and the distribution of digital products.
Understanding AI Verification: A Use Case for Mira
- Decentralized verification improves factual reliability by having Mira filter AI outputs through a network of independent models, reducing hallucinations without retraining or centralized oversight.
- Consensus mechanisms replace individual model confidence by requiring multiple independently operated models to agree before any claim is approved.
- 3 billion tokens per day are verified by Mira across integrated applications, supporting more than 4.5 million users across partner networks.
- Factual accuracy has risen from 70% to 96% when outputs are filtered through Mira’s consensus process in production environments.
- Mira functions as infrastructure rather than an end user product by embedding verification directly into AI pipelines across applications like chatbots, fintech tools, and educational platforms.
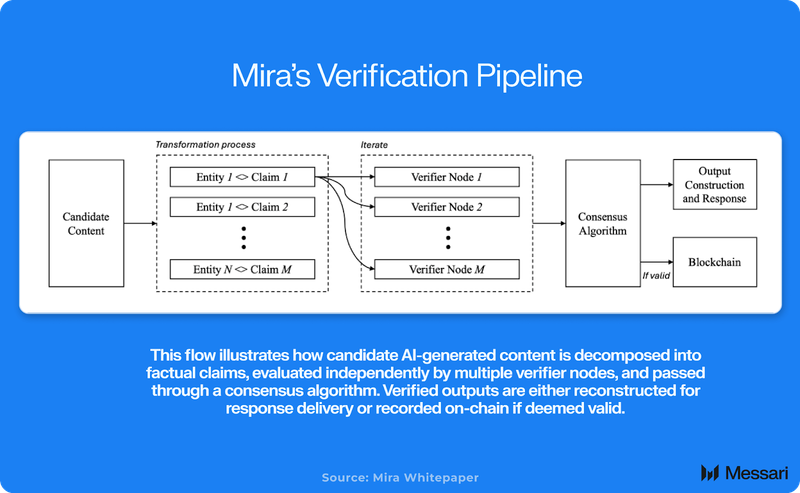
Mira is a protocol designed to verify the outputs of AI systems. At its core, it functions like a decentralized audit/trust layer. Whenever an AI model generates an output, whether an answer or a summary, Mira evaluates whether the “factual” claims in that output can be trusted before it reaches the end user.
The system works by breaking down each AI output into smaller factual claims. These claims are independently assessed by multiple verifier nodes across Mira’s network. Each node operates its own AI model, often with a different architecture, dataset, or point of view. The models vote on each claim, deciding whether it is true, false, or context-dependent. A consensus mechanism determines the outcome: if a supermajority of models agree on the claim's validity, Mira approves it. If there is disagreement, the claim is flagged or rejected.
No central authority or hidden model makes the final call. Instead, truth is determined collectively, emerging from a distributed group of diverse models. The entire process is transparent and auditable. Every verified output is accompanied by a cryptographic certificate: a traceable record showing which claims were evaluated, which models participated, and how they voted. This certificate can be used by applications, platforms, or even regulators to confirm that the output passed through Mira’s verification layer.
Mira draws inspiration from ensemble techniques in AI and consensus mechanisms from blockchain. Instead of aggregating predictions to improve accuracy, it aggregates evaluations to determine trustworthiness. It filters, rejecting outputs that fail a distributed test for truth.
Website / X (Twitter) / Discord / LinkedIn
Why AI Needs VerificationModern AI models are not deterministic, meaning they do not always return the same output for the same prompt and cannot guarantee the truth of what they generate. This is not a flaw; it directly results from how large language models are trained: by predicting the next token based on probability rather than certainty.
This probabilistic nature gives AI systems their flexibility. It allows them to be creative, contextual, and humanlike. However, this also means they can confidently make things up.
We have already seen the consequences. Air Canada’s chatbot invented a non-existent policy for bereavement fares and relayed it to a user. That user, trusting the chatbot, booked tickets based on the false information and suffered a financial loss. A court later ruled that the airline was liable for the chatbot’s hallucination. In short, the AI made a confident claim, and the company paid the price.
This is just one case. Hallucinations are widespread. They appear in research summaries with inaccurate citations, educational apps that present fabricated historical facts, and AI-written news briefs containing false or misleading claims. This is because these outputs are often fluent and authoritative, users tend to accept them at face value.
Beyond hallucinations, there are more systemic issues:
- Bias: AI models can reflect and amplify biases present in their training data. This is not always overt. It may manifest subtly through phrasing, tone, or prioritization. For example, a hiring assistant may systematically favor one demographic over another. A financial tool may generate risk assessments that use skewed or stigmatizing language.
