and the distribution of digital products.
The Power of Market Disruption: How to Detect Fraud With Graph Data
In previous articles, I’ve mentioned my short career in the music industry. Let me tell a quick story about something really cool that happened while playing keyboards on a new artist project in 1986.
\ Emerging from the solo section of the first song on the album, sound engineer Alan Johnson had a cool idea that would catch the listener’s attention. The idea focused on a backward sound effect where Alan flipped the audio reels. (Here’s a YouTube video to better explain.)
\ The sound engineer captured the listener’s attention by disrupting the standard structure of the song. At 19 years old, this was my first experience of someone disrupting the norm.
\ Now, almost 40 years later, I’ve seen first-hand how market disruptors are the key to paving innovation across many aspects of life.
My Current CareerNot long after Marqeta was listed as #7 on CNBC’s Disruptor 50 list in 2021, I wrote about their APIs in “Leveraging Marqeta to Build a Payment Service in Spring Boot”. Marqeta provides the tools companies require to offer a new version of a payment card or wallet to meet customer needs.
\ Following the success of my short series of articles, I was asked if I ever considered a career with Marqeta. Ultimately, the reason I chose Marqeta was driven by the effects of being a market disruptor in the FinTech industry.
\ In the 2+ years since I started this chapter of my career, I’ve experienced the engineering excitement of being laser-focused on delighting our customers worldwide.
\ Seeing the value Marqeta provided to the FinTech industry, I began exploring other potential market disruptors that are on the rise.
About PuppyGraphI’ve experimented with graph models and often became frustrated by the dependency on extract, transform, and load (ETL) middleware. The thought of ETL takes me back to that time in my career when I spent a great deal of time building an ETL layer to address reporting needs. The consequence of ETL ultimately placed important features onto the team’s sprint backlog while introducing long-term tech debt.
