and the distribution of digital products.
Source Code Analysis of Apache SeaTunnel Zeta Engine (Part 2): Task Submission Process on the Client Side
\ Continuing from the previous article, Source Code Analysis of Apache SeaTunnel Zeta Engine (Part 1): Server Initialization
\
Task Submission on the Client SideIn this section, we will explain the task submission process in Apache SeaTunnel using the command-line interface (CLI).
To submit a task using the CLI, the command is:
./bin/seatunnel.sh -cWhen we check this script file, we see it ultimately calls the org.apache.seatunnel.core.starter.seatunnel.SeaTunnelClient class.
public class SeaTunnelClient { public static void main(String[] args) throws CommandException { ClientCommandArgs clientCommandArgs = CommandLineUtils.parse( args, new ClientCommandArgs(), EngineType.SEATUNNEL.getStarterShellName(), true); SeaTunnel.run(clientCommandArgs.buildCommand()); } }This class has only one main method. Similar to the server-side code mentioned earlier, it constructs ClientCommandArgs.
Command-Line ParametersLet’s examine the clientCommandArgs.buildCommand method.
public Command buildCommand() { Common.setDeployMode(getDeployMode()); if (checkConfig) { return new SeaTunnelConfValidateCommand(this); } if (encrypt) { return new ConfEncryptCommand(this); } if (decrypt) { return new ConfDecryptCommand(this); } return new ClientExecuteCommand(this); }Here, jcommander is used to parse the arguments. Depending on the user's input, it decides which class to construct—for example, whether to validate the configuration file, encrypt or decrypt a file, or submit a task as a client. We will not go into detail about the other classes here; instead, let's focus on ClientExecuteCommand.
The main code for this class is in the executemethod. Since the method is quite long, I will break it down into parts and explain each section.
Connecting to the ClusterIn this section of the code, the hazelcast-client.yaml file is read, and an attempt is made to establish a connection to the server. When using the local mode, a Hazelcast instance is created locally, and the client connects to it. When using the cluster mode, it connects directly to the cluster.
public void execute() throws CommandExecuteException { JobMetricsRunner.JobMetricsSummary jobMetricsSummary = null; LocalDateTime startTime = LocalDateTime.now(); LocalDateTime endTime = LocalDateTime.now(); SeaTunnelConfig seaTunnelConfig = ConfigProvider.locateAndGetSeaTunnelConfig(); try { String clusterName = clientCommandArgs.getClusterName(); // Load configuration ClientConfig clientConfig = ConfigProvider.locateAndGetClientConfig(); // Depending on the task type, if 'local' mode is used, the server-side process mentioned above has not been executed, // so we create a local SeaTunnel server first. if (clientCommandArgs.getMasterType().equals(MasterType.LOCAL)) { clusterName = creatRandomClusterName( StringUtils.isNotEmpty(clusterName) ? clusterName : Constant.DEFAULT_SEATUNNEL_CLUSTER_NAME); instance = createServerInLocal(clusterName, seaTunnelConfig); int port = instance.getCluster().getLocalMember().getSocketAddress().getPort(); clientConfig .getNetworkConfig() .setAddresses(Collections.singletonList("localhost:" + port)); } // Connect to the remote or local SeaTunnel server and create an engineClient if (StringUtils.isNotEmpty(clusterName)) { seaTunnelConfig.getHazelcastConfig().setClusterName(clusterName); clientConfig.setClusterName(clusterName); } engineClient = new SeaTunnelClient(clientConfig); // Omitted second part of the code // Omitted third part of the code } } catch (Exception e) { throw new CommandExecuteException("SeaTunnel job executed failed", e); } finally { if (jobMetricsSummary != null) { // When the job ends, print the log log.info( StringFormatUtils.formatTable( "Job Statistic Information", "Start Time", DateTimeUtils.toString( startTime, DateTimeUtils.Formatter.YYYY_MM_DD_HH_MM_SS), "End Time", DateTimeUtils.toString( endTime, DateTimeUtils.Formatter.YYYY_MM_DD_HH_MM_SS), "Total Time(s)", Duration.between(startTime, endTime).getSeconds(), "Total Read Count", jobMetricsSummary.getSourceReadCount(), "Total Write Count", jobMetricsSummary.getSinkWriteCount(), "Total Failed Count", jobMetricsSummary.getSourceReadCount() - jobMetricsSummary.getSinkWriteCount())); } closeClient(); } }The image below illustrates the process:
\
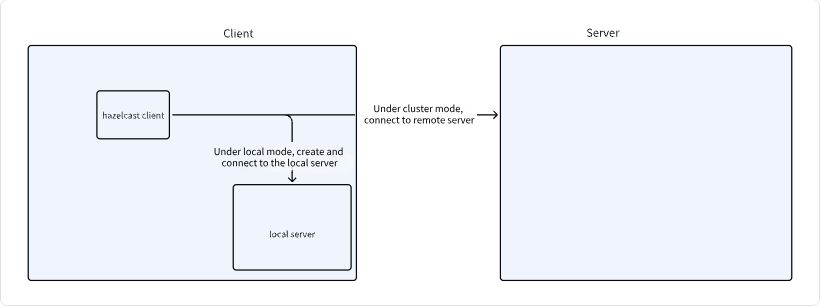
The task type is determined based on the user’s parameters, and different methods are called accordingly.