- Non-Determinism: Ask the same model the same question twice and you may get two different answers. Change the prompt slightly and the result can shift in unexpected ways. This inconsistency makes AI outputs difficult to audit, reproduce, or rely on over time.
- Blackbox Nature: When an AI system provides an answer, it usually offers no explanation or traceable reasoning. There is no breadcrumb trail showing how it concluded. As a result, when a model makes a mistake, it is difficult to diagnose the cause or apply a fix.
- Centralized Control: Most AI systems today are closed models controlled by a few large companies. Users have limited options if a model is flawed, biased, or censored. There is no second opinion, transparent appeals process, or competing interpretations. The result is a centralized control structure that is difficult to challenge or verify.
Existing Approaches and Their Limits
Several methods are used to improve the reliability of AI outputs. Each provides partial value, but all have limitations that prevent them from scaling to the level of trust required for critical applications.
- Human-in-the-Loop (HITL): This method involves having humans review and approve AI outputs. It can work effectively in low-volume use cases. However, it quickly becomes a bottleneck for systems producing millions of responses per day, such as search engines, support bots, or tutoring apps. Human review is slow, costly, and introduces its forms of bias and inconsistency. For example, xAI’s Grok uses AI tutors to evaluate and refine answers manually. This is a temporary solution that Mira views as a low-leverage fix: it cannot scale and does not address the root problem of unverifiable AI logic.
- Rule-Based Filters: These systems apply fixed checks, such as flagging forbidden terms or comparing outputs against a structured knowledge graph. While applicable in narrow contexts, they only work for the developers' anticipated cases. They cannot handle novel or open-ended queries and struggle with subtle errors or ambiguous claims.
- Self-Verification: Some models include mechanisms to assess their confidence or critique their responses using auxiliary models. However, AI systems are notoriously poor at recognizing their own mistakes. Overconfidence in false answers is a persistent issue, and internal feedback loops often fail to correct it.
- Ensemble Models: In some systems, multiple models cross-check each other. While this can raise the quality bar, traditional ensembles are typically centralized and homogeneous. If all the models share similar training data or come from the same vendor, they may share the same blind spots. Diversity in architecture and perspective is limited.
Mira aims to target these issues that it perceives. It aims to create an environment where hallucinations are caught and eliminated, biases are minimized through diverse models, outputs become reproducibly certifiable, and no single entity controls the truth verification process. Examining how Mira’s system works reveals how each of the above problems is addressed in a novel way.
How Mira Aims to Improve AI ReliabilityCurrent methods for improving AI reliability (centralized and dependent on one source of truth). Mira introduces a different model. It decentralizes verification, builds in consensus at the protocol level, and applies economic incentives to reinforce honest behavior. Rather than acting as a standalone product or top-down oversight tool, Mira functions as a modular infrastructure layer that can be integrated into any AI system.
The protocol's design is grounded in several core principles:
- Factual accuracy should not depend on one model’s output.
- Verification must be autonomous, not reliant on constant human supervision.
- Trustworthiness should emerge from independent agreement, not centralized control.
Mira applies distributed computing principles to AI verification. When an output is submitted, such as a policy recommendation, financial summary, or chatbot reply, it is first decomposed into smaller factual claims. These claims are structured as discrete questions or statements and routed to a network of verifier nodes.
Each node runs a different AI model or configuration and evaluates its assigned claims independently. It returns one of three judgments: true, false, or uncertain. Mira then aggregates these responses. If a configurable supermajority threshold is met, the claim is verified. If not, it is flagged, dropped, or returned with a warning.
Mira’s distributed design delivers multiple structural benefits:
- Redundancy and diversity: Claims are cross-checked by models with varied architectures, datasets, and perspectives.
- Fault tolerance: A failure or error in one model is unlikely to be replicated across many.
- Transparency: Every verification outcome is recorded onchain, providing an auditable trail of which models participated and how they voted.
- Autonomy: Mira operates continuously and in parallel, without requiring human moderators.
- Scale: The system can handle large workloads measured in billions of tokens per day.
Mira’s core insight is statistical: while individual models may hallucinate or reflect bias, the odds that multiple independent systems make the same mistake in the same way are significantly lower. The protocol uses that diversity to filter out unreliable content. Similar in principle to ensemble learning, Mira expands the idea into a distributed, verifiable, and cryptoeconomically secure system that can be embedded into real-world AI pipelines.
 Node Delegators and Compute Contributions
Node Delegators and Compute ContributionsMira Network's decentralized verification infrastructure is bolstered by a global community of contributors who provide the necessary compute resources to run verifier nodes. These contributors, known as node delegators, are pivotal in scaling the protocol's capacity to process and verify AI outputs at production scale.