\ The other challenge I’ve run into is where the source data lives outside a graph database. Like the challenges with ETL adoption, adding a graph database is far from a trivial effort — especially in enterprises with complex infrastructures that introduce risk by adding a new data stack.
\ That’s why I wanted to check out PuppyGraph, a solution that allows you to query traditional data sources (such as relational databases or data lakes) like a unified graph model. PuppyGraph removes the need for ETL integrations and is designed without duplicating existing data. For those organizations without a graph database, PuppyGraph is a graph query engine — allowing non-graph data sources to be queried natively.
\ The architecture diagram may look something like this — leveraging a single copy of data that can be queried using both SQL and graph:
\
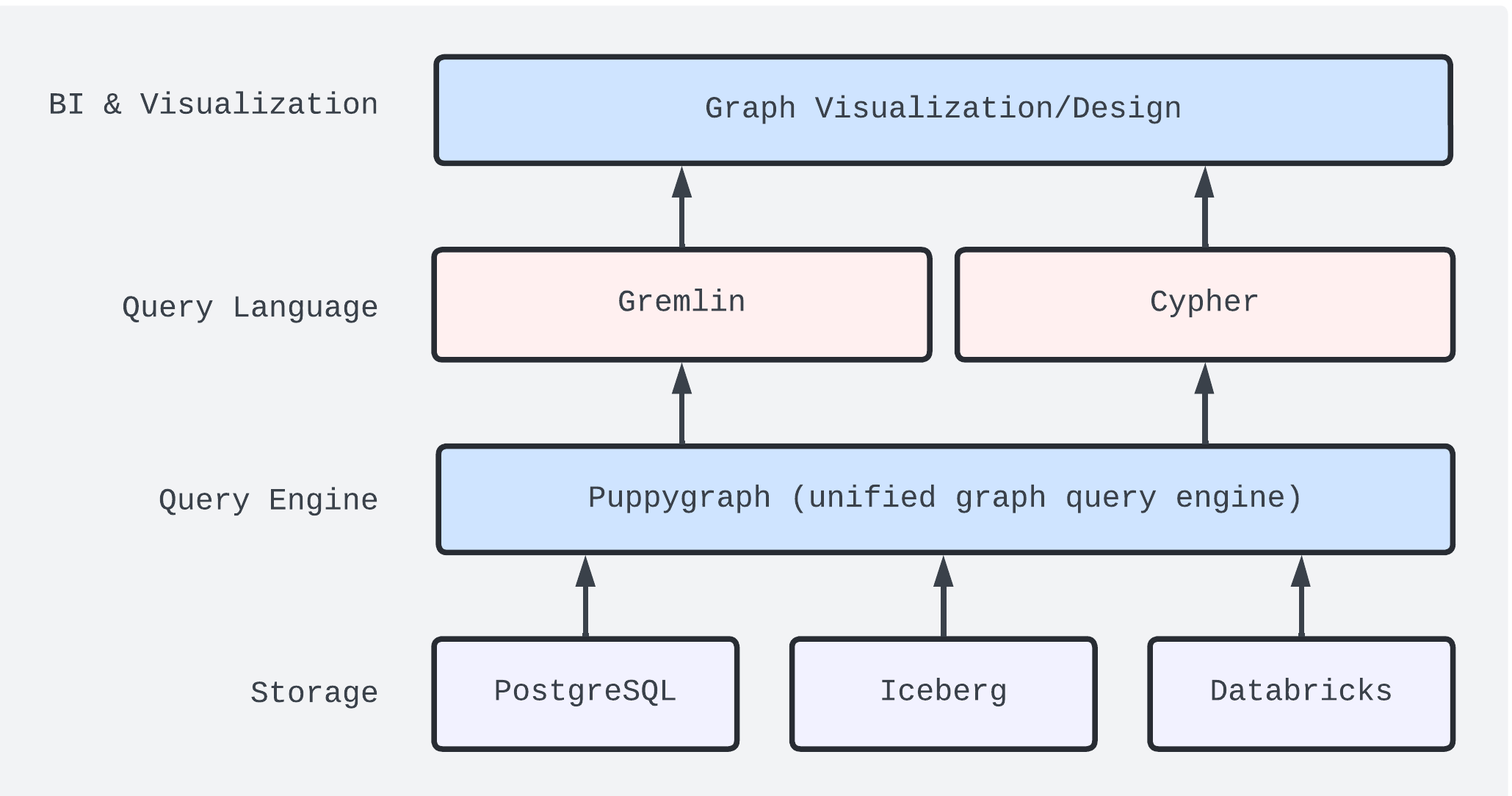
For those new to graph database query languages:
\
- Gremlin is a generic graph traversal (and computation) language often used for graph path traversal, graph pattern matching, merging, ranking, and splitting.
\
- Cypher is a query language used for graph pattern matching.
\ Based on this information, I think PuppyGraph has a shot at truly being a market disruptor. Let’s consider a use case to see why.
A Fresh Look at Fraud DetectionSince I’m in the FinTech space, I wanted to focus on a peer-to-peer (P2P) payment platform. Specifically, I wanted to look at fraud detection. So, I started with the use case and dataset from a blog post on fraud detection from Neo4j.
\ For this use case, we’ll investigate a real-world data sample (anonymized) from a P2P payment platform. We’ll identify fraud patterns, resolve high-risk fraud communities, and apply recommendation methods.
\ To accomplish this, we can use the following tech stack:
\
- PuppyGraph Developer Edition, which is free
- Apache Iceberg, with its open table format for analytic datasets
- Docker Personal subscription, which is free
\ As noted above, we’ll do this without using any ETL tooling or duplicating any data.
