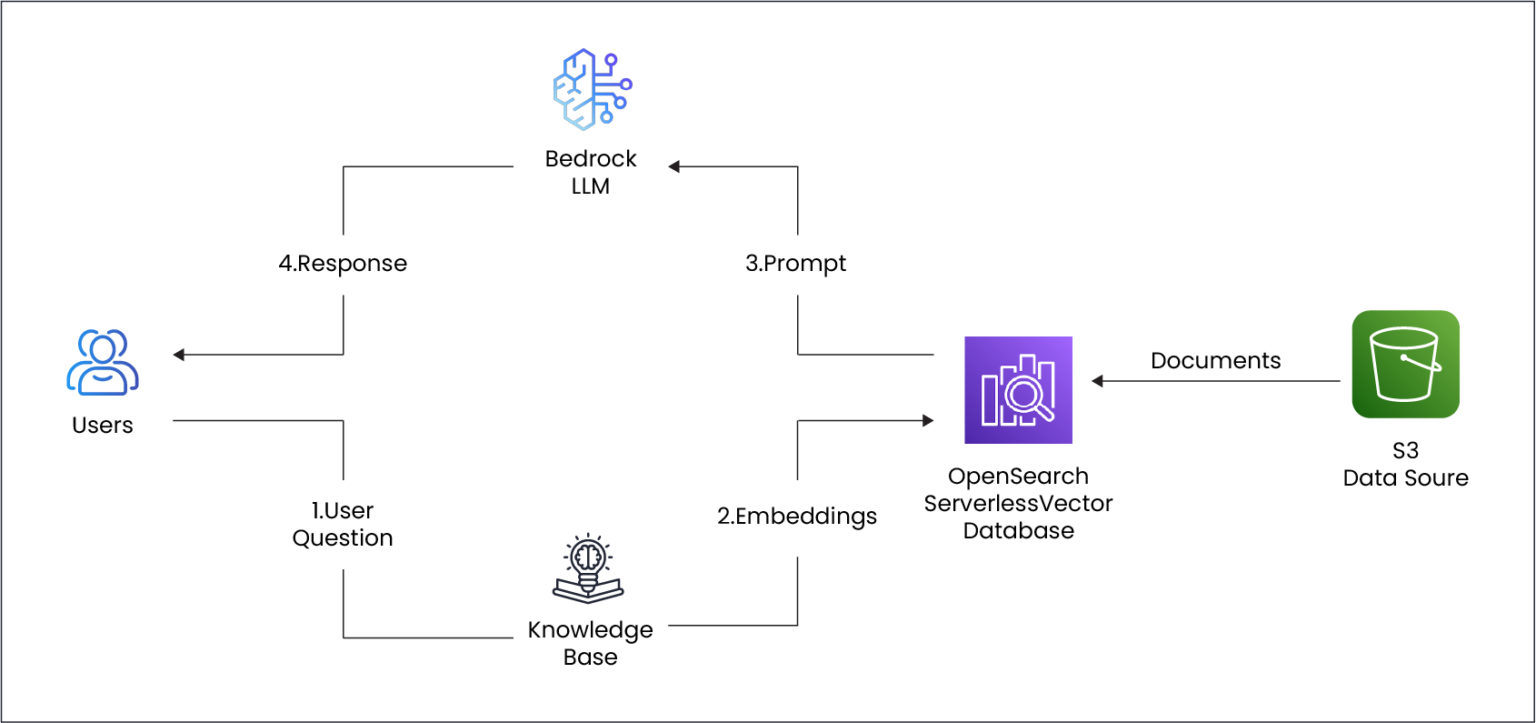
\
LLM-as-a-Judge – The Self-Checking Genius of AINow, let’s look into something even more mind-blowing: LLM-as-a-Judge. Think of it this way: Imagine you’ve just aced your math exam. But instead of celebrating, you quickly go back and check your answers, just to be sure. That’s essentially what this self-assessment feature does for AI.
\ LLMs now have the ability to evaluate their own output and make adjustments as needed. No more waiting for human intervention to catch errors or inconsistencies. This self-correcting AI can tweak its answers in real time, improving accuracy and relevance on the spot.
\ A 2024 study found that models using self-evaluation (like LLM-as-a-Judge) were 40% more accurate in generating relevant responses than their counterparts. Companies leveraging this self-evaluating tech have reported a 30% faster decision-making process. This means real-time solutions, faster results, and, ultimately, less waiting.
\ The more data it processes, the more it can fine-tune its responses based on internal metrics.
\
Key Features of LLM-as-a-Judge1. Scalability
One of the most critical aspects of LLM-as-a-Judge is its ability to process and evaluate massive volumes of data simultaneously. Traditional evaluation methods often involve time-consuming human annotation processes, limiting their ability to scale. LLM-as-a-Judge overcomes this limitation by:
\
- Automating Evaluation: It evaluates thousands of AI outputs in parallel, dramatically reducing time spent on quality assessment.
- Supporting Large-Scale Deployments: This is ideal for industries like e-commerce and finance, where models generate millions of outputs daily, such as personalized recommendations or market analyses.
\ For Example,
In customer service, an AI might produce responses to 100,000 queries a day. LLM-as-a-Judge can efficiently evaluate these responses’ relevance, tone, and accuracy within hours, helping teams refine their models at scale.
\ 2. Consistency
Unlike human evaluators, who may bring subjectivity or variability to the evaluation process, LLM-as-a-Judge applies uniform standards across all outputs. This ensures that every model evaluation adheres to the same rubric, eliminating biases and inconsistencies.
