and the distribution of digital products.
How Natural Program Improves Deductive Reasoning Across Diverse Datasets
:::info Authors:
(1) Zhan Ling, UC San Diego and equal contribution;
(2) Yunhao Fang, UC San Diego and equal contribution;
(3) Xuanlin Li, UC San Diego;
(4) Zhiao Huang, UC San Diego;
(5) Mingu Lee, Qualcomm AI Research and Qualcomm AI Research
(6) Roland Memisevic, Qualcomm AI Research;
(7) Hao Su, UC San Diego.
:::
Table of LinksMotivation and Problem Formulation
Deductively Verifiable Chain-of-Thought Reasoning
Conclusion, Acknowledgements and References
\ A Deductive Verification with Vicuna Models
C More Details on Answer Extraction
E More Deductive Verification Examples
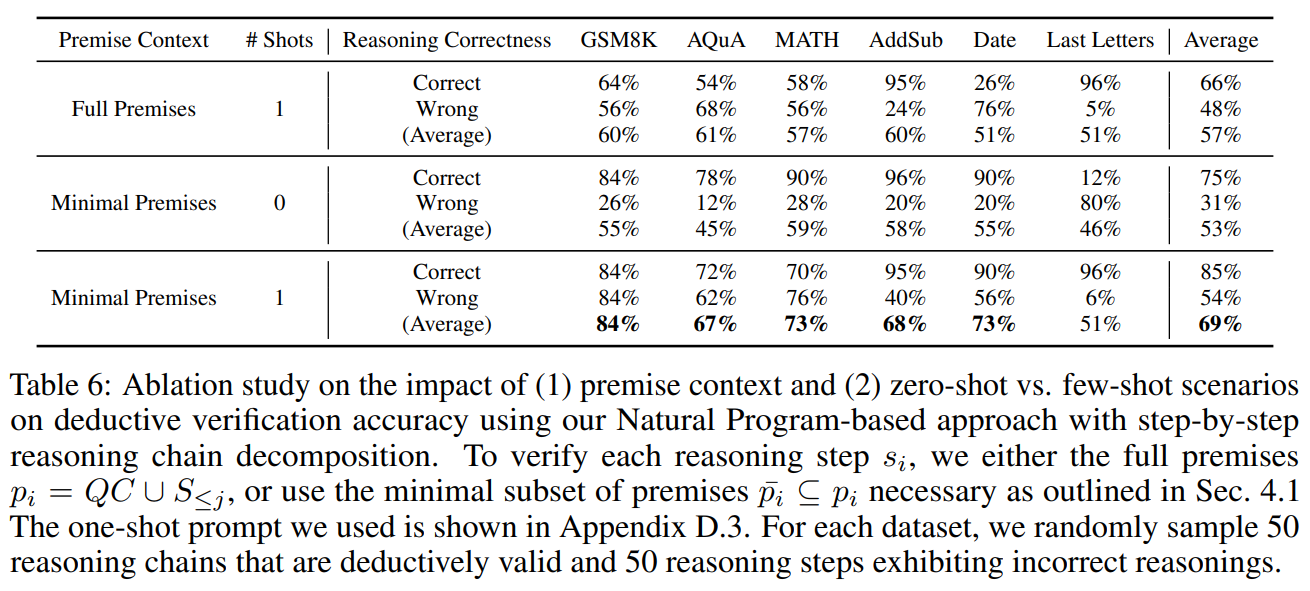
5 ExperimentsIn this section, we perform evaluations to demonstrate the effectiveness of our Natural Program-based deductive reasoning verification approach over diverse reasoning datasets. Firstly, we show that our deductive verification process leads to substantial improvements in the rigor and reliability of reasoning chains. Subsequently, we will examine the impact of deductive verification on the accuracy of final answers. Our findings reveal that by adopting our Natural Program reasoning format without verification, we improve answer correctness on challenging benchmarks. Further applying deductive verification leads to slight reductions in final answer accuracy. One reason for this phenomenon is that the verification process effectively identifies and eliminates flawed reasoning chains that still produce correct answers.