\ A local PuppyGraph instance can be started in Docker using the following command:
\
docker run -p 8081:8081 -p 8182:8182 -p 7687:7687 -d --name puppy --rm --pull=always puppygraph/puppygraph:stable\ Our unified graph model will focus on the following attributes:
\
- User
- Credit cards
- Devices
- IP Addresses
\ Based on the P2P platform sample data, we can illustrate our graph schema like this:
\
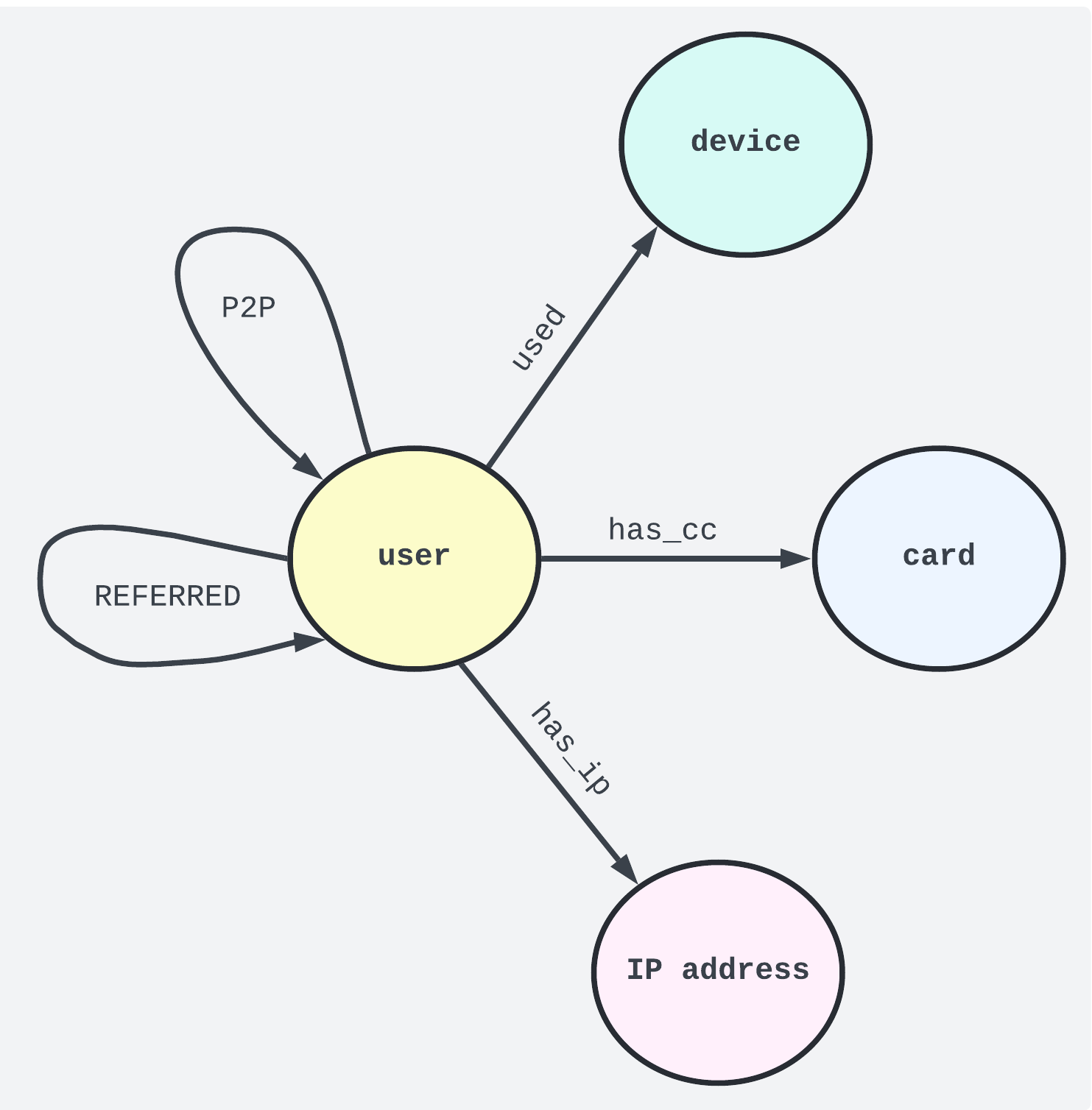
Each user account has a unique 128-bit identifier, while the other nodes — representing unique credit cards, devices, and IP addresses — have been assigned random UUIDs. The used, has_cc, and has_ip identifier nodes have been added to easily reference the child collections. Additionally, the REFERRED and P2P relationships account for users who refer to or send payments to other users.