For example, if the task is to cancel a job, the corresponding cancel task method is invoked. We won’t analyze each task type here; instead, we’ll focus on the task submission process. Once we understand the submission process, the rest will be easier to comprehend.
if (clientCommandArgs.isListJob()) { String jobStatus = engineClient.getJobClient().listJobStatus(true); System.out.println(jobStatus); } else if (clientCommandArgs.isGetRunningJobMetrics()) { String runningJobMetrics = engineClient.getJobClient().getRunningJobMetrics(); System.out.println(runningJobMetrics); } else if (null != clientCommandArgs.getJobId()) { String jobState = engineClient .getJobClient() .getJobDetailStatus(Long.parseLong(clientCommandArgs.getJobId())); System.out.println(jobState); } else if (null != clientCommandArgs.getCancelJobId()) { engineClient .getJobClient() .cancelJob(Long.parseLong(clientCommandArgs.getCancelJobId())); } else if (null != clientCommandArgs.getMetricsJobId()) { String jobMetrics = engineClient .getJobClient() .getJobMetrics(Long.parseLong(clientCommandArgs.getMetricsJobId())); System.out.println(jobMetrics); } else if (null != clientCommandArgs.getSavePointJobId()) { engineClient .getJobClient() .savePointJob(Long.parseLong(clientCommandArgs.getSavePointJobId())); } else { // Omitted third section of the code } Submit the Task to the Cluster // Get the path of the configuration file and check if the file exists Path configFile = FileUtils.getConfigPath(clientCommandArgs); checkConfigExist(configFile); JobConfig jobConfig = new JobConfig(); // Depending on whether the task is a restart from a savepoint or a new task, different methods are called to construct the ClientJobExecutionEnvironment object ClientJobExecutionEnvironment jobExecutionEnv; jobConfig.setName(clientCommandArgs.getJobName()); if (null != clientCommandArgs.getRestoreJobId()) { jobExecutionEnv = engineClient.restoreExecutionContext( configFile.toString(), clientCommandArgs.getVariables(), jobConfig, seaTunnelConfig, Long.parseLong(clientCommandArgs.getRestoreJobId())); } else { jobExecutionEnv = engineClient.createExecutionContext( configFile.toString(), clientCommandArgs.getVariables(), jobConfig, seaTunnelConfig, clientCommandArgs.getCustomJobId() != null ? Long.parseLong(clientCommandArgs.getCustomJobId()) : null); } // Get job start time startTime = LocalDateTime.now(); // Create job proxy // Submit the task ClientJobProxy clientJobProxy = jobExecutionEnv.execute(); // Check if it's an asynchronous submission; if so, exit directly without checking the status if (clientCommandArgs.isAsync()) { if (clientCommandArgs.getMasterType().equals(MasterType.LOCAL)) { log.warn("The job is running in local mode, cannot use async mode."); } else { return; } } // Register cancelJob hook // Add a hook method to cancel the submitted job when the command line exits after the task is submitted Runtime.getRuntime() .addShutdownHook( new Thread( () -> { CompletableFutureNext, let’s take a look at the initialization and the execute method of the jobExecutionEnv class.
public ClientJobExecutionEnvironment( JobConfig jobConfig, String jobFilePath, ListThe initialization of this class is straightforward, consisting mainly of variable assignments without any other initialization operations.
