and the distribution of digital products.
RAG Revisited
RAG. RAG. RAG.
\ In the race to implement artificial intelligence in business processes and products, there’s been a troubling trend: an obsession with Retrieval-Augmented Generation (RAG). While RAG—a method that blends large language models (LLMs) with external knowledge retrieval—has undeniably opened up new avenues for interacting with knowledge, too many practitioners are struggling with it.
\ It’s time we reframe the conversation around AI implementation, acknowledge the pitfalls of over-reliance on RAG, and explore alternative approaches that may be more suitable, cost-effective, and elegant.
The RAG Mania: Overkill for Many Use CasesRAG has become the go-to technique for many AI engineers who want to improve the accuracy of language models by providing external context. The premise is simple enough: by uploading vast amounts of text into vector stores, these AI systems can look up relevant documents, retrieve the data, and combine it with the language model’s generative abilities to produce more precise answers.
\ However, the enthusiasm for RAG has led to an explosion of implementations that overestimate its usefulness. It’s not uncommon to see engineers dumping millions of documents into vector stores, inflating cloud storage and processing costs without understanding if the use case even necessitates such complexity. Many fail to consider whether a simpler solution could suffice or if RAG is even necessary for their specific problem.
The Pitfalls of Naive RAG ImplementationsWhat’s worse, most engineers approach RAG implementation with a naive mindset, overlooking the long-term costs and maintenance burdens. They believe that uploading every piece of text into a vector store will somehow make the AI smarter. But more often than not, this practice does the opposite. With vector stores brimming with redundant and unnecessary documents, LLMs are overwhelmed with retrieving data that doesn’t add value. This results in slower response times, higher costs, and less effective solutions.
\
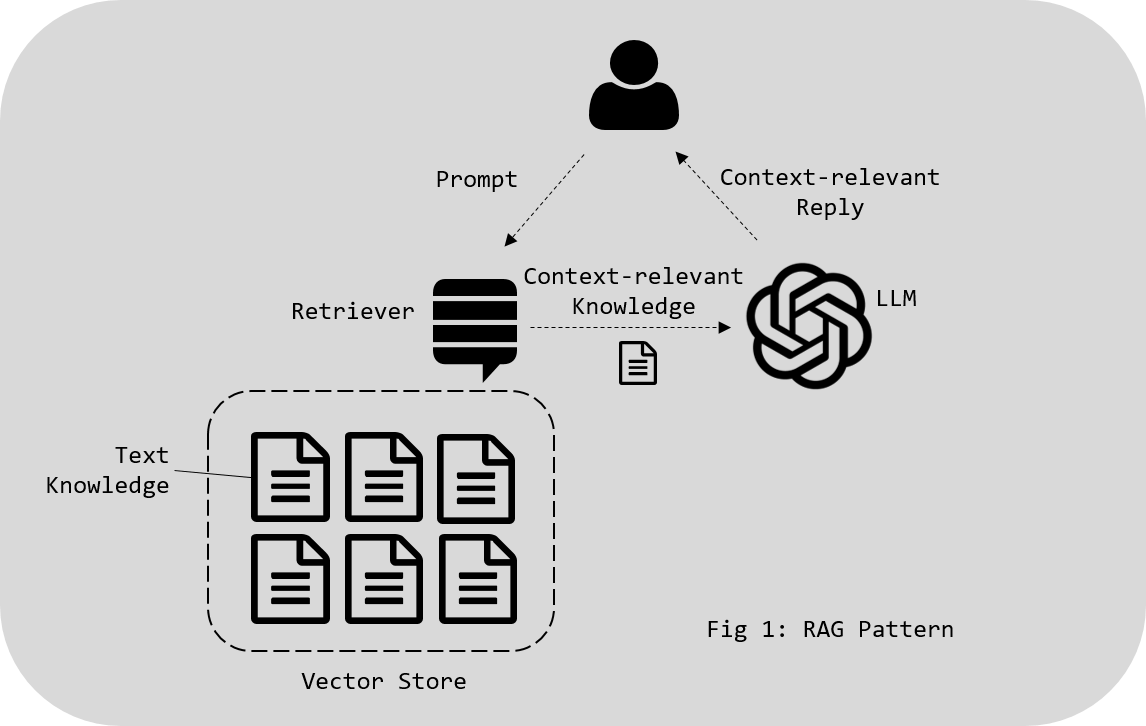
RAG works best when it’s used to augment precise and relevant knowledge, not when it’s employed as a catch-all for any document dump available. Overengineering through RAG also leads to underutilization of other key AI capabilities and an overblown focus on retrieval when many problems could be solved with simpler logic and structure.
Not Every Problem Needs RAGHere’s the truth: Not all use cases require a RAG setup. If the task is narrow and well-defined—like responding to FAQs, customer support queries, or engaging in structured dialogue—a simple lookup table or knowledge graph may suffice. There’s no need to incur the overhead of running a massive vector store and a multi-million parameter model when the solution can be built using a rule-based system or even an agent framework.