\ Within the PuppyGraph UI, the schema appears as shown below:
\
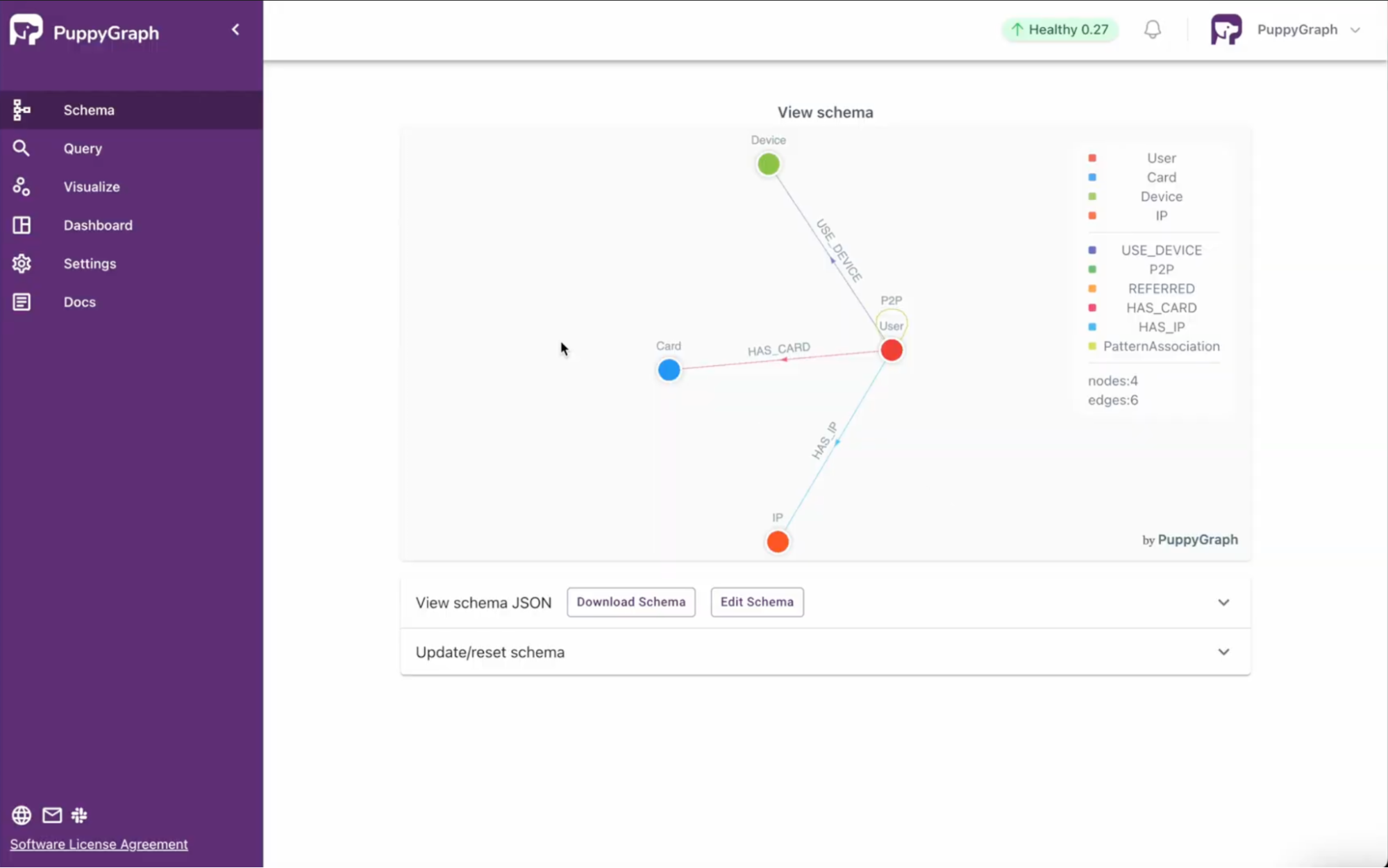
\ Based upon the design of the data, each user node has an indicator variable for money transfer fraud (named MoneyTransferFraud) that uses a value of 1 for known fraud and 0 otherwise. As a result, roughly 0.7 percent of user accounts are flagged for fraud.
\ Looking at the source data within PuppyGraph, we can see that there are 789k nodes and nearly 1.8 million edges — making a strong use case for being able to identify more fraud scenarios using a graph-based approach.