Next, let’s look at the execute method.
public ClientJobProxy execute() throws ExecutionException, InterruptedException { LogicalDag logicalDag = getLogicalDag(); log.info( "jarUrls are: [{}]", jarUrls.stream().map(URL::getPath).collect(Collectors.joining(", "))); JobImmutableInformation jobImmutableInformation = new JobImmutableInformation( Long.parseLong(jobConfig.getJobContext().getJobId()), jobConfig.getName(), isStartWithSavePoint, seaTunnelHazelcastClient.getSerializationService().toData(logicalDag), jobConfig, new ArrayList<>(jarUrls), new ArrayList<>(connectorJarIdentifiers)); return jobClient.createJobProxy(jobImmutableInformation); }In this method, getLogicalDag is first called to generate a logical plan. Then, JobImmutableInformation is constructed and passed to jobClient. We will look at the later steps first, and then examine how the logical plan is generated.
public ClientJobProxy createJobProxy(@NonNull JobImmutableInformation jobImmutableInformation) { return new ClientJobProxy(hazelcastClient, jobImmutableInformation); } public ClientJobProxy( @NonNull SeaTunnelHazelcastClient seaTunnelHazelcastClient, @NonNull JobImmutableInformation jobImmutableInformation) { this.seaTunnelHazelcastClient = seaTunnelHazelcastClient; this.jobId = jobImmutableInformation.getJobId(); submitJob(jobImmutableInformation); } private void submitJob(JobImmutableInformation jobImmutableInformation) { LOGGER.info( String.format( "Start submit job, job id: %s, with plugin jar %s", jobImmutableInformation.getJobId(), jobImmutableInformation.getPluginJarsUrls())); ClientMessage request = SeaTunnelSubmitJobCodec.encodeRequest( jobImmutableInformation.getJobId(), seaTunnelHazelcastClient .getSerializationService() .toData(jobImmutableInformation), jobImmutableInformation.isStartWithSavePoint()); PassiveCompletableFutureIn the provided code, after generating the JobImmutableInformation, this information is converted into a ClientMessage(SeaTunnelSubmitJobCodec) and then sent to the Master node, which is the master node in the Hazelcast server. After submission, the process returns to the task status detection steps mentioned above.
The message sending uses Hazelcast methods, and we don't need to focus on its implementation here.
The Logical PlanThe next chapter will revisit the server side to review the processing logic upon receiving the task submission from the client. For now, let’s go back and see how the logical plan is generated on the client side.
LogicalDag logicalDag = getLogicalDag();First, let’s examine the structure of LogicalDag.
@Getter private JobConfig jobConfig; private final SetThis class contains several variables, with two key classes: LogicalEdge and LogicalVertex, which are used to build the DAG through the relationships between tasks.
The LogicalEdge class contains simple variables, representing the connection between two points.
/** The input vertex connected to this edge. */ private LogicalVertex inputVertex; /** The target vertex connected to this edge. */ private LogicalVertex targetVertex; private Long inputVertexId; private Long targetVertexId;The LogicalVertex class has the following variables, including the current vertex ID, required parallelism, and the Action interface, which may be implemented by SourceAction, SinkAction, TransformAction, etc.
private Long vertexId; private Action action; /** Number of subtasks to split this task into at runtime. */ private int parallelism;Now, let’s look at the getLogicalDag method.
public LogicalDag getLogicalDag() { // ImmutablePairIn this method, the .parse(null) method is first called. This method returns an immutable pair where the first value is a List
When calling the parse(null) method, parsing occurs as follows:
public ImmutablePairLet’s take a look at the parseSource method:
public Tuple2In the new version, the Source instance is created through a factory:
public staticOn the client side, the Source instance is created using SPI to load the Source’s Factory, ensuring that the client can also connect to the Source/Sink to avoid network issues.
TransformsNext, let’s look at how transforms are created:
public void parseTransforms( List transformConfigs, ClassLoader classLoader, LinkedHashMapAfter reviewing the logic for sources and transforms, the logic if sinks is quite straightforward:
public ListNext, let’s look at the createSinkActionmethod:
private SinkAction createSinkAction( CatalogTable catalogTable, SetHaving reviewed the Source/Transform/Sink logic, let’s return to where the logic is invoked.
ListThe parseSink method returns all created Sink Actions, and each Action maintains upstream Actions. Therefore, we can find related Transform Actions and Source Actions through the final Sink Action.
Ultimately, getUsedFactoryUrls identifies all dependent JARs in this chain and returns a pair of results.
