and the distribution of digital products.
How to Integrate Apache DolphinScheduler with AWS EMR & Redshift
\
IntroductionIn this article, we will share the practice of integrating DolphinScheduler with AWS’s EMR and Redshift, hoping to provide you with a deeper understanding of AWS’s intelligent data lakehouse architecture and the importance of DolphinScheduler in real-world applications.
AWS Intelligent Data Lakehouse ArchitectureFirst, let’s take a look at the classic AWS intelligent data lakehouse architecture diagram.
\
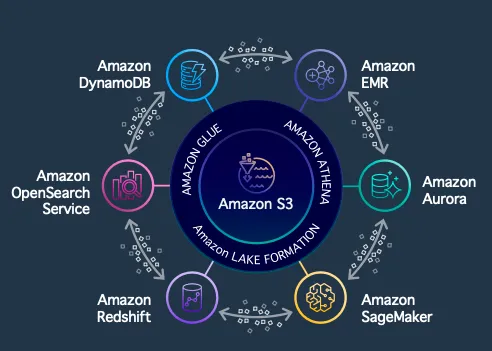
This diagram shows the data lake centered on S3, surrounded by various components, including databases, Hadoop’s EMR, big data processing, data warehouses, machine learning, log query, and full-text search.
These components form a complete ecosystem, ensuring that data can flow freely within the enterprise, whether from the periphery to the core or from the core to the periphery.
The core goal of the intelligent data lakehouse architecture is to enable the free movement of data between various components, improving the flexibility and efficiency of enterprise data processing.
Data Sources and Data Ingestion ToolsTo better understand this diagram, we can interpret it from left to right. On the left are various data sources, including databases, applications, and data ingestion tools.
\
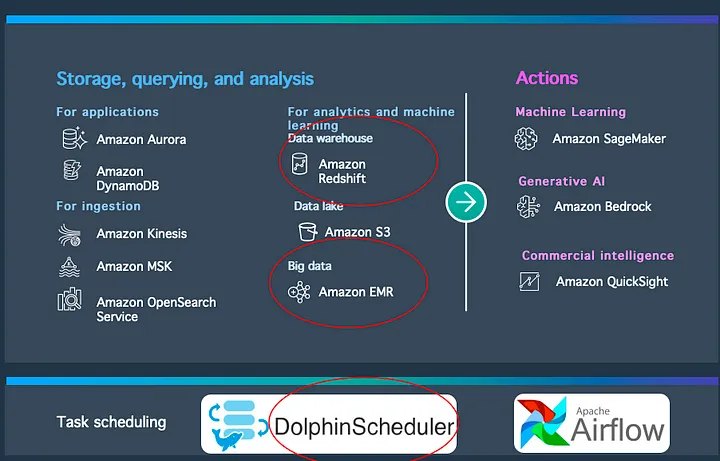
These tools include Kinesis, MSK (Managed Kafka), and OpenSearch, which are excellent tools for efficient data ingestion.
Core Components IntroductionToday’s focus is on the key components circled in the diagram:
- Redshift: A solution for data warehousing.
- EMR: A big data processing component within the Hadoop ecosystem.
- DolphinScheduler: A task scheduling tool.
Downstream of big data processing also includes BI (Business Intelligence), traditional machine learning, and the latest generative AI. Further down are people, applications, and devices within the enterprise. This diagram shows the entire data processing and analysis process, making the data processing journey more intuitive and smooth.
Today’s sharing mainly revolves around the following two core points:
- Practice of EMR with DolphinScheduler
- Practice of Redshift with DolphinScheduler
Before that, let’s briefly introduce EMR.
Introduction to Amazon EMRAmazon EMR (Elastic MapReduce) is a cloud service provided by Amazon Web Services (AWS) to easily run various components of the Hadoop ecosystem, including Spark, Hive, Flink, HBase, etc.
Its main features include:
- Timely Updates: Staying up to date with the latest versions from the open-source community.
- Automatic Elastic Scaling: Automatically adjust the size of the cluster based on the workload.
- Various Pricing Models: Flexible combination of different pricing models for optimal cost-efficiency.
Compared to traditional on-premises Hadoop clusters, EMR has the following advantages:
- Full utilization of native features.
- Flexible use of various pricing models.
- Automatic elastic scaling.
When using Hadoop for data analysis and big data processing, enterprises are increasingly focusing on cost control, not just performance.
The following diagram shows the cost structure of self-built Hadoop clusters in on-premises data centers, including server costs, network costs, labor maintenance costs, and other additional expenses. These costs are often very high.
