and the distribution of digital products.
How Overfitting Affects Prompt Optimization
:::info Authors:
(1) Chengrun Yang, Google DeepMind and Equal contribution;
(2) Xuezhi Wang, Google DeepMind;
(3) Yifeng Lu, Google DeepMind;
(4) Hanxiao Liu, Google DeepMind;
(5) Quoc V. Le, Google DeepMind;
(6) Denny Zhou, Google DeepMind;
(7) Xinyun Chen, Google DeepMind and Equal contribution.
:::
Table of Links2 Opro: Llm as the Optimizer and 2.1 Desirables of Optimization by Llms
3 Motivating Example: Mathematical Optimization and 3.1 Linear Regression
3.2 Traveling Salesman Problem (TSP)
4 Application: Prompt Optimization and 4.1 Problem Setup
5 Prompt Optimization Experiments and 5.1 Evaluation Setup
5.4 Overfitting Analysis in Prompt Optimization and 5.5 Comparison with Evoprompt
7 Conclusion, Acknowledgments and References
B Prompting Formats for Scorer Llm
C Meta-Prompts and C.1 Meta-Prompt for Math Optimization
C.2 Meta-Prompt for Prompt Optimization
D Prompt Optimization Curves on the Remaining Bbh Tasks
E Prompt Optimization on Bbh Tasks – Tabulated Accuracies and Found Instructions
5.4 OVERFITTING ANALYSIS IN PROMPT OPTIMIZATIONFor simplicity, we do not set aside a validation set in our default setting of prompt optimization. We made this decision based on the experiments when a validation set is present.
\ Overfitting may result in training accuracy being much higher than the validation/test accuracy. It is difficult to avoid overfitting, but overfitting is less harmful when each candidate solution (natural language instruction in the prompt optimization context) overfits to a similar extent. In this case, a higher training accuracy solution still achieves a higher validation/test accuracy, and one can adopt solutions with the highest training accuracies as the final result. Figure 11 shows this is the case for OPRO in prompt optimization: when setting aside a validation set with the same size as the training set, the validation accuracy curves trend up and down alongside the training curves in both prompt optimization settings.
\ Of course, overfitting still occurs in the instructions found by our prompt optimization: in Table 7 and 10, our training accuracies are often 5%-20% higher than our test accuracies, despite that our test and overall accuracies are still mostly higher than human-written counterparts. Setting aside a larger training set and optimizing for fewer steps (early stopping) may help reduce overfitting.
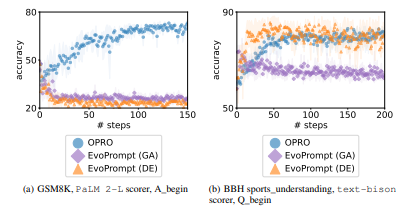
5.5 COMPARISON WITH EVOPROMPTSome concurrent works on prompt optimization propose meta-prompts that explicitly ask the LLM to perform mutation and crossovers of existing prompts (Fernando et al., 2023; Guo et al., 2023). In our evaluation, we compare our approach to the Genetic Algorithm (GA) and Differential Evolution (DE) versions of EvoPrompt (Guo et al., 2023). Specifically, in the GA meta-prompt, given two prompts, the meta-prompt instructs the LLM to cross over the two prompts and generates a new one, then mutates the newly generated prompt to produce the final prompt. DE extends the GA meta-prompt to include more detailed instructions, e.g., asking the LLM to identify different parts between the two given prompts before performing the mutation. This is in contrast with OPRO, which leverages the optimization trajectory including multiple past prompts, instead of only 2 previous prompts. Meanwhile, OPRO also provides the LLM with richer information to facilitate the understanding of the optimization problem, including exemplars and task accuracies of different prompts.
\ Figure 12 presents the results on GSM8K and BBH sports_understanding benchmarks, where we use gpt-3.5-turbo as the optimizer. On GSM8K, the initial instructions of all approaches are “Let’s 1 solve the problem.” and “Here is the answer.”, which are simple and generic. Again, we observe that OPRO performance steadily improves with more optimization steps. On the other hand, both versions of EvoPrompt even degrade the performance on GSM8K. The main reason is because EvoPrompt does not utilize exemplars for prompt optimization, thus it lacks the understanding of the task to optimize for. In this way, EvoPrompt relies on good-quality and task-specific initial prompts to optimize from.
\ Given this observation, we provide more task-specific initial instructions for experiments on BBH sports_understanding, which are “Solve the sports understanding problem.” and “Give me the answer to sports understanding.” In this case, EvoPrompt (DE) is able to find better prompts than the initial ones, but the optimization curve is less stable than OPRO. This indicates that leveraging the optimization trajectory helps the LLM to identify promising directions to improve existing prompts.
\
:::info This paper is available on arxiv under CC0 1.0 DEED license.
:::
\