The Logical PlanNext, let’s look at how the logical plan is generated.
public LogicalDag getLogicalDag() { // Initialize with all SinkActions we generated ImmutablePairHaving reviewed how to configure the parameters, let’s now see how the logical plan is generated:
// Initialize with all SinkAction we generated protected LogicalDagGenerator getLogicalDagGenerator() { return new LogicalDagGenerator(actions, jobConfig, idGenerator, isStartWithSavePoint); } public LogicalDag generate() { // Generate node information based on actions actions.forEach(this::createLogicalVertex); // Create edges SetCreating Logical Plan Nodes:
private void createLogicalVertex(Action action) { // Get the ID of the current action, and return if it already exists in the map final Long logicalVertexId = action.getId(); if (logicalVertexMap.containsKey(logicalVertexId)) { return; } // Loop through upstream dependencies and create them // The storage structure of the map is as follows: // The current node's ID is the key // The value is a list storing the IDs of downstream nodes that use this node action.getUpstream() .forEach( inputAction -> { createLogicalVertex(inputAction); inputVerticesMap .computeIfAbsent( inputAction.getId(), id -> new LinkedHashSet<>()) .add(logicalVertexId); }); // Finally, create information for the current node final LogicalVertex logicalVertex = new LogicalVertex(logicalVertexId, action, action.getParallelism()); // Note that there are two maps here // One is inputVerticesMap and the other is logicalVertexMap // inputVerticesMap stores the relationships between nodes // logicalVertexMap stores the relationship between node IDs and nodes logicalVertexMap.put(logicalVertexId, logicalVertex); } private Set\
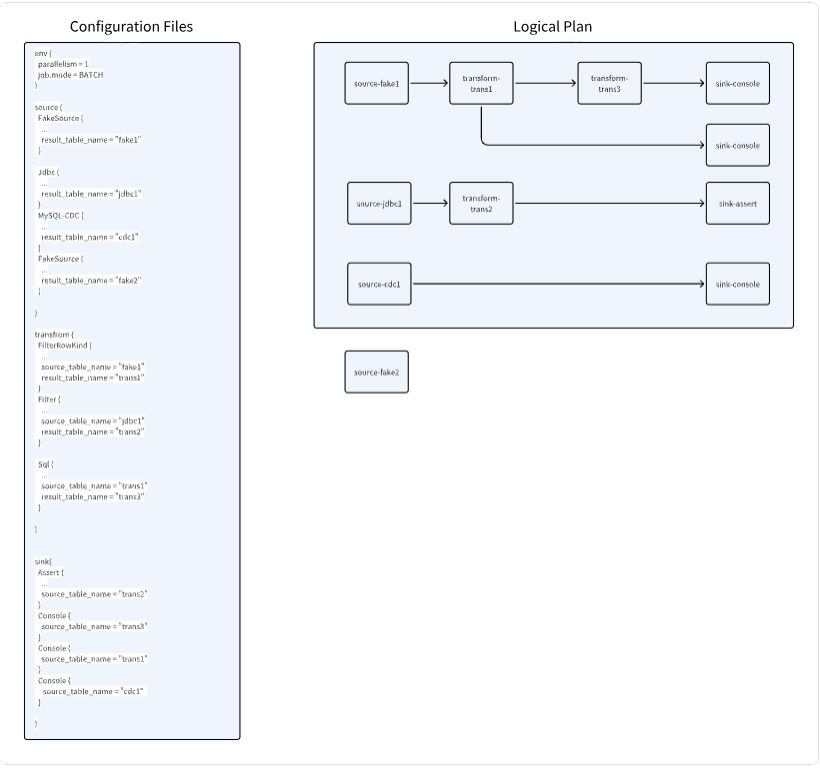
\ In the above configuration, the logical plan graph is generated based on upstream and downstream relationships. Nodes like Fake2, which have no downstream tasks, are excluded from the logical plan.
SummaryWe have now reviewed the task submission process on the client side.
Here’s a summary:
- Execution Mode Determination: First, the execution mode is determined. In Local mode, a Server node is created on the local machine.
- Hazelcast Connection: A Hazelcast node is created on the current node, connecting either to the Hazelcast cluster or the locally started node.
- Task Type Evaluation: The type of task being executed is determined, and different methods are called accordingly.
- For task submission, for example, the configuration file is parsed and the logical plan is generated. During logical plan generation, Source/Transform/Sinkinstances are created on the submitting machine. SaveMode functions may also be executed, such as creating tables, rebuilding tables, or deleting data (when client-side execution is enabled).
- Logical Plan Encoding and Communication: Once the logical plan is parsed, the information is encoded and sent to the Server's Master node using Hazelcast’s cluster communication functionality.
- Task Status Checking: After sending, based on the configuration, the program decides whether to exit or continue monitoring the task status.
- Add Hook Configuration: A Hook configuration is added to cancel the submitted task when the client exits.
That’s all about this article!
\