\
- Objective Scoring: Provides unbiased assessments based on predefined criteria such as factual accuracy, language fluency, or tone appropriateness.
- Repeatable Results: Delivers consistent evaluations even across different datasets, making iterative testing more reliable.
\ For Example,
In education, evaluating AI-generated quizzes or teaching materials for appropriateness and clarity can vary with human graders. LLM-as-a-Judge ensures uniformity in evaluating such outputs for every grade level and subject.
\ 3. Rapid Iteration
By providing near-instant feedback on model outputs, LLM-as-a-Judge enables developers to rapidly identify issues and make necessary refinements. This iterative approach accelerates the development cycle and improves the overall performance of AI systems.
\
- Immediate Insights: Offers actionable feedback on errors or suboptimal performance, reducing debugging time.
- Shorter Time-to-Market: Speeds up AI application deployment by enabling quick resolution of performance gaps.
\ For Example,
For a chatbot intended to provide legal advice, the LLM-as-a-Judge can immediately flag inaccuracies in responses or detect when outputs stray from jurisdiction-specific guidelines, enabling swift corrections.
\n 4. Domain Adaptability
LLM-as-a-Judge is not limited to general use cases; it can be tailored to evaluate outputs within specific domains, industries, or regulatory environments. This flexibility makes it invaluable for specialized applications where domain expertise is essential.
- Custom Rubrics: Developers can configure evaluation criteria to suit industry-specific needs, such as compliance standards in healthcare or financial regulations.
- Fine-Tuning Options: Adaptable to evaluate highly technical content like scientific papers or financial reports. \n
\ For Example,
In the healthcare industry, LLM-as-a-Judge can evaluate AI-generated diagnostic suggestions against up-to-date clinical guidelines, ensuring adherence to medical standards while minimizing risks.
Advantages Over Traditional Evaluation- Reduced Human Dependency: Significantly lowers reliance on human expertise, cutting costs and time.
- Enhanced Precision: Advanced LLMs can identify subtle issues or inconsistencies that might escape human reviewers.
- Iterative Learning: Continuous feedback enables models to evolve dynamically, aligning closely with desired outcomes.
1. Enhancing AI Trustworthiness
Both RAG Evaluation and LLM-as-a-Judge directly address the challenge of AI trustworthiness. By focusing on factual accuracy, relevance, and transparency, these tools ensure that AI-driven decisions are not only intelligent but also reliable.
\ 2. Democratizing AI Development
Amazon Bedrock’s accessible platform, combined with its robust evaluation frameworks, empowers developers across all expertise levels to create cutting-edge AI solutions without the burden of complex infrastructure management.
\ 3. Accelerating AI Deployment
With automated and scalable evaluation mechanisms, developers can iterate and deploy AI applications at unprecedented speeds, reducing time-to-market.
\ 4. Empowering Domain-Specific Applications
From specialized medical diagnostics to personalized e-commerce recommendations, these tools allow developers to tailor AI models to unique use cases, driving impact across industries.
How Is the World Adopting These Innovations?Let’s talk about where all this theory meets reality. Some of the biggest names in tech and healthcare are already embracing these innovations and let me tell you—it’s paying off.
\ #1 Amazon’s Own E-Commerce Giants
\ Amazon, the pioneer of AI-driven e-commerce, is utilizing Bedrock’s LLM-as-a-Judge to refine the accuracy of its personalized shopping assistant. By continuously assessing its own product recommendations and adapting based on customer feedback, Amazon’s AI can make real-time adjustments to its suggestions, improving customer satisfaction.
\ The RAG framework allows Amazon to retrieve the latest product reviews, trends, and pricing data, ensuring that users receive the most relevant and up-to-date recommendations.
\ #2 Goldman Sachs and Real-Time Financial Intelligence
\ Goldman Sachs, an American financial services company has integrated Bedrock’s RAG evaluation into its AI-powered risk assessment tool. By using RAG, the tool can pull in the latest financial data and market trends to provide real-time risk assessments. With LLM-as-a-Judge, Goldman Sachs’ AI models continuously evaluate the accuracy and relevance of their predictions, ensuring that the investment strategies provided to clients are always data-backed and informed by current market conditions.
Challenges and Considerations for Bedrock’s RAG and LLM-as-a-JudgeWhile the potential for these advancements is enormous, there are still challenges that need to be addressed:
\
- Data Privacy: As RAG relies on external data sources, it is essential to ensure that this data is clean, trustworthy, and compliant with privacy regulations.
- Model Bias: Like all AI models, Bedrock’s systems must be constantly monitored for bias, especially when self-evaluation mechanisms could amplify pre-existing model flaws.
- Scalability and Cost: While Bedrock simplifies AI integration, businesses must consider the cost implications of scaling RAG evaluation and LLM-as-a-Judge across multiple models and industries.
So, where are we headed from here? As powerful as Amazon Bedrock is right now, the road ahead is even more exciting. Expect more sophisticated self-evaluation systems, faster and more accurate data retrieval techniques, and a broader adoption of these tools across industries. Whether you’re in healthcare, finance, e-commerce, or tech, Bedrock is setting the stage for AI systems that don’t just perform—they evolve with you.
\ But let’s face it: LLMs aren’t perfect on their own. They need the right testing, the right optimization, and the right engineering to truly shine. Testing LLMs isn’t just about ticking boxes—it’s about unlocking their true potential. At Indium, we don’t settle for merely functional models; we dive deep beneath the surface, analyzing every layer to refine performance and maximize impact. With over 25+ years of engineering excellence, we’ve made it our mission to transform AI from “good enough” to truly groundbreaking.