and the distribution of digital products.
Turn Audio to Text on Your Device – Free Whisper WebGPU Guide
In this article, I’m going to show you how you can easily transcribe audio and video files on your own computer using Whisper WebGPU — without needing an internet connection.
Initial Requirements to Run Whisper Model LocallyWe are going to build a web application, so you would need:
- Terminal
- Git
- Node.js & NPM
- Browser: Chrome or Firefox
- Windows 10+, Linux, or Mac (note: Safari on MacOS not fully support WebGPU)
\ The basic hardware requirements:
- Multi-core processor i5 or higher.
- 16 GB of RAM is preferable for large audio or video files.
Whisper is an advanced speech recognition system developed by OpenAI. It’s designed to transcribe spoken language into written text and can also translate different languages. Whisper is known for its accuracy and ability to understand a variety of accents, languages, and even background noise, making it one of the most reliable tools for converting audio to text.
\

\ One of the best things about Whisper is that it’s open-source, meaning anyone can access it and use it for free. It can be run on cloud servers or even on your local computer, depending on your needs.
\ Official website: https://openai.com/index/whisper/
Hugging Face’s Transformers.js and ONNX Runtime WebWe are going to use Whisper WebGPU https://github.com/xenova/whisper-web/tree/experimental-webgpu project.
\ This project utilizes OpenAI’s Whisper model and runs entirely on your device using WebGPU. It also leverages Hugging Face’s Transformers.js and ONNX Runtime Web, allowing all computations to be performed locally on your device without the need for server-side processing. This means that once the model is loaded, you won’t need an internet connection.
\ Key Features of Whisper WebGPU:
- Real-Time In-Browser Processing: The technology allows for real-time speech recognition within the browser, enhancing user privacy by eliminating the need to send data to external servers.
- Multilingual Support: It supports transcription and translation in 100 languages, making it a versatile tool for global applications.
- Local Computation: By leveraging WebGPU technology, the model runs entirely on the user’s device, which not only enhances privacy but also allows for offline functionality once the model is initially loaded.
- Model Characteristics: The core model used is Whisper-base, which is optimized for web inference with a size of approximately 200 MB. This makes it lightweight yet powerful enough for real-time applications.
I will show you how to run it on Ubuntu (Linux). However, if you use Windows or Mac, you can follow the same steps inside, but you have to use the terminal.
Step 1. Istall GIT, Node.JS, and NPMIf you are using Ubuntu, Git should be already there. However, if it’s not, use this command:
sudo apt update sudo apt install git\ Install Node.js:
sudo apt install nodejs\ Install NPM:
sudo apt install npm Step 2. Turn on WebGPU in the BrowserEnsure your browser is configured to support WebGPU. Inside the address bar in Chrome Browser write chrome://flags, then find “Unsafe WebGPU Support” enable it, and relaunch the browser.
\
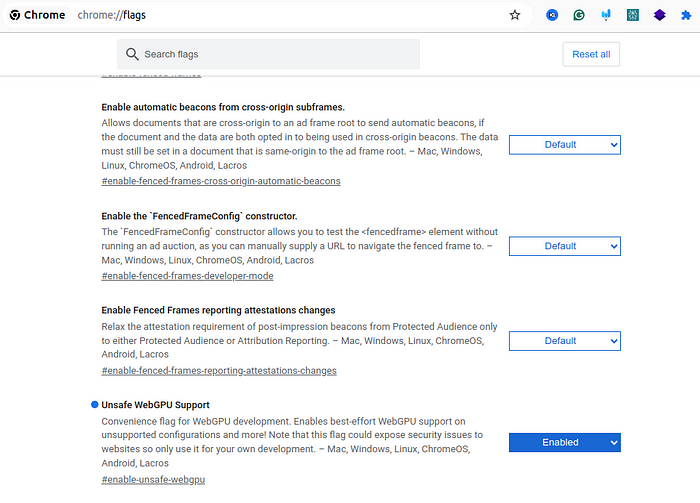
\ This is still an experimental feature in some browsers, so you may need to enable it in browser settings.