\
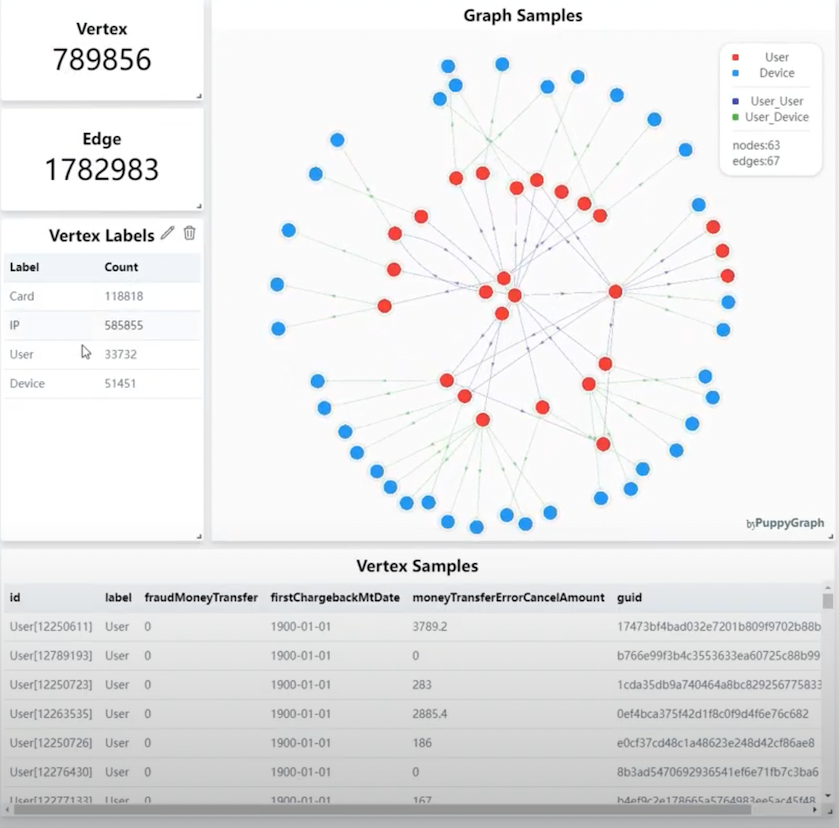
The 0.7 percent level of fraud seems quite low. My goal was to leverage PuppyGraph to perform additional analysis without using ETL or implementing a complex schema redesign.
\ Let’s first use a simple Gremlin query to provide a radial layout of users flagged with fraud:
\
g.V().hasLabel('User').has('fraudMoneyTransfer', 1)\ Executing the query in PuppyGraph provides the following response:
\
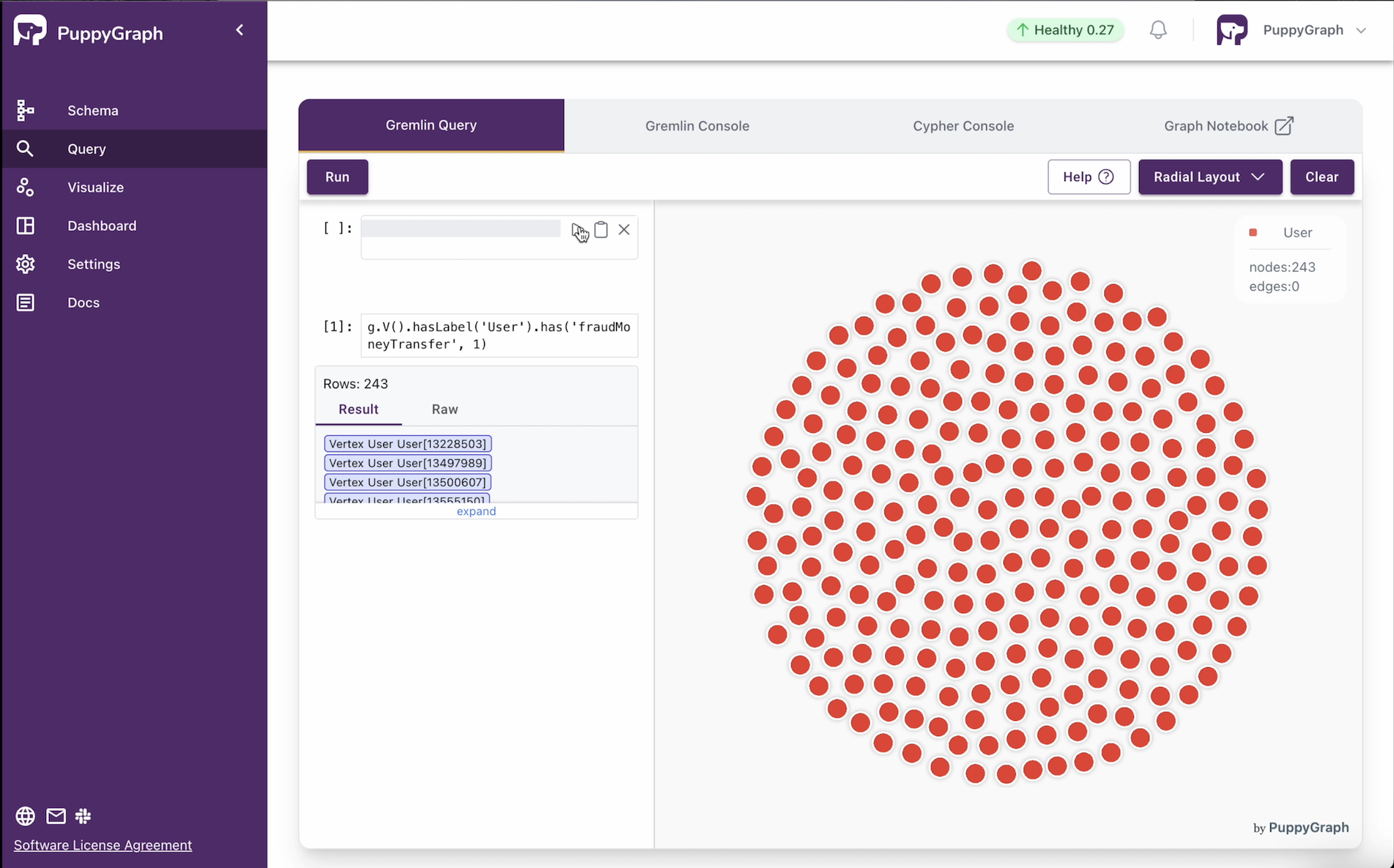
As expected, 243 confirmed users with fraud-based transactions were returned. In the PuppyGraph UI, we can pick a random user to validate the details:
\

Now that we’ve been able to validate that the data is showing up as expected in PuppyGraph, we can dive deeper, analyzing the data further.
\ Here’s the idea we want to explore: existing fraud users might be linked to the fraudulent activities of users who were not identified as fraud risks in the original efforts. For this article, we’ll identify similarities between user accounts using just the card, device, and IP address nodes that connect to at least one fraud risk account.
\ Let’s create some queries for this use case. The first query enables the identifier filtering that connects to fraud risk accounts:
\
