and the distribution of digital products.
Linear Attention and Long Context Models
:::info Authors:
(1) Albert Gu, Machine Learning Department, Carnegie Mellon University;
(2)Tri Dao, Department of Computer Science, Princeton University [email protected], [email protected].
:::
Table of Links3 Selective State Space Models and 3.1 Motivation: Selection as a Means of Compression
3.2 Improving SSMs with Selection
3.3 Efficient Implementation of Selective SSMs
3.4 A Simplifed SSM Architecture
3.5 Properties of Selection Mechanisms
4 Empirical Evaluation and 4.1 Synthetic Tasks
4.4 Audio Modeling and Generation
4.5 Speed and Memory Benchmarks
6 Conclusion, Acknowledgments and References
A Discussion: Selection Mechanism
B Related Work and B.1 S4 Variants and Derivatives
B.4 Linear Attention and B.5 Long Context Models
D Hardware-aware Algorithm For Selective SSMs
E Experimental Details and Additional Results and E.1 Synthetic Tasks
B.4 Linear AttentionThe Linear Attention (LA) (Katharopoulos et al. 2020) framework is an important result popularizing kernel attention and showing how it relates to recurrent autoregressive models. Many variants have proposed alternative kernels and other modifications. Random Feature Attention (RFA) (H. Peng et al. 2021) chooses the kernel feature map to approximate softmax attention (i.e. the exp feature map) using the random Fourier feature approximation of Gaussian kernels (Rahimi and Recht 2007). Performer (Choromanski et al. 2021) finds an approximation to the exponential kernel involving only positive features, which also allows the softmax normalization term. TransNormer (Qin, Han, W. Sun, D. Li, et al. 2022) showed that the LA denominator term can be unstable and proposed replacing it with a LayerNorm. cosFormer (Qin, W. Sun, et al. 2022) augments RFA with a cosine reweighting mechanism that incorporates positional information to emphasize locality. Linear Randomized Attention (Zheng, C. Wang, and L. Kong 2022) generalize RFA from the perspective of importance sampling, and generalize it to provide better estimates of the full softmax kernel (rather than just the exp-transformed numerator).
\ Aside from kernel attention, many other variants of efficient attention exist; the survey Tay, Dehghani, Bahri, et al. (2022) offers an extensive categorization of many of these.
B.5 Long Context ModelsLong context has become a popular subject, and several recent models have claimed to scale to longer and longer sequences. However, these are often from a computational standpoint and have not been extensively validated. These include:

In contrast, we believe this work presents one of the first approaches to meaningfully demonstrate increasing performance with longer context.
\
C Mechanics of Selective SSMs\

\ The discretization step size is
\

\ where we observe that the parameter can be viewed as a learnable bias and folded into the linear projection. Now applying the zero-order hold (ZOH) discretization formulas:
\
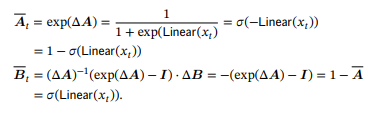
\ Thus the final discrete recurrence (2a) is
\
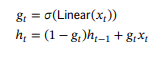
\ as desired.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\