and the distribution of digital products.
Micro-Conditioning Strategies for Superior Image Generation in SDXL
:::info Authors:
(1) Dustin Podell, Stability AI, Applied Research;
(2) Zion English, Stability AI, Applied Research;
(3) Kyle Lacey, Stability AI, Applied Research;
(4) Andreas Blattmann, Stability AI, Applied Research;
(5) Tim Dockhorn, Stability AI, Applied Research;
(6) Jonas Müller, Stability AI, Applied Research;
(7) Joe Penna, Stability AI, Applied Research;
(8) Robin Rombach, Stability AI, Applied Research.
:::
Table of Links2.4 Improved Autoencoder and 2.5 Putting Everything Together
\ Appendix
D Comparison to the State of the Art
E Comparison to Midjourney v5.1
F On FID Assessment of Generative Text-Image Foundation Models
G Additional Comparison between Single- and Two-Stage SDXL pipeline
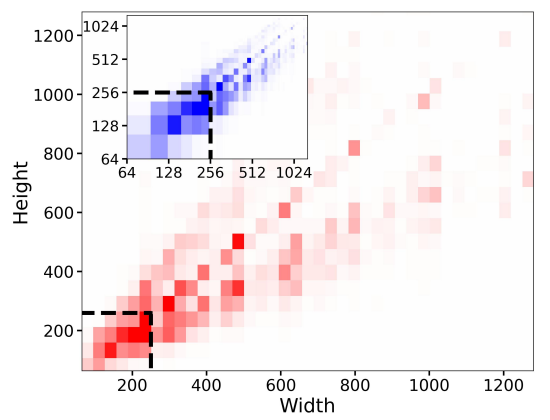
2.2 Micro-ConditioningConditioning the Model on Image Size A notorious shortcoming of the LDM paradigm [38] is the fact that training a model requires a minimal image size, due to its two-stage architecture. The two main approaches to tackle this problem are either to discard all training images below a certain minimal resolution (for example, Stable Diffusion 1.4/1.5 discarded all images with any size below 512 pixels), or, alternatively, upscale images that are too small. However, depending on the desired image resolution, the former method can lead to significant portions of the training data being discarded, what will likely lead to a loss in performance and hurt generalization. We visualize such effects in Fig. 2 for the dataset on which SDXL was pretrained. For this particular choice of data, discarding all samples below our pretraining resolution of 256 2 pixels would lead to a significant 39% of discarded data. The second method, on the other hand, usually introduces upscaling artifacts which may leak into the final model outputs, causing, for example, blurry samples.
\
\

\

\

\ Conditioning the Model on Cropping Parameters The first two rows of Fig. 4 illustrate a typical failure mode of previous SD models: Synthesized objects can be cropped, such as the cut-off head of the cat in the left examples for SD 1-5 and SD 2-1. An intuitive explanation for this behavior is the use of random cropping during training of the model: As collating a batch in DL frameworks such as
\
![Comparison of the output of SDXL with previous versions of Stable Diffusion. For each prompt, we show 3 random samples of the respective model for 50 steps of the DDIM sampler [46] and cfg-scale 8.0 [13]. Additional samples in Fig. 14.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-zxd3088.png)
\ PyTorch [32] requires tensors of the same size, a typical processing pipeline is to (i) resize an image such that the shortest size matches the desired target size, followed by (ii) randomly cropping the image along the longer axis. While random cropping is a natural form of data augmentation, it can leak into the generated samples, causing the malicious effects shown above.
\

\ While other methods like data bucketing [31] successfully tackle the same task, we still benefit from cropping-induced data augmentation, while making sure that it does not leak into the generation process - we actually use it to our advantage to gain more control over the image synthesis process. Furthermore, it is easy to implement and can be applied in an online fashion during training, without additional data preprocessing.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\