gds.run_cypher(''' MATCH(f:FraudRiskUser)-[:HAS_CC|HAS_IP|USED]->(n) WITH DISTINCT n MATCH(n)<-[r:HAS_CC|HAS_IP|USED]-(u) SET n:FraudSharedId SET r.inverseDegreeWeight = 1.0/(n.degree-1.0) RETURN count(DISTINCT n) ''') count(DISTINCT n) 18182\ The second and third queries project the graph and write relationships back to the database with a score to represent similarity strength between user node pairs:
\
, _ = gds.graph.project( 'similarity-projection', ['User', 'FraudSharedId'], ['HAS_CC', 'USED', 'HAS_IP'], relationshipProperties=['inverseDegreeWeight'] ) _ = gds.nodeSimilarity.write( g, writeRelationshipType='SIMILAR_IDS', writeProperty='score', similarityCutoff=0.01, relationshipWeightProperty='inverseDegreeWeight' ) g.drop()\ Using a similarity cutoff of 0.01 in the third query is intended to rule out weak associations and keep the similarities relevant. From there, we can run a Cypher query to rank users by how similar they are to known fraud risk communities:
\
gds.run_cypher(''' MATCH (f:FraudRiskUser) WITH f.wccId AS componentId, count(*) AS numberOfUsers, collect(f) AS users UNWIND users AS f MATCH (f)-[s:SIMILAR_IDS]->(u:User) WHERE NOT u:FraudRiskUser AND numberOfUsers > 2 RETURN u.guid AS userId, sum(s.score) AS totalScore, collect(DISTINCT componentId) AS closeToCommunityIds ORDER BY totalScore DESC ''')\ Based on this approach, we find some user records to analyze.
