and the distribution of digital products.
HyperHuman Sets New Benchmark for Realism and Pose Accuracy in Human Image Generation
:::info Authors:
(1) Xian Liu, Snap Inc., CUHK with Work done during an internship at Snap Inc.;
(2) Jian Ren, Snap Inc. with Corresponding author: [email protected];
(3) Aliaksandr Siarohin, Snap Inc.;
(4) Ivan Skorokhodov, Snap Inc.;
(5) Yanyu Li, Snap Inc.;
(6) Dahua Lin, CUHK;
(7) Xihui Liu, HKU;
(8) Ziwei Liu, NTU;
(9) Sergey Tulyakov, Snap Inc.
:::
Table of Links3 Our Approach and 3.1 Preliminaries and Problem Setting
3.2 Latent Structural Diffusion Model
A Appendix and A.1 Additional Quantitative Results
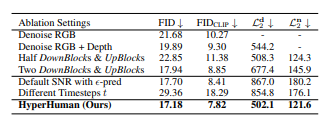
A.2 More Implementation Details and A.3 More Ablation Study Results
A.5 Impact of Random Seed and Model Robustness and A.6 Boarder Impact and Ethical Consideration
A.7 More Comparison Results and A.8 Additional Qualitative Results
5.1 MAIN RESULTSEvaluation Metrics. We adopt commonly-used metrics to make comprehensive comparisons from three perspectives: 1) Image Quality. FID, KID, and FIDCLIP are used to reflect quality and diversity. 2) Text-Image Alignment, where the CLIP similarity between text and image embeddings is reported. 3) Pose Accuracy. We use the state-of-the-art pose estimator to extract poses from synthetic images and compare with the input (GT) pose conditions. The Average Precision (AP) and Average Recall (AR) are adopted to evaluate the pose alignment. Note that due to the noisy pose estimation of in-the-wild COCO, we also use APclean and ARclean to only evaluate on the three most salient persons.
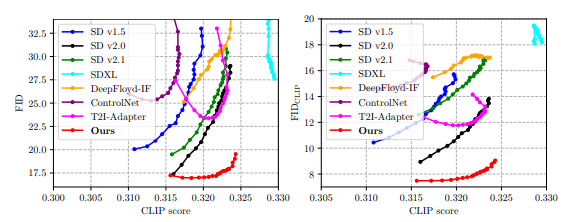
\ Quantitative Analysis. We report zero-shot evaluation results in Tab. 1. For all methods, we use the default CFG scale of 7.5, which well balances the quality and diversity with appealing results. Thanks to the structural awareness from expert branches, our proposed HyperHuman outperforms previous works by a clear margin, achieving the best results on image quality and pose accuracy metrics and ranks second on CLIP score. Note that SDXL (Podell et al., 2023) uses two text encoders with 3× larger UNet of more cross-attention layers, leading to superior text-image alignment. In spite of this, we still obtain an on-par CLIP score and surpass all the other baselines that have similar text encoder parameters. We also show the FID-CLIP and FIDCLIP-CLIP curves over multiple CFG scales in Fig. 3, where our model balances well between image quality and text-alignment, especially for the commonly-used CFG scales (bottom right). Please see Sec. A.1 for more quantitative results.
\
\
\

\ Qualitative Analysis. Fig. 1 shows example results (top) and comparisons with baselines (bottom). We can generate both photo-realistic images and stylistic rendering, showing better realism, quality, diversity, and controllability. A comprehensive user study is further conducted as shown in Tab. 3, where the users prefer HyperHuman to the general and controllable T2I models. Please refer to Appendix A.4, A.7, and A.8 for more user study details, visual comparisons, and qualitative results.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\