\
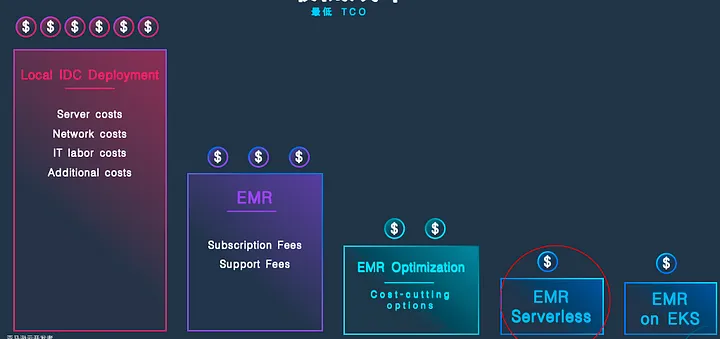
Many enterprises, due to difficulties in on-premises expansion, long procurement cycles, and challenges in upgrades, are gradually migrating Hadoop workloads to the cloud with EMR.
By paying subscription fees and additional support fees, enterprises can enjoy the following benefits:
- Flexible combination of pricing models.
- Automatic elastic scaling.
- Parameter tuning.
A client migrates from an on-premises data center to AWS EMR for optimization, using EMR and DolphinScheduler in the cloud and achieving both performance and cost optimization.
Finally, the client achieved a hybrid use of cluster-based EMR and EMR Serverless, migrating some workloads to EMR Serverless for optimal cost-efficiency, with performance optimization largely representing cost optimization.
Scheduling Optimization and Practice Post-Migration Scheduling MethodAfter migrating to cloud-based EMR On EC2, the client’s scheduling method was as follows:
- Small tasks: Took about 20–30 minutes each, spread throughout 24 hours.
- Large tasks: Executed within a 7-hour window per day.
- Extra-large tasks: Took 3–5 days or even a week, running only two to three times a month.
Through Apache DolphinScheduler, the client scheduled workloads to both EMR On EC2 and EMR Serverless.
\
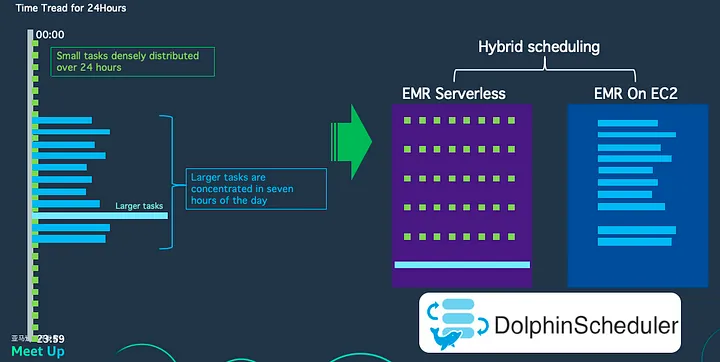
- Specific Approach:
- Small tasks: Moved to EMR Serverless, as these tasks do not require 3–4 nodes, with 10GB-20GB of memory being sufficient.
- Large tasks: Remained on EMR On EC2, as these tasks run relatively concentrated on the cloud, allowing for scheduled cluster startup and shutdown to reduce costs.
- Extra-large tasks: Moved to EMR Serverless, with CPU and memory consumption monitored for each run, visualizing task run costs for targeted and continuous cost optimization.
Using AWS Glue as a unified metadata management tool, the process of creating, destroying, and recreating clusters does not require recovering metadata or data, and the same set of data and metadata can be seamlessly used between EMR On EC2 and EMR Serverless.
Challenges and SolutionsDuring this process, we also encountered some challenges:
- Asynchronous Submission Issue: EMR Serverless currently only supports asynchronous submission, while batch processing tasks require synchronous execution. We resolved this by encapsulating a Python library to create a unified API interface.
- Log Viewing Inconsistencies: Log viewing differs between EMR and EMR Serverless. Through DolphinScheduler, we achieved unified log download and viewing, improving the customer experience.
- API Interface Differences: The API interfaces of EMR and EMR Serverless differ. We reduced maintenance costs for customers by encapsulating a unified API interface.
- SQL Submission Limitation: EMR Serverless does not currently support direct SQL submission. We indirectly implemented SQL submission through Python scripts.
We collaborated with the client to encapsulate a Python library that unified the task submission, log query, and status query interfaces for both EMR On EC2 and EMR Serverless. In DolphinScheduler, the client can seamlessly switch workloads between EMR Serverless and EMR on EC2 through a unified API.