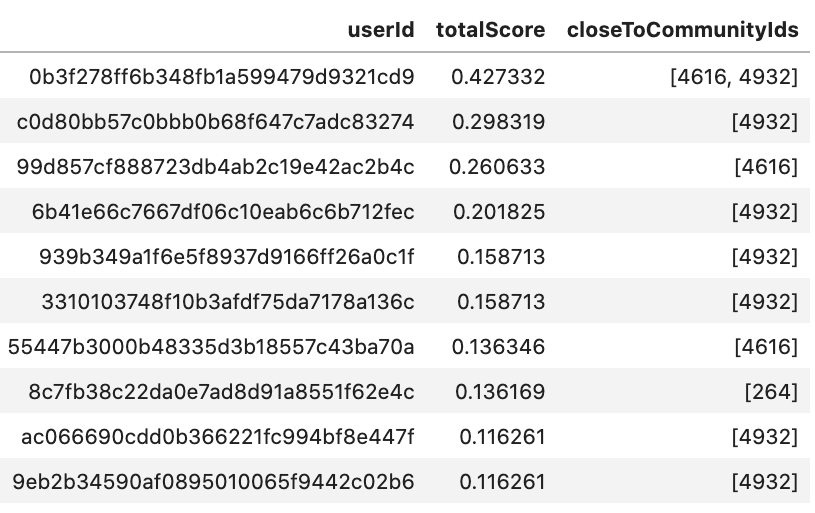
Let’s examine the first record (userId 0b3f278ff6b348fb1a599479d9321cd9) in PuppyGraph:
\
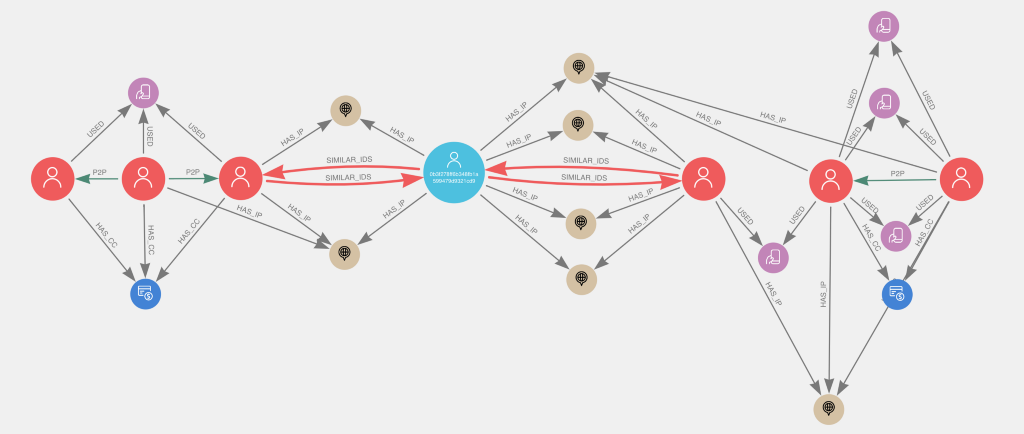
The most glaring aspect is how user nodes have relationships with each other. Notice how our user of interest (blue, in the center) is connected to two other users because of shared IP addresses. At first glance, those relationships could just be a coincidence. However, both of these users are connected to fraud risk communities. You can see that multiple users share the same devices and credit cards, and they also engage in P2P transactions with one another.
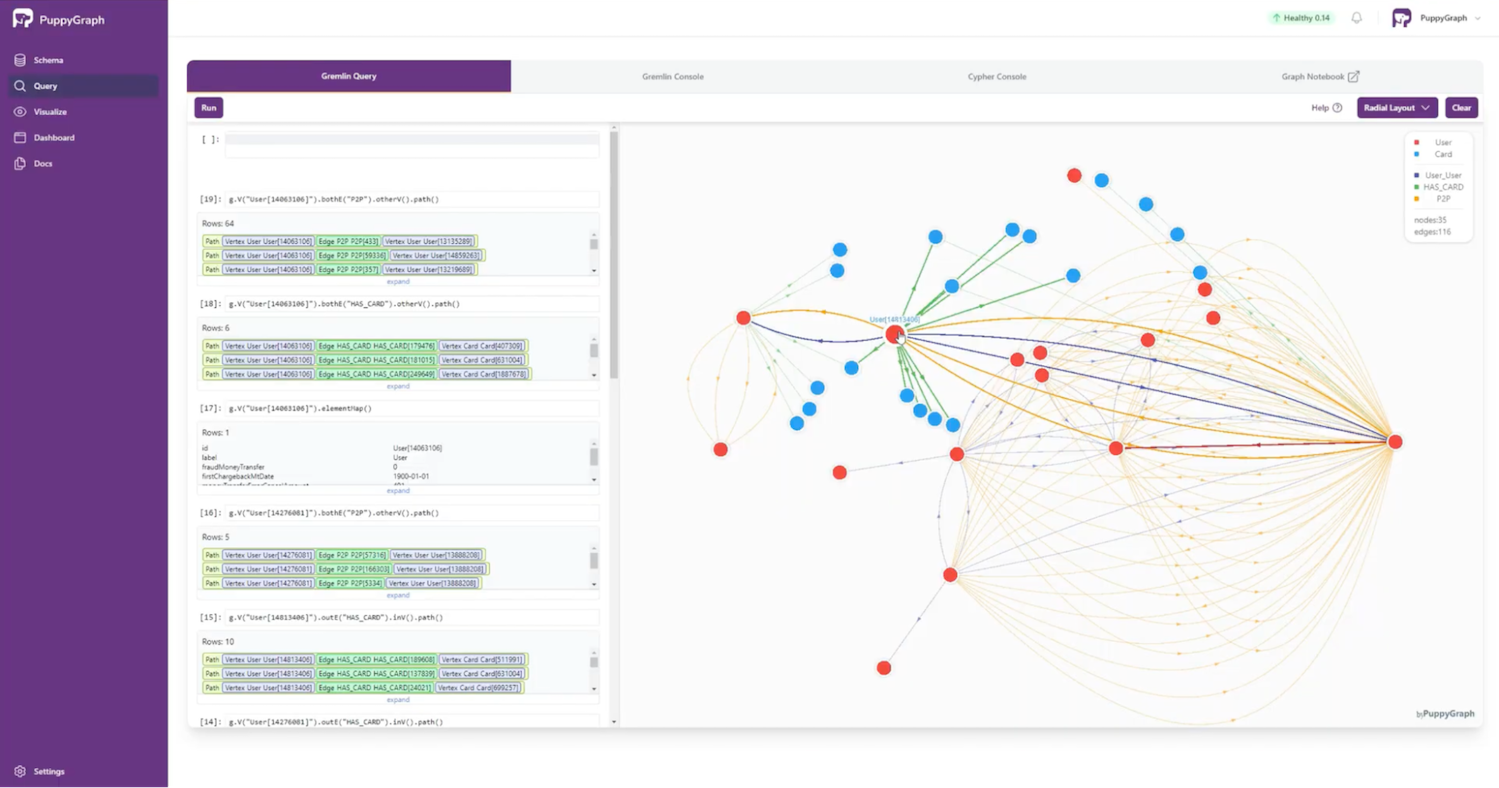
Our user of interest seems to act as a bridge between the two communities. What’s our conclusion? It’s not only likely that the user is part of both fraud communities; this user’s connection may indicate that the two communities are actually the same.
\ This was just a simple example, but it shows how we can use PuppyGraph to uncover additional instances of fraud just by looking for user relationships with existing users. We can implement additional explorations using community detection — for example, with the Louvain method — to locate similarities without needing an exact match.
\ The initial 0.7 percent fraud identification is likely far lower than the actual fraudulent users in this dataset. However, we can only determine that by seeing entity relationships through a graph model, something that we get here without the need for resource- and time-intensive ETL. It’s pretty impressive to get this much data insight using a tech stack that’s available at no initial cost.
