and the distribution of digital products.
Smarter AI Code Completion with Memory-Efficient Techniques
:::info Authors:
(1) Ben Athiwaratkun, AWS AI Labs;
(2) Sujan Kumar Gonugondla, AWS AI Labs;
(3) Sanjay Krishna Gouda, AWS AI Labs;
(4) Haifeng Qian, AWS AI Labs;
(5) Sanjay Krishna Gouda, AWS AI Labs;
(6) Hantian Ding, AWS AI Labs;
(7) Qing Sun, AWS AI Labs;
(8) Jun Wang, AWS AI Labs;
(9) Jiacheng Guo, AWS AI Labs;
(10 Liangfu Chen, AWS AI Labs;
(11) Parminder Bhatia, GE HealthCare (work done at AWS);
(12) Ramesh Nallapati, Amazon AGI (work done at AWS);
(13) Sudipta Sengupta, AWS AI Labs;
(14) Bing Xiang, Goldman Sachs (work done at AWS).
:::
Table of Links3.1. Notation and 3.2. Language Model Inference
3.3. Multi-Query, Multi-Head and the Generalized Multi-Query Attention
4. Context-Aware Bifurcated Attention and 4.1. Motivation
4.2. Formulation and 4.3. Memory IO Complexity
5.1. Comparing Capabilities of Multi-Head, Multi-Query, and Multi-Group Attention
5.2. Latencies of Capabilities-Equivalent Models
\ A. FAQs
D. Multi-Group Attention Family
E. Context-Aware Bifurcated Attention
F. Applications: Additional Results
G. Compatibility with Speculative Decoding and Fast Decoding techniques
\
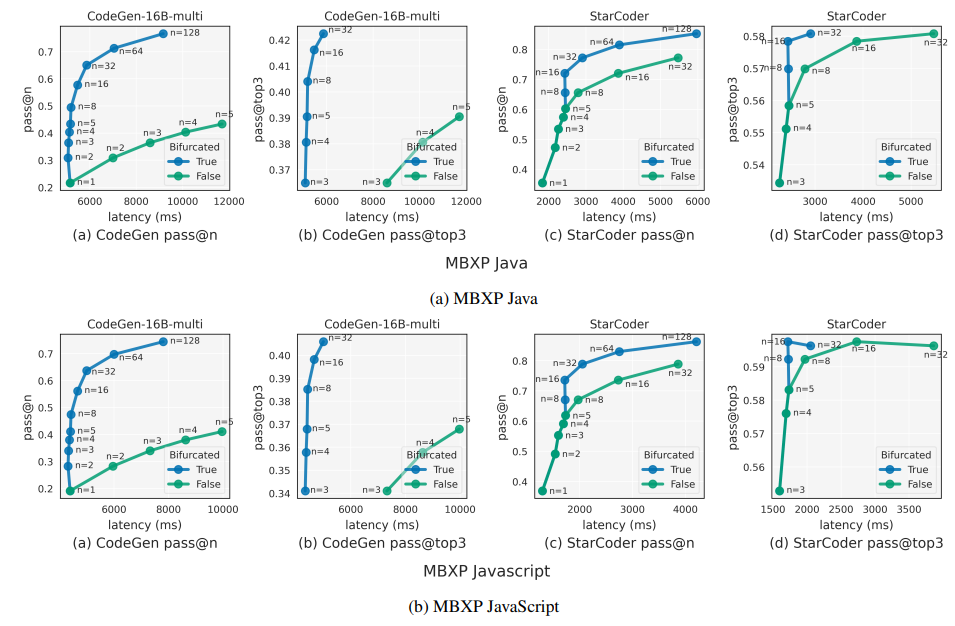
F. Applications: Additional ResultsWe demonstrate additional results to the evaluation in Section 5.3 on MBXP-Java and MBXP-Javascript, in addition to the Python results. We replace CodeGen-16B-mono with CodeGen-16B-multi for the evaluation on Java and JavaScript and use the same StarCoder model. From Figure 10, we observe similar trends as in Python (Figure 8), which furthers demonstrates the wide applicability of of bifurcated attention in improving accuracy under latency-constrained scenarios.
G. Compatibility with Speculative Decoding and Fast Decoding techniquesUnlike standard auto-regressive decoding, fast decoding techniques such as Speculative decoding(Chen et al., 2023; Leviathan et al., 2022), Medusa (Cai et al., 2024), Lookahead (Fu et al., 2023), and Eagle (Li et al., 2024) attempt to decode multiple tokens at each step. This reduces I/O bandwidth requirements because model parameters and KV cache are fetched only once per step and can be amortized across all generated tokens.
\ The fundamental principle behind these techniques is to first draft (or guess) a set of tokens (denoted as ng) and then validate their accuracy by parallelly decoding with the model. After each step, up to a tokens (where a ≤ ng) may be accepted as valid, allowing for memory usage amortization across these accepted tokens. This approach is successful because decoding is primarily constrained by memory I/O.
\ The benefits of bifurcated attention are orthogonal to those of speculative sampling, leading to further memory I/O improvements. This can be observed by extrapolating per-step memory I/O costs from Section E.2 with ng raplacing n. Since m >> ng continues to hold, the advantages of bifurcated attention persist even when combined with speculative decoding.
\
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\