What is a Node Delegator?
A node delegator is an individual or entity that rents or supplies GPU compute to verified Node Operators, rather than operating a verifier node themselves. This delegation model allows participants to contribute to Mira's infrastructure without the need to manage complex AI models or node software. By providing access to GPU resources, delegators enable Node Operators to perform more verifications in parallel, enhancing the system's capacity and robustness.
Node delegators are economically incentivized for their participation. In return for contributing compute, they earn rewards tied to the amount and quality of verification work performed by the nodes they support. This creates a decentralized incentive structure where network scalability is directly linked to community participation, rather than centralized infrastructure investment.
Leading Node Operators
Compute is sourced through Mira's founding Node Operator partners, who are key players in the decentralized infrastructure ecosystem:
- Io.Net: A decentralized physical infrastructure network (DePIN) for GPU compute, providing scalable and cost-effective GPU resources.
- Aethir: An enterprise-grade, AI and gaming-focused GPU-as-a-service provider, offering decentralized cloud computing infrastructure.
- Hyperbolic: An open-access AI cloud platform, facilitating affordable and coordinated GPU resources for AI development.
- Exabits: A pioneer in decentralized cloud computing for AI, addressing GPU shortages and optimizing resource allocation.
- Spheron: A decentralized platform simplifying the deployment of web applications, providing transparent and verifiable solutions.
Each partner operates verifier nodes on Mira's network, utilizing delegated compute to validate AI outputs at scale. Their contributions enable Mira to sustain high verification throughput, processing billions of tokens daily while maintaining speed, fault tolerance, and decentralization.
Note: Each participant is only allowed to purchase one node delegator license. Users will have to prove their unique participation through a KYC process that involves “assisted video verification”.
Adoption at Scale: Mira’s Usage and AccuracyAccording to team-provided data, Mira’s network verifies over 3 billion tokens daily. In language models, a token refers to a small unit of text, typically a word fragment, short word, or piece of punctuation. For example, the sentence “Mira verifies outputs” would be broken into multiple tokens. This reported volume suggests that Mira is processing large amounts of content across various integrations, including chat assistants, educational platforms, fintech products, and internal tools using the Verified Generate API. At the content level, this throughput equates to millions of paragraphs or factual assertions evaluated daily.
Mira’s ecosystem, including partner projects, reportedly supports more than 4.5 million unique users, with approximately 500,000 daily active users. These figures include direct users of Klok and end users of third-party applications that integrate Mira’s verification layer in the background. While most users may not interact with Mira directly, the system functions as a silent verification layer, helping ensure that AI-generated content meets certain accuracy thresholds before reaching the end user.
Large language models that previously achieved around 70 percent factual accuracy in domains like education and finance now reach up to 96 percent verified accuracy when filtered through Mira’s consensus process, according to a research paper conducted by the Mira Team. Notably, these gains have been achieved without retraining the models themselves. Instead, the improvements stem from Mira’s filtering logic. The system filters out unreliable content by requiring agreement from multiple independently operated models. This effect is especially relevant for hallucinations, or unsupported and false claims generated by AI, which have reportedly declined by 90 percent across integrated applications. Because hallucinations are often idiosyncratic and inconsistent, they are unlikely to pass through Mira’s consensus mechanism.
In addition to improving factual reliability, Mira’s protocol is designed to support open participation. Verification is not restricted to a central group of moderators. To align incentives, Mira applies a system of economic rewards and penalties. Verifiers who consistently align with consensus receive performance-based compensation, while those submitting manipulated or inaccurate judgments face penalties. This structure encourages honest behavior and promotes competition among diverse model configurations. By removing reliance on centralized oversight and embedding incentive alignment at the protocol level, Mira enables scalable and decentralized verification in high-volume environments without compromising output standards.
 Conclusion
ConclusionMira offers a structural solution to one of the most pressing challenges in AI: the inability to verify outputs reliably and at scale. Rather than relying on a single model’s confidence or human oversight after the fact, Mira introduces a decentralized verification layer that runs parallel with AI generation. The system filters out unsupported content by breaking outputs into factual claims, distributing them across independent verifier nodes, and applying a consensus mechanism. It improves reliability without requiring model retraining or centralized control.
Early metrics, while self-reported, indicate increasing adoption and significant improvements in factual accuracy and hallucination reduction. Mira is already being integrated across chat interfaces, educational tools, and financial platforms, positioning it as a foundational layer for applications where accuracy matters. As the protocol matures and third-party audits become more common, Mira’s combination of transparency, reproducibility, and open participation could offer a scalable trust framework for AI systems operating in high volume or regulated environments.