5.1 Experimental SetupBenchmarks. We evaluate the deductive verification accuracy and the answer correctness of reasoning chains over a diverse set of reasoning tasks: arithmetic reasoning, symbol manipulation, and date understanding. For arithmetic reasoning, we utilize the following benchmarks: 1) AddSub [19]; 2) GSM8K [10]; 3) MATH [17]; 4) AQuA [24]. Among these benchmarks, the AddSub and GSM8K datasets involve middle school-level multi-step calculations to arrive at a single number as the final answer. The MATH dataset presents more challenging problems that require expressing the answer as a mathematical expression in LaTeX format. These problems involve concepts from linear algebra, algebra, geometry, calculus, statistics, and number theory. AQuA also features similarly challenging problems, except that questions are in a multiple-choice format. For symbol manipulation, we use Last Letter Concatenation [50], where the model is tasked with concatenate the last letters of all the words provided in the question. For date understanding, we use the one from BIG-bench [45]
\ Deductive verification evaluation setup. For each of the above benchmarks, we select 100 reasoning chains, where 50 of them are deductively valid and 50 of them exhibit reasoning mistakes. The ground-truth deductive validity of each reasoning chain is determined by human annotators.
\ Answer extraction. To extract answers from reasoning solutions, we first perform text splitting based on answer prefix patterns such as “answer is” or “option is”. Then, using problem type-specific regular expressions, we extract the final answer. To extract the validity results from deductive verification processes, we only keep the last sentence of model response. We then extract the validity answer with regular expressions to obtain attitude words, e.g., “yes” or “no”, to determine the validity answer. Sometimes, language models may not provide a direct answer and instead output phrases like “not applicable” at the end of the response. In such cases, we consider the answer from the model as "yes". Please refer to Appendix C for more details.
\ Model and Hyperparameters. We conduct our main experiments with GPT-3.5-turbo (ChatGPT) [32]. We also present results for the LLama model-family [47]) in Appendix A, where we find the deductive verification accuracy to be worse than larger models even after finetuning. For ChatGPT, we use a generation temperature of T = 0.7. For Unanimity-Plurality Voting, we set k = 10 and k ′ = 3 by default. We use 1-shot prompting for both reasoning chain generation and deductive verification (except reasoning chain generation for the date understanding task where we use 2-shot). See Appendix D.2 and Appendix D.3 for more details.
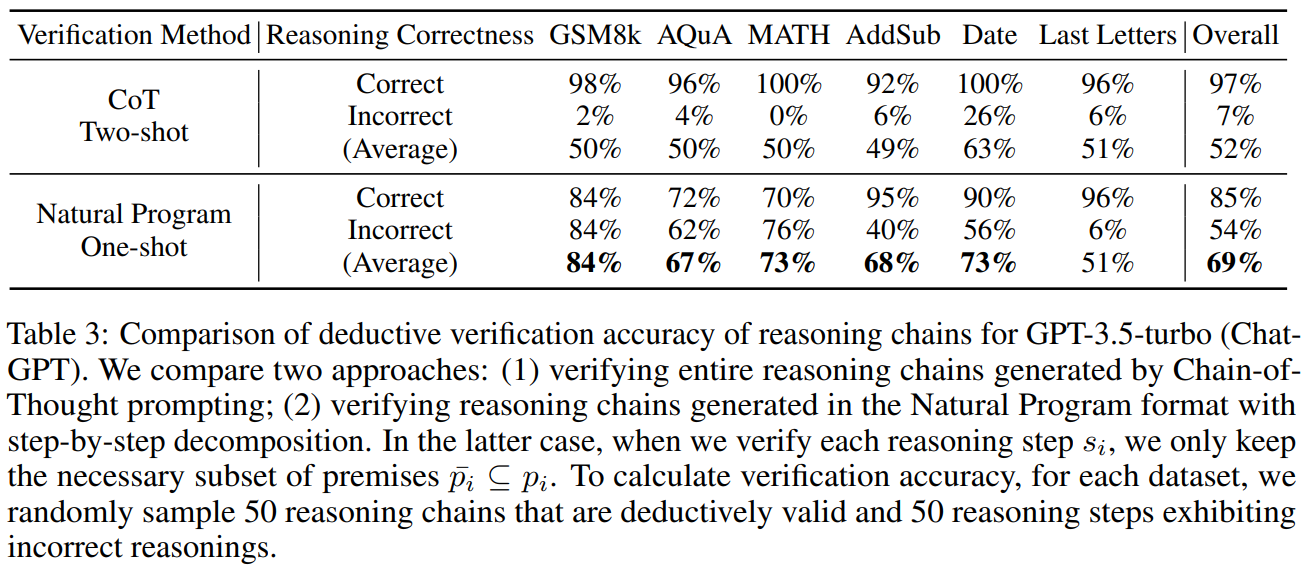
5.2 Comparison of Deductive Verification AccuracyWe compare the verification accuracy of reasoning chains using two methods: (1) verifying the entire reasoning chain at once (as described in Section 4.1) without utilizing the Natural Program, and
\
\
\ (2) our Natural Program-based verification approach with step-by-step decomposition. The results, presented in Table 3, indicate that our approach achieves significantly higher reasoning verification accuracy across most datasets. It effectively identifies erroneous reasoning in faulty chains while maintaining a low rate of false positives for valid chains. However, we observe that our approach’s effectiveness is limited on the “Last Letters” task. We hypothesize that this is due to the task’s nature, where each subsequent reasoning step is conditioned on all previous steps, presenting greater challenges for reasoning verification due to the increased dependency among premises.
