and the distribution of digital products.
How to Save $70K Building a Knowledge Graph for RAG on 6M Wikipedia Pages
\ \ Using knowledge graphs to improve the results of retrieval-augmented generation (RAG) applications has become a hot topic. Most examples demonstrate how to build a knowledge graph using a relatively small number of documents. This might be because the typical approach – extracting fine-grained, entity-centric information – just doesn’t scale. Running each document through a model to extract the entities (nodes) and relationships (edges) takes too long (and costs too much) to run on large datasets.
\ We’ve argued that content-centric knowledge graphs – a vector-store allowing links between chunks – are an easier to use and more efficient approach. Here, we put that to the test. We load a subset of the Wikipedia articles from the 2wikimultihop dataset using both techniques and discuss what this means for loading the entire dataset. We demonstrate the results of some questions over the loaded data. We’ll also load the entire dataset – nearly 6 million documents – into a content-centric GraphVectorStore.
Entity-centric: LLMGraphTransformerLoading documents into an entity-centric graph store like Neo4j was done using LangChain’s LLMGraphTransformer. The code is based on LangChain's "How to construct knowledge graphs."
from langchain_core.documents import Document from langchain_experimental.graph_transformers import LLMGraphTransformer from langchain_openai import ChatOpenAI llm = ChatOpenAI(temperature=0, model_name="gpt-4-turbo") llm_transformer = LLMGraphTransformer(llm=llm) from time import perf_counter start = perf_counter() documents_to_load = [Document(page_content=line) for line in lines_to_load] graph_documents = llm_transformer.convert_to_graph_documents(documents_to_load) end = perf_counter() print(f"Loaded (but NOT written) {NUM_LINES_TO_LOAD} in {end - start:0.2f}s") Content-centric: GraphVectorStoreLoading the data into GraphVectorStore is roughly the same as loading it into a vector store. The only addition is that we compute metadata indicating how each page links to other pages.
\
import json from langchain_core.graph_vectorstores.links import METADATA_LINKS_KEY, Link def parse_document(line: str) -> Document: para = json.loads(line) id = para["id"] links = { Link.outgoing(kind="href", tag=id) for m in para["mentions"] if m["ref_ids"] is not None for id in m["ref_ids"] } links.add(Link.incoming(kind="href", tag=id)) return Document( id = id, page_content = " ".join(para["sentences"]), metadata = { "content_id": para["id"], METADATA_LINKS_KEY: list(links) }, )\ This is also a good example of how you can add your own links between nodes.
\
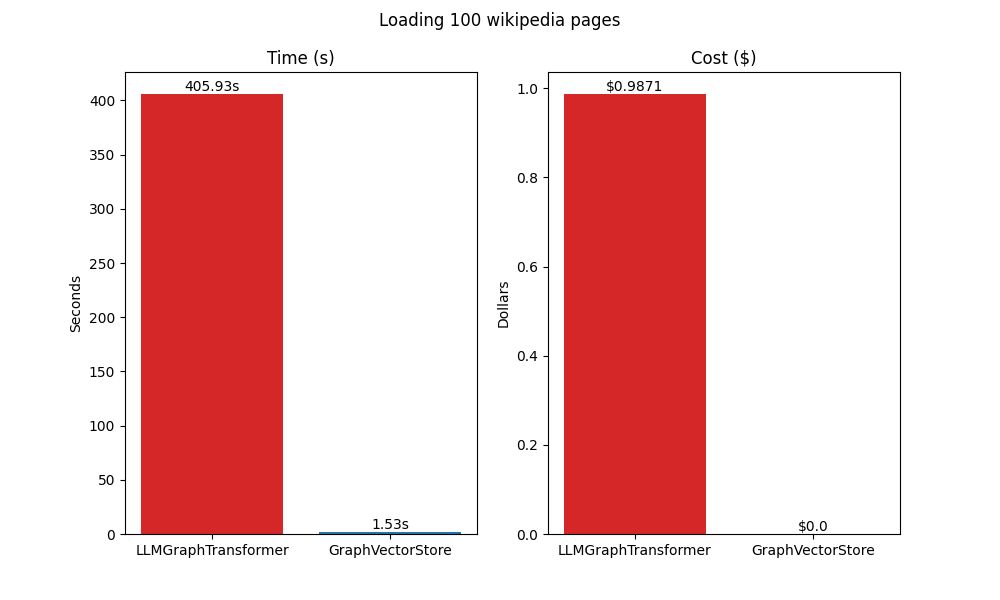
from langchain_openai import OpenAIEmbeddings from langchain_community.graph_vectorstores.cassandra import CassandraGraphVectorStore import cassio cassio.init(auto=True) TABLE_NAME = "wiki_load" store = CassandraGraphVectorStore( embedding = OpenAIEmbeddings(), node_table=TABLE_NAME, insert_timeout = 1000.0, ) from time import perf_counter start = perf_counter() from datasets.wikimultihop.load import parse_document kg_documents = [parse_document(line) for line in lines_to_load] store.add_documents(kg_documents) end = perf_counter() print(f"Loaded (and written) {NUM_LINES_TO_LOAD} in {end - start:0.2f}s") Loading benchmarksRunning at 100 rows, the entity-centric approach using GPT-4o took 405.93s to extract the GraphDocuments and 10.99s to write them to Neo4j, while the content-centric approach took 1.43s. Extrapolating, it would take 41 weeks to load all 5,989,847 pages using the entity-centric approach and about 24 hours using the content-centric approach. But thanks to parallelism, the content-centric approach runs in only 2.5 hours! Assuming the same parallelism benefits, it would still take over four weeks to load everything using the entity-centric approach. I didn’t try it since the estimated cost would be $58,700 — assuming everything worked the first time!
