and the distribution of digital products.
Reducing Memory Overhead in AI Models
:::info Authors:
(1) Ben Athiwaratkun, AWS AI Labs;
(2) Sujan Kumar Gonugondla, AWS AI Labs;
(3) Sanjay Krishna Gouda, AWS AI Labs;
(4) Haifeng Qian, AWS AI Labs;
(5) Sanjay Krishna Gouda, AWS AI Labs;
(6) Hantian Ding, AWS AI Labs;
(7) Qing Sun, AWS AI Labs;
(8) Jun Wang, AWS AI Labs;
(9) Jiacheng Guo, AWS AI Labs;
(10 Liangfu Chen, AWS AI Labs;
(11) Parminder Bhatia, GE HealthCare (work done at AWS);
(12) Ramesh Nallapati, Amazon AGI (work done at AWS);
(13) Sudipta Sengupta, AWS AI Labs;
(14) Bing Xiang, Goldman Sachs (work done at AWS).
:::
Table of Links3.1. Notation and 3.2. Language Model Inference
3.3. Multi-Query, Multi-Head and the Generalized Multi-Query Attention
4. Context-Aware Bifurcated Attention and 4.1. Motivation
4.2. Formulation and 4.3. Memory IO Complexity
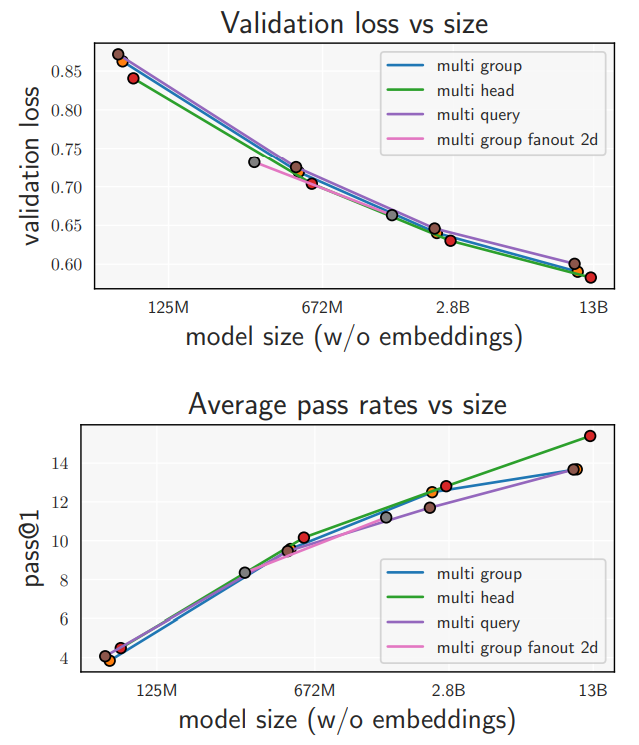
5.1. Comparing Capabilities of Multi-Head, Multi-Query, and Multi-Group Attention
5.2. Latencies of Capabilities-Equivalent Models
\ A. FAQs
D. Multi-Group Attention Family
E. Context-Aware Bifurcated Attention
F. Applications: Additional Results
G. Compatibility with Speculative Decoding and Fast Decoding techniques
E. Context-Aware Bifurcated Attention E.1. ProofHere, we outline the proof that the proposed bifurcated attention in Equation 3 and 4 recovers the same attention as the operations in 1 and 2 for the case of single-context batch sampling. We use the fact that the KV part corresponding to context length, all the batch indices correspond to the tensors.
\

Overall, the memory I/O complexity changes from
\ • Original memory I/O cost: bhnk + bgmk + bhnm (for ⟨q, K⟩) + bhnm + bgmk + bnd (for ⟨w, V ⟩)
\
\ • Bifurcated attention memory I/O cost: bhnk + gmck + bgmdk + bhnm (for ⟨q, K⟩) + bhnm + gmck + bgmdk + bnd (for ⟨w, V ⟩)
\ There is an associated memory IO to write the ⟨w, Vc⟩ and ⟨w, Vd⟩ output twice. However, it is typically very small (bnd) compared to the IO of KV cache component bgmk since m >> n = 1.
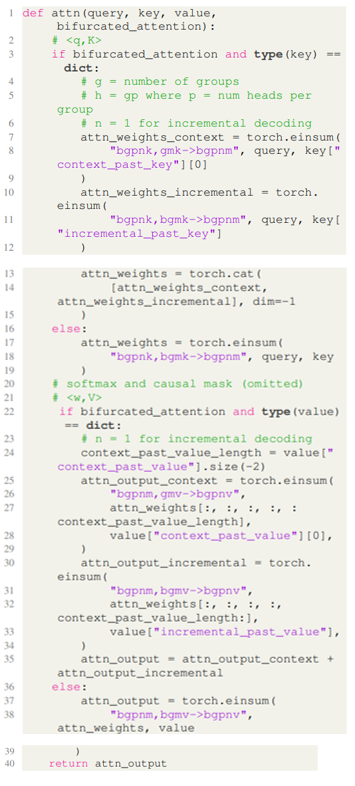
E.3. Implementation of Bifurcated AttentionDespite the dramatic gain in inference efficiency of the bifurcated attention, we demonstrate the simplicity of our implementation involving 20 lines of code using Pytorch (Paszke et al., 2019).
\
\

\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\