and the distribution of digital products.
Media Slant: Alternative County Matching of Newspapers and Filtering of the Article Snippets
Abstract and 1 Introduction 2. Data
3. Measuring Media Slant and 3.1. Text pre-processing and featurization
3.2. Classifying transcripts by TV source
3.3. Text similarity between newspapers and TV stations and 3.4. Topic model
4. Econometric Framework
4.1. Instrumental variables specification
4.2. Instrument first stage and validity
5. Results
6. Mechanisms and Heterogeneity
6.1. Local vs. national or international news content
6.2. Cable news media slant polarizes local newspapers
\ Online Appendices
A. Data Appendix
A.2. Alternative county matching of newspapers and A.3. Filtering of the article snippets
A.4. Included prime-time TV shows and A.5. Summary statistics
B. Methods Appendix, B.1. Text pre-processing and B.2. Bigrams most predictive for FNC or CNN/MSNBC
B.3. Human validation of NLP model
B.6. Topics from the newspaper-based LDA model
C. Results Appendix
C.1. First stage results and C.2. Instrument exogeneity
C.3. Placebo: Content similarity in 1995/96
C.8. Robustness: Historical circulation weights and C.9. Robustness: Relative circulation weights
C.12. Mechanisms: Language features and topics
C.13. Mechanisms: Descriptive Evidence on Demand Side
C.14. Mechanisms: Slant contagion and polarization
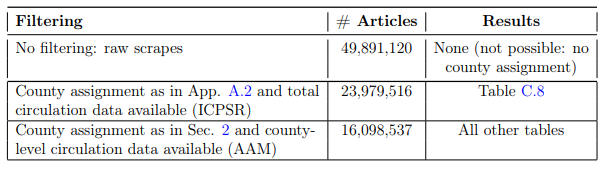
A.2. Alternative county matching of newspapersFor robustness, we also apply an alternative matching procedure that covers more newspapers but only uses total instead of county-specific circulation. First, we obtain the main county for each newspaper outlet based on the newspaper name and geographical information provided by NewsLibrary (e.g., The Call (Woonsocket, RI) or the Albany Democrat-Herald (OR)), the U.S. Newspaper Directory, or a manual web search. For the circulation, we use more broad-based but less granular data: we assign total circulation (as of 2004) according to the Inter-University Consortium for Political and Social Research (ICPSR) to this main county. Hence, each newspaper is only assigned to one county, where its total circulation is assumed to accrue. This matching approach produces a dataset of 682 unique outlets and 24 million article snippets. As Table C.8 shows, with the alternative matching, the coefficients are significant and three to four times larger than in the main Table 2.
A.3. Filtering of the article snippetsTable A.1 gives an overview of the number of articles collected and how we obtain the number of articles used in our main analyses and robustness checks.
\
\
:::info This paper is available on arxiv under CC 4.0 license.
:::
:::info Authors:
(1) Philine Widmer, ETH Zürich and [email protected];
(2) Sergio Galletta, ETH Zürich and [email protected];
(3) Elliott Ash, ETH Zürich and [email protected].
:::
\