and the distribution of digital products.
New Riemannian Networks Outperform Traditional Models in Action Recognition and Node Classification
\
Table of LinksProposed Approach
C. Formulation of MLR from the Perspective of Distances to Hyperplanes
H. Computation of Canonical Representation
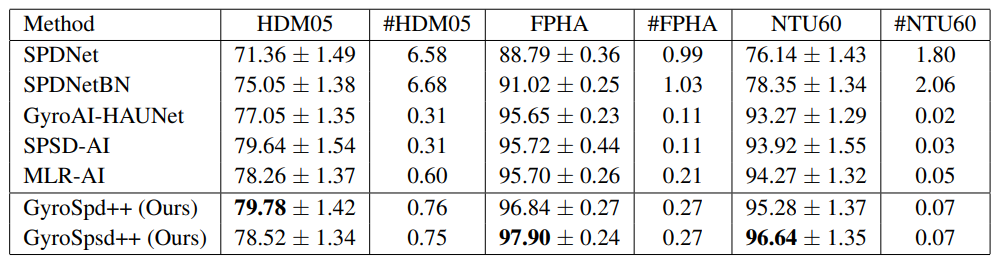
4 EXPERIMENTS 4.1 HUMAN ACTION RECOGNITIONWe use three datasets, i.e., HDM05 (Muller et al., 2007), FPHA (Garcia-Hernando et al., 2018), and ¨ NTU RBG+D 60 (NTU60) (Shahroudy et al., 2016). We compare our networks against the following state-of-the-art models: SPDNet (Huang & Gool, 2017)[1], SPDNetBN (Brooks et al., 2019)[2], SPSDAI (Nguyen, 2022a), GyroAI-HAUNet (Nguyen, 2022b), and MLR-AI (Nguyen & Yang, 2023).
\ 4.1.1 ABLATION STUDY
\ Convolutional layers in SPD neural networks Our network GyroSpd++ has a MLR layer stacked on top of a convolutional layer (see Fig. 1). The motivation for using a convolutional layer
\
\
\ is that it can extract global features from local ones (covariance matrices computed from joint coordinates within sub-sequences of an action sequence). We use Affine-Invariant metrics for the convolutional layer and Log-Euclidean metrics for the MLR layer. Results in Tab. 1 show that GyroSpd++ consistently outperforms the SPD baselines in terms of mean accuracy. Results of GyroSpd++ with different designs of Riemannian metrics for its layers are given in Appendix D.4.1.
\ MLR in structure spaces We build GyroSpsd++ by replacing the MLR layer of GyroSpd++ with a MLR layer proposed in Section 3.3. Results of GyroSpsd++ are given in Tab. 1. Except SPSDAI, GyroSpsd++ outperforms the other baselines on HDM05 dataset in terms of mean accuracy. Furthermore, GyroSpsd++ outperforms GyroSpd++ and all the baselines on FPHA and NTU60 datasets in terms of mean accuracy. These results show that MLR is effective when being designed in structure spaces from a gyrovector space perspective.
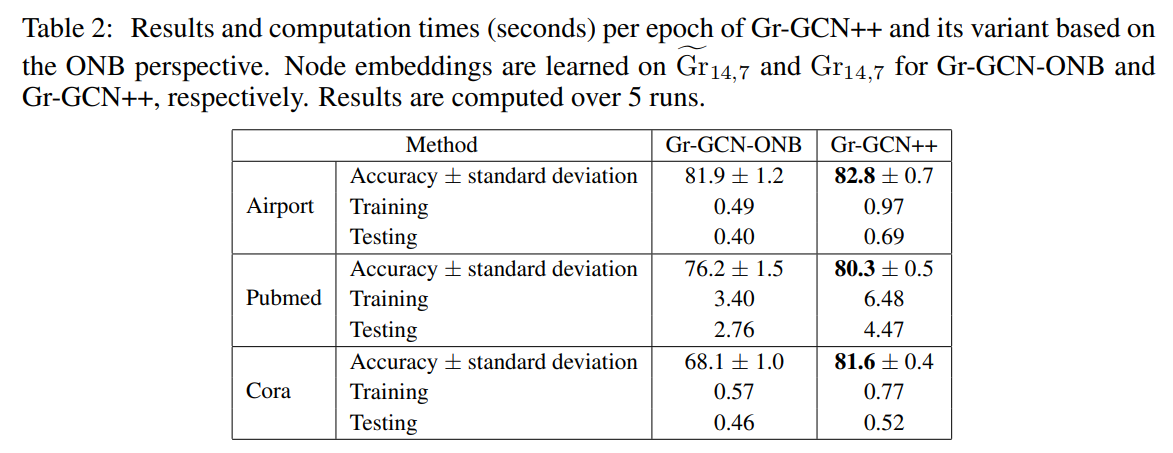
4.2 NODE CLASSIFICATIONWe use three datasets, i.e., Airport (Zhang & Chen, 2018), Pubmed (Namata et al., 2012a), and Cora (Sen et al., 2008), each of them contains a single graph with thousands of labeled nodes. We compare our network Gr-GCN++ (see Fig. 1) against its variant Gr-GCN-ONB (see Appendix E.2.4) based on the ONB perspective. Results are shown in Tab. 2. Both networks give the best performance for n = 14 and p = 7. It can be seen that Gr-GCN++ outperforms Gr-GCN-ONB in all cases. The performance gaps are significant on Pubmed and Cora datasets.
\
:::info Authors:
(1) Xuan Son Nguyen, ETIS, UMR 8051, CY Cergy Paris University, ENSEA, CNRS, France ([email protected]);
(2) Shuo Yang, ETIS, UMR 8051, CY Cergy Paris University, ENSEA, CNRS, France ([email protected]);
(3) Aymeric Histace, ETIS, UMR 8051, CY Cergy Paris University, ENSEA, CNRS, France ([email protected]).
:::
:::info This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.
:::
[1] https://github.com/zhiwu-huang/SPDNet.
\ [2] https://papers.nips.cc/paper/2019/hash/6e69ebbfad976d4637bb4b39de261bf7-Abstract. html.