and the distribution of digital products.
Tutor Training Dataset & Sequence Labeling Annotation
2. Background
2.1 Effective Tutoring Practice
2.2 Feedback for Tutor Training
2.3 Sequence Labeling for Feedback Generation
2.4 Large Language Models in Education
3. Method
3.1 Dataset and 3.2 Sequence Labeling
3.3 GPT Facilitated Sequence Labeling
4. Results
6. Limitation and Future Works
\ APPENDIX
B. Input for Fine-Tunning GPT-3.5
C. Scatter Matric of the Correlation on the Outcome-based Praise
D. Detailed Results of Fine-Tuned GPT-3.5 Model's Performance
3.1 DatasetOur study received IRB ethical approval with the protocol number: STUDY2018 00000287 from Carnegie Mellon University. The study utilized a dataset comprising responses from 65 volunteer tutors who participated in the Giving Effective Praise lesson. The demographic breakdown of these tutors was as follows: 52% were White, 18% Asian, and 52% male, with over half being 50 years or older. The objective of Giving Effective Praise is to equip tutors with skills to boost student motivation through the delivery of effective praise. We collected 129 responses from the tutors who completed the lesson, and these responses are sorted according to the type of praise (i.e., effort-based praise, outcome based praise, and person-based praise). Notably, the dataset contained only one instance of person-based praise (“You are very smart”), leading to its exclusion from the analysis. Thus, our study mainly focused on the analysis of effort based and outcome-based praise.
3.2 Sequence LabelingWe aim to provide explanatory feedback that can highlight components of effort-based and outcome-based praise within the tutor responses. Thus, we decided to use a sequence labeling method. By doing so, we created the annotation guideline as well as specific examples of Effort and Outcome based on the studies [55, 8, 7]. To carry out the annotation work, we hired two expert educators who first completed the lesson of Giving Effective Praise from our platform and then started annotating the praise tags representing attributes associated with Effort and Outcome, for 129 tutor responses.
\ In the pursuit of advancing our understanding of effective praise within tutoring dialogues, our study leverages the Inside-Outside (IO) labeling scheme [31] in our study. The IO scheme can capture the necessary information for our analysis, allowing us to maintain focus on the core aspects of praise within tutor responses without the need for differentiating between the beginning or end of entities, which aligns with our needs. The IO scheme, characterized by its simplicity and efficiency, labels tokens as an inside tag (I) and an outside tag (O). The I tag is for the praise components, whereas the O tag is for non-praise words. For example, when annotating praise components for a tutor’s praise “You are making a great effort”, the words “great” and “effort” are identified as part of the Effort (i.e., I Effort) and the remaining text in the response is identified as the outside (i.e., ‘O’) of the praise components. By annotating the praise components for each tutor response, we can obtain a list of tokens as shown in Figure 2.
\
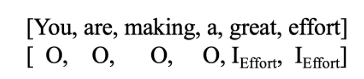
\ \ In assessing inter-rater reliability for our study, we note that while Cohen’s Kappa is considered the standard measure of inter-annotator agreement for most annotation tasks [44], its suitability for sequence labeling tasks—Named Entity Recognition or similar tasks where labels are assigned to specific words or tokens within a sequence—is limited [4, 16]. Specifically, sequence labeling may result in partial agreements between annotators (e.g., consensus on token label type but not on exact boundaries), which may not be effectively captured by Cohen’s Kappa as it does not account for partial agreement [4]. Additionally, in sequence labeling, a large proportion of tokens are typically labeled as ‘O’ (the distribution of token labels in our study is shown in Table 2), leading to an imbalanced label distribution. Since Cohen’s Kappa assumes an equal likelihood of each category being chosen, it may not provide a meaningful measure of agreement in situations where the vast majority of labels belong to a single category, making the metric less informative or even misleading [4]. Given these limitations, F1 score is often preferred for evaluating inter-rater reliability in sequence labeling tasks as suggested in previous studies [4, 11]. As the token level Cohen’s Kappa scores can also provide some insight, we provide both Cohen’s Kappa and F1 scores to provide a comprehensive view of annotator agreement in our study. Our results—0.49 for Cohen’s Kappa and 0.79 for the F1 score—were deemed acceptable for the purposes of our task as suggested by [4, 15]. To address discrepancies between two annotators, a third expert was invited to resolve inconsistencies. The distribution of annotated praise in our dataset is as follows: 59 responses with only effort-based praise, 22 with only outcome-based praise, 31 containing both types, and 17 lacking mentions of either, illustrating the varied nature of praise within the responses.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
:::info Authors:
(1) Jionghao Lin, Carnegie Mellon University ([email protected]);
(2) Eason Chen, Carnegie Mellon University ([email protected]);
(3) Zeifei Han, University of Toronto ([email protected]);
(4) Ashish Gurung, Carnegie Mellon University ([email protected]);
(5) Danielle R. Thomas, Carnegie Mellon University ([email protected]);
(6) Wei Tan, Monash University ([email protected]);
(7) Ngoc Dang Nguyen, Monash University ([email protected]);
(8) Kenneth R. Koedinger, Carnegie Mellon University ([email protected]).
:::
\