\ The zeal to use RAG stems from the idea that more data equals better performance. But in many cases, quality trumps quantity. A fine-tuned model with targeted knowledge, or even a knowledge-aware chatbot with rule-based capabilities, can perform better without ever touching a RAG pipeline. The decision to implement RAG should be dictated by the complexity of the task, not by its popularity among AI enthusiasts.
The Case for Small Agents With Narrow KnowledgeThe alternative to bloated RAG systems is often more elegant and effective: small, specialized agents with limited but precise knowledge. These agents, when used in tandem, can outperform a single large model burdened by terabytes of text. Each agent can be designed to handle specific parts of a workflow or respond to certain kinds of queries, allowing for modular and flexible AI systems. This not only reduces costs but also makes the entire system easier to maintain and scale.
\
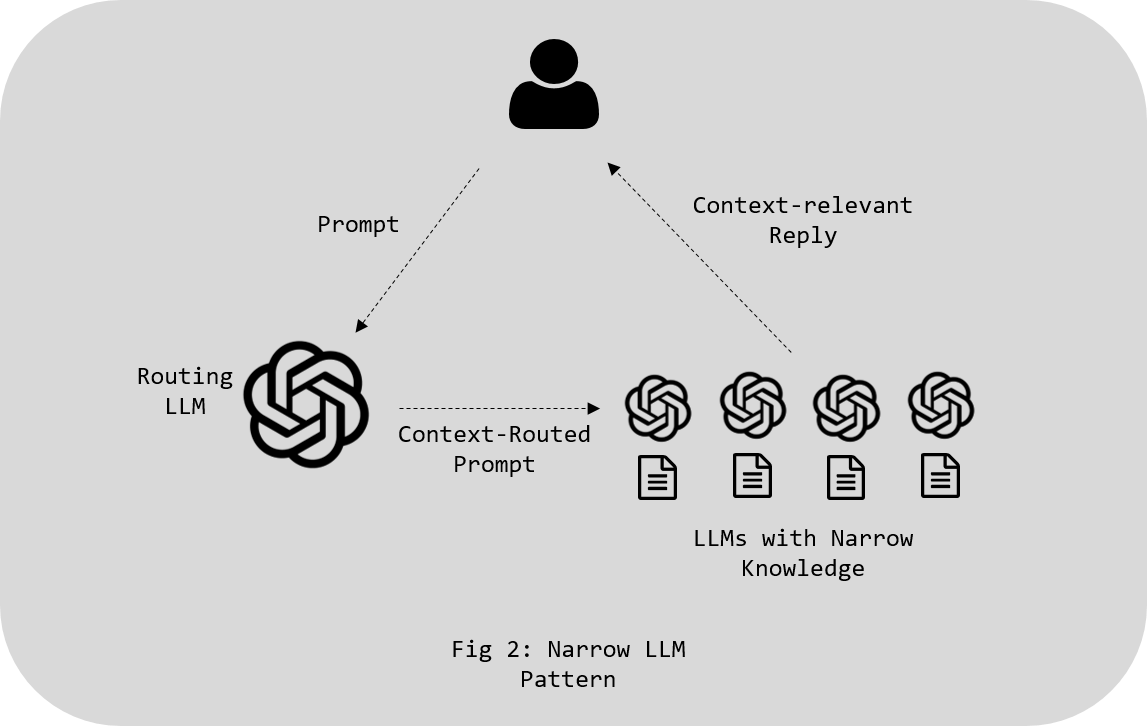
\ Imagine a scenario where one agent is responsible for scheduling, another for summarization, and a third for performing web searches. Each of these agents can work together, leveraging only the knowledge they need, without the overhead of a monolithic system. By deploying many small models or logic-based agents, businesses can get more precise and faster outputs while significantly cutting down on processing and storage costs.
Overusing LLMs: When Simple Logic Will DoFinally, there’s the overuse of LLMs in scenarios where simple logic would do. LLMs are remarkably good at understanding and generating natural language, but that doesn’t mean they should replace all forms of automation. Many tasks—like data validation, form filling, or structured report generation—can be done faster and more reliably with basic scripts, rule engines, or deterministic systems.
\ A prime example is using an LLM for an arithmetic task or a sorting problem. This is inefficient and unnecessary. Not only does it waste computational resources, but it also increases the likelihood of errors in cases where a simple function or algorithm would be more accurate. The eagerness to implement LLMs for everything has turned into an “LLM hammer looking for nails” syndrome. This misuse leads to inflated expectations and an eventual disillusionment when the models don’t perform as expected in tasks they weren’t designed to handle.
Rethinking AI EngineeringIt’s time to rethink AI engineering and move beyond the fads. RAG has its place in the toolkit, but it’s not a panacea. The future lies in deploying the right models for the right tasks—sometimes that means RAG, but often it doesn’t. With a nuanced understanding of AI capabilities, engineers can design systems that are more effective, efficient, and easier to maintain.
\ ==About Me: 20+ year veteran combining data, AI, risk management, strategy, and education. 4x hackathon winner and social impact from data advocate. Currently working to jumpstart the AI workforce in the Philippines. Learn more about me here: https://docligot.com==