You can check the WebGPU status by opening chrome://gpu/ in your browser.
\
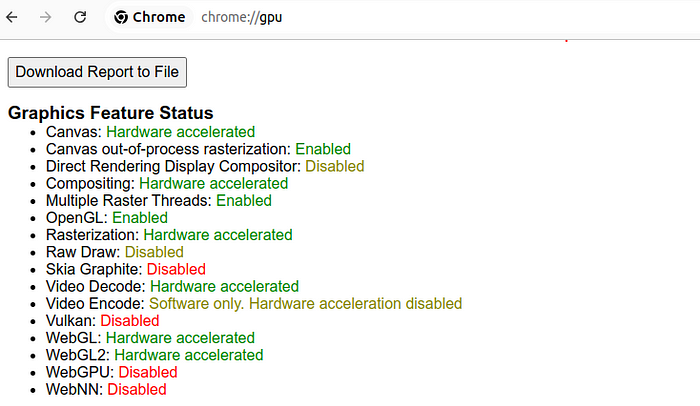
\ In some cases on Ubuntu, even after relaunching, WebGPU could be disabled. In this case, try to open the browser with the following command:
/opt/google/chrome/chrome --enable-unsafe-webgpu Step 3. Clone Repository and Install DependenciesClone the Whisper WebGPU project by following the command:
git clone https://github.com/xenova/whisper-web.git\ Once the cloning process is finished, go inside the folder whisper-web:
cd whisper-web\ Then run the following command:
npm install\ After that run:
npm run dev\ To start a web server. The URL of your web application will be available in the terminal window. E.g. http://localhost:5174/

\
Step 4. Run the ApplicationGo to your browser and open the URL from the terminal to see your application.
\
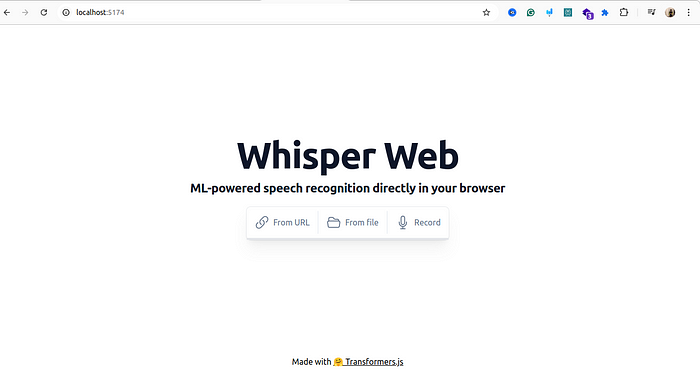
\ This web application supports various audio and video formats and even recording from your microphone.
\ To start the transcription process, simply provide the URL to the audio or upload the video file from your local computer.
\
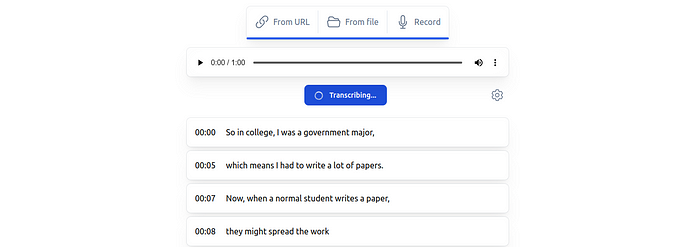
\
Video Tutorialhttps://youtu.be/YQWNuRTCcUk?si=G35I7B_gb6GYaT9m&embedable=true
\ Watch on YouTube: Audio and Video to text converter.
ConclusionWhisper WebGPU represents a significant step forward in speech recognition technology by bringing powerful, AI-driven transcription and translation capabilities directly to your browser. By utilizing OpenAI’s Whisper model and advanced tools like WebGPU, Transformers.js, and ONNX Runtime Web, this project makes real-time, offline transcription accessible to everyone while also prioritizing privacy and convenience.
\ If you like this tutorial, please follow me on YouTube, or join my Telegram. Thanks! :)