ConclusionAt the start of this article, I noted two examples of disruption that paved the way for innovation:
\
- Alan Johnson’s work on that 1986 album project produced a song that captured the listener’s attention — a goal every artist wants to accomplish.
\
- Marqeta disrupted the FinTech industry by offering a collection of APIs and underlying tech to remove the pain of payment processing.
\ Market disruptors are key to paving innovation and avoiding stagnation. Based on my initial exploration, I think PuppyGraph will be a market disruptor:
\
With a modest tech stack — and no ETL or duplication of data — we had a graph-based data solution that identified a significant increase in impacted consumers over non-graph data solutions.
\
Our solution performed with low latency and has been designed to scale as needed.
\ Additionally, PuppyGraph allows for quickly switching schemas (which PuppyGraph refers to as instant schemas), though it wasn’t needed in this demo. I bring this up because it’s a use case that interests many potential users.
\ My readers may recall my personal mission statement, which I feel can apply to any IT professional:
\
“Focus your time on delivering features/functionality that extends the value of your intellectual property. Leverage frameworks, products, and services for everything else.” — J. Vester
\ PuppyGraph adheres to my mission statement by avoiding the tech debt and hard costs associated with an ETL layer and the data duplication across the enterprise. The platform allows teams to focus on their use cases, leveraging open-source solutions along the way.
\ Have a really great day!