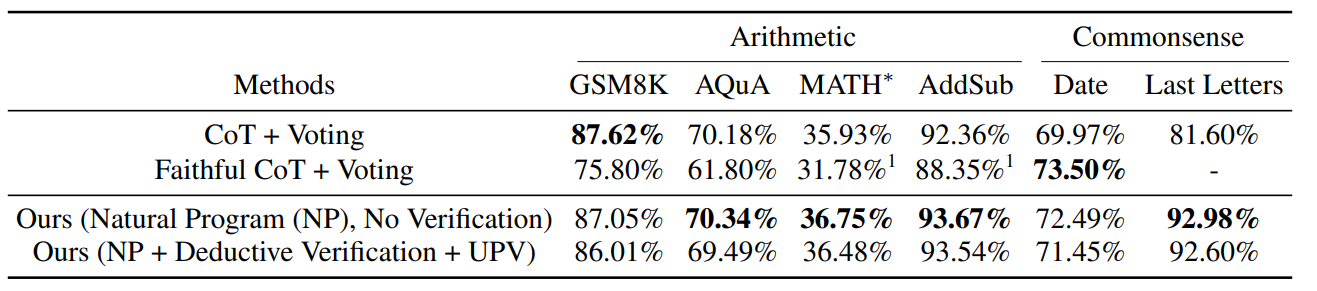
5.3 Impact of Natural Program and Deductive Verification on Final Answer CorrectnessWe then investigate the impact of our Natural Program reasoning format and our deductive verification process on final answer correctness. We conduct two experiments: (1) for each problem, we instruct language models to generate k = 10 reasoning chain candidates in the Natural Program (NP) format and perform simple majority voting on final answers, without using deductive verification to filter out reasoning chain candidates; (2) applying our deductive verification approach to filter out reasoning chain candidates, and apply Unanimity-Plurality Voting (UPV) along the process to determine the final answer. As a reference, we also report the performance of Chain-of-Thought (CoT) [50] and Faithful CoT [27]. For these baselines, we perform simple answer-based majority voting with k = 10 for fair comparison.
\ Results are presented in Tab. 4. While our major goal is to improve the trustworthiness and reliability of deductive reasoning, we find that prompting language models to reason in our Natural Program format achieves on-par or better final answer accuracy than baselines over many reasoning tasks. Upon further applying our deductive verification approach to filter out invalid reasoning chains, we observe a slight decrease in final answer accuracy. One major contributing factor to this decrease is the filtering out of reasoning chain candidates that provide correct answers but exhibit incorrect reasoning. We illustrate an example in Table 5, where ChatGPT generates the correct final answer but assigns incorrect premise numbers to support the first reasoning step. We note that in many such cases, our approach effectively identifies these reasoning errors, thereby enhancing the rigor and
\

\
\ reliability of the language models’ reasoning processes, albeit with a slight negative impact on the overall final answer correctness. Further discussions are presented in Appendix B.
5.4 Ablation Study
\ We also ablate on our Unanimity-Plurality Voting strategy by investigating the impact of different k ′ . Recall that k ′ determines the number of votes to produce validity predictions of single-step reasoning. Results are shown in Tab. 7. We observe that increasing k ′ generally enhances reasoning validation accuracy, though we note that this is at the expense of more compute.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\