and the distribution of digital products.
HyperHuman Outperforms ControlNet, SDXL, and Others in Groundbreaking Image Generation Tests
:::info Authors:
(1) Xian Liu, Snap Inc., CUHK with Work done during an internship at Snap Inc.;
(2) Jian Ren, Snap Inc. with Corresponding author: [email protected];
(3) Aliaksandr Siarohin, Snap Inc.;
(4) Ivan Skorokhodov, Snap Inc.;
(5) Yanyu Li, Snap Inc.;
(6) Dahua Lin, CUHK;
(7) Xihui Liu, HKU;
(8) Ziwei Liu, NTU;
(9) Sergey Tulyakov, Snap Inc.
:::
Table of Links3 Our Approach and 3.1 Preliminaries and Problem Setting
3.2 Latent Structural Diffusion Model
A Appendix and A.1 Additional Quantitative Results
A.2 More Implementation Details and A.3 More Ablation Study Results
A.5 Impact of Random Seed and Model Robustness and A.6 Boarder Impact and Ethical Consideration
A.7 More Comparison Results and A.8 Additional Qualitative Results
5 EXPERIMENTSExperimental Settings. For the comprehensive evaluation, we divide our comparisons into two settings: 1) Quantitative analysis. All the methods are tested on the same benchmark, using the same prompt with DDIM Scheduler (Song et al., 2020a) for 50 denoising steps to generate the same resolution images of 512 × 512. 2) Qualitative analysis. We generate high-resolution 1024 × 1024 results for each model with the officially provided best configurations, such as the prompt engineering, noise scheduler, and classifier-free guidance (CFG) scale. Note that we use the RGB output of the first-stage Latent Structural Diffusion Model for numerical comparison, while the improved results from the second-stage Structure-Guided Refiner are merely utilized for visual comparison.
\ Datasets. We follow common practices in T2I generation (Yu et al., 2022a) and filter out a human subset from MS-COCO 2014 validation (Lin et al., 2014) for zero-shot evaluation. In particular, offthe-shelf human detector and pose estimator are used to obtain 8, 236 images with clearly-visible humans for evaluation. All the ground truth images are resized and center-cropped to 512 × 512. To guarantee fair comparisons, we train first-stage Latent Structural Diffusion on HumanVerse, which is a subset of public LAION-2B and COYO, to report quantitative metrics. In addition, an internal dataset is adopted to train second-stage Structure-Guided Refiner only for visually pleasing results.
\
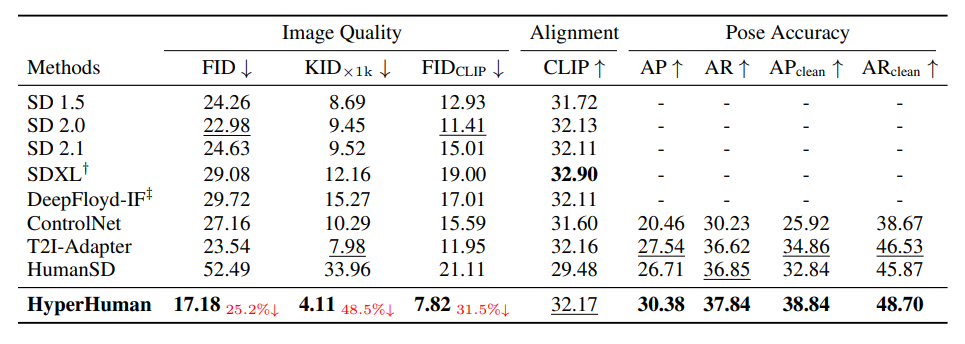
\ Comparison Methods. We compare with two categories of open-source SOTA works: 1) General T2I models, including SD (Rombach et al., 2022) (SD 1.x & 2.x), SDXL (Podell et al., 2023), and IF (DeepFloyd, 2023). 2) Controllable methods with pose condition. Notably, ControlNet (Zhang & Agrawala, 2023) and T2I-Adapter (Mou et al., 2023) can handle multiple structural signals like canny, depth, and normal, where we take their skeleton-conditioned variant for comparison. HumanSD (Ju et al., 2023b) is the most recent work that specializes in pose-guided human generation.
\ Implementation Details. We resize and random-crop the RGB, depth, and normal to the target resolution of each stage. To enforce the model with size and location awareness, the original image height/width and crop coordinates are embedded in a similar way to time embedding (Podell et al., 2023). Our code is developed based on diffusers (von Platen et al., 2022). 1) For the Latent Structural Diffusion, we fine-tune the whole UNet from the pretrained SD-2.0-base to v-prediction (Salimans & Ho, 2022) in 512 × 512 resolution. The DDIMScheduler with improved noise schedule is used for both training and sampling. We train on 128 80G NVIDIA A100 GPUs in a batch size of 2, 048 for one week. 2) For the Structure-Guided Refiner, we choose SDXL-1.0-base as the frozen backbone and fine-tune to ϵ-prediction for high-resolution synthesis of 1024 × 1024. We train on 256 80G NVIDIA A100 GPUs in a batch size of 2, 048 for one week. The overall framework is optimized with AdamW (Kingma & Ba, 2015) in 1e − 5 learning rate, and 0.01 weight decay.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\