\
\
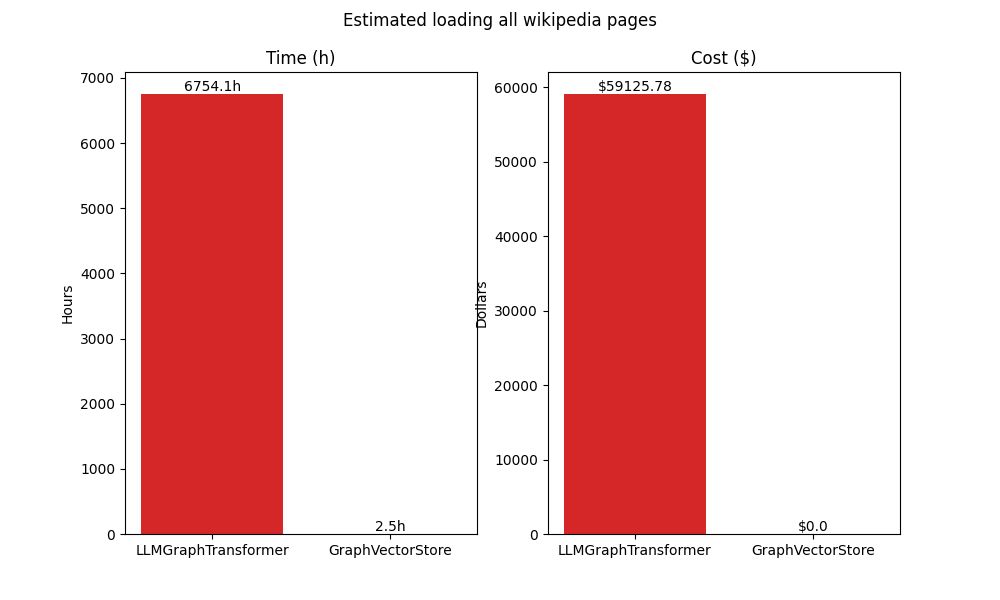
Bottom-line: the entity-centric approach of extracting knowledge graphs from content using an LLM was both time and cost prohibitive at scale. On the other hand, using GraphVectorStore was fast and inexpensive.
Example answersIn this section, a few questions, drawn from the subset of loaded documents, are asked to address the quality of answers.
\

Entity-centric used 7324 prompt tokens and cost $0.03 to produce basically useless answers, while content-centric used 450 prompt tokens and cost $0.002 to produce concise answers directly answering the questions.
\ It may be surprising that the fine-grained Neo4j graph returns useless answers. Looking at the logging from the chain, we see some of why this happens:
\
> Entering new GraphCypherQAChain chain... Generated Cypher: cypher MATCH (a:Album {id: 'The Circle'})-[:RELEASED_BY]->(r:Record_label) RETURN a.id, r.id Full Context: [{'a.id': 'The Circle', 'r.id': 'Restless'}] > Finished chain. {'query': "When was 'The Circle' released?", 'result': "I don't know the answer."}\ So, the fine-grained schema only returned information about the record label. It makes sense that the LLM wasn’t able to answer the question based on the retrieved information.
ConclusionExtracting fine-grained, entity-specific knowledge graphs is time- and cost-prohibitive at scale. When asked questions about the subset of data that was loaded, the additional granularity (and extra cost of loading the fine-grained graph) returned more tokens to include the prompt but generated useless answers!
\ GraphVectorStore takes a coarse-grained, content-centric approach that makes it fast and easy to build a knowledge graph. You can start with your existing code for populating a VectorStore using LangChain and add links (edges) between chunks to improve the retrieval process.
\ Graph RAG is a useful tool for enabling generative AI RAG applications to retrieve more deeply relevant contexts. But using a fine-grained, entity-centric approach does not scale to production needs. If you're looking to add knowledge graph capabilities to your RAG application, try GraphVectorStore.
\ By Ben Chambers, DataStax
\