and the distribution of digital products.
The Impact of Parameters on LLM Performance
:::info Authors:
(1) Wanyun Cui, Shanghai University of Finance and Economics, with equal contribution;
(2) Qianle Wang, Shanghai University of Finance and Economics, with equal contribution.
:::
Table of Links3 Quantifying the Impact of Parameters on Model Performance & 4. Unified Mixed-Precision Training
5 Prevalence of Parameter Heterogeneity in LLMs
6 Quantization Experiments and 6.1 Implementation Details
6.2 Effect of Base LLM Quantization
6.3 Effect of Chat LLM Quantization
6.4 Comparison of Parameter Selection Criteria, Conclusion, & References
\
3. Quantifying the Impact of Parameters on Model Performance
\
4. Unified Mixed-Precision TrainingThe insights gained from Figure 1 highlights the heterogeneity in model parameters. The cherry parameters, despite constituting less than 1% of the total parameter count, exert a substantial influence on the model. Indiscriminately quantizing these cherry parameters alongside the normal parameters may lead to a significant deterioration in model performance.
\ To mitigate the impact of cherry parameters on quantization, we propose to preserve their high-precision values during the quantization process. By maintaining the fidelity of these critical parameters, we ensure that the essential information they capture is not compromised.
\ Optimizing mixed-precision parameters in LLMs presents a unique challenge. The widely adopted GPTQ approach [8], which falls under the Post-Training Quantization (PTQ) framework [14], struggles to simultaneously optimize high-precision cherry parameters and low-precision normal parameters. This is because updating the cherry parameters during the PTQ process significantly affects the model, causing the optimal values of the normal parameters to vary. However, in the PTQ framework, once the parameters are quantized, they cannot be updated further. This limitation prevents the early-stage quantized parameters from reaching their optimal values. On the other hand, if we do not allow the updates of the cherry parameters during the PTQ process [17], the quantized model will lose the flexibility provided by these critical parameters.
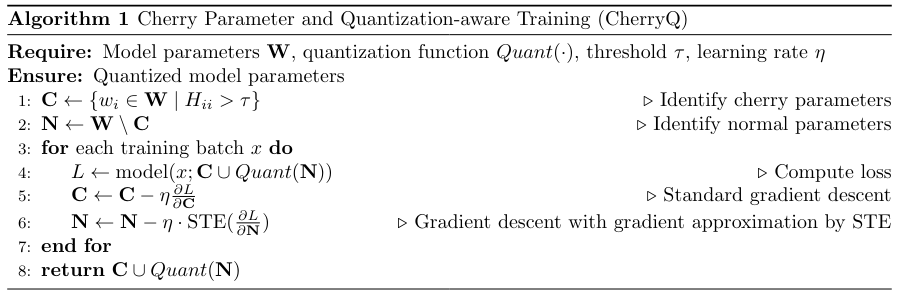
\ To address this challenge, we propose a novel approach that unifies the optimization of mixed-precision parameters. Our method leverages a QAT framework, which allows for the simultaneous optimization of both cherry parameters and normal parameters. During backpropagation, the high-precision cherry parameters are updated using standard gradient descent, while the low-precision normal parameters employ the Straight-Through Estimator (STE) trick [3] for low precision gradient descent. This unified backpropagation enables end-to-end optimization of both cherry parameters and normal parameters, enhancing the overall optimization effect. We show the quantization in Algorithm 1.
\
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\