\
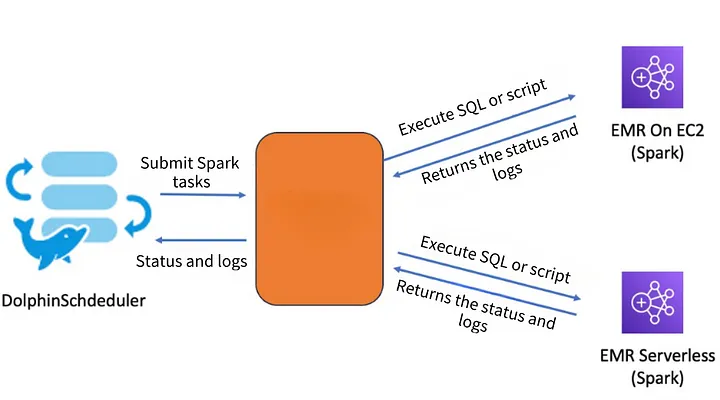
For example, when scheduling to EMR On EC2 in DolphinScheduler, the script is as follows:
\
from emr_common import Session session_emr = Session(job_type=0) session_emr.submit_sql("job_name", "your_sql_query") session_emr.submit_file("job_name", "your_pyspark_script")\ When scheduling to EMR Serverless, the script is as follows:
\
from emr_common import Session session_emrserverless = Session(job_type=1) session_emrserverless.submit_sql("your_sql_query") session_emrserverless.submit_file("job_name", "your_pyspark_script")\ \ Through Apache DolphinScheduler’s parameter passing feature, the entire code can freely switch between different engines, achieving seamless scheduling. In addition to the basic job type parameter, there are many other parameters available for configuration.
To simplify user operations, the system sets default values for most parameters, so users usually don’t need to configure these parameters manually.
For example, users can specify the cluster on which the task will run, and if not specified, the system will default to selecting the first active application or cluster-ID.
Additionally, users can set parameters related to the driver and executor for each Spark task. If these parameters are not specified, the system will use default values.
Encapsulating the SessionTo simplify operations, we encapsulated a session object, which contains two subclasses: EMRSession and EMRServerlessSession.
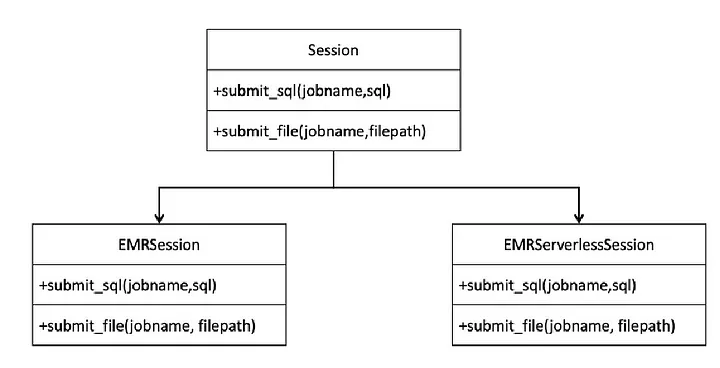
Depending on the different parameters passed,a session object is instantiated. Whether submitting SQL queries or script files, the interfaces are consistent from top to bottom.
User ExperienceThis is an example of a Python Operator in DolphinScheduler, containing code for both EMR On EC2 and EMR Serverless:
\
from emr_common import Session # EMR On EC2 session_emr = Session(job_type=0) session_emr.submit_sql("job_name","your_sql_query") session_emr.submit_file("job_name","your_pyspark_script") # EMR Serverless session_emrserverless = Session(job_type=1) session_emrserverless.submit_sql("your_sql_query") session_emrserverless.submit_file("job_name","your_pyspark_script")\
Actual ResultsThrough the above optimizations, the client not only significantly reduced task runtime but also achieved substantial cost savings.
For example, without tuning, the task time was reduced from 13 hours to 10 hours, and after multiple optimizations, the final task time was reduced to 2.4 hours, with a mix of cluster-based EMR and Serverless EMR versions being used.
This case shows that by using AWS EMR and DolphinScheduler, enterprises can achieve higher cost-effectiveness while ensuring performance. We hope this case can provide some insights and references for those looking to optimize big data processing in the cloud.
Redshift IntegrationRedshift is a cloud data warehouse launched by AWS over a decade ago and is one of the most mature cloud data warehouses in the industry. With Redshift, users can seamlessly integrate data warehouses, data lakes, and databases.
Redshift is a distributed data warehouse product that supports Union and Federated Queries, Integration with S3 Data Lake, and Integration with Machine Learning. It supports cluster deployment and a Serverless mode. In Serverless mode, users don’t need to manage load and resource scaling; they can focus solely on SQL code and data development applications. This further simplifies the data development process, allowing users to concentrate more on business-level development rather than the underlying operations and maintenance.
From version 3.0, Apache DolphinScheduler supports Redshift data sources. Through DolphinScheduler’s SQL Operator, users can directly write Redshift SQL for big data development and applications.
Users can easily customize DAGs by dragging and dropping and monitor the execution of various tasks and processes.
Concurrency ControlRedshift is an OLAP database characterized by high throughput and fast computation, but its concurrency typically does not exceed 50. This is a challenge for clients scheduling a large number of concurrent tasks.
To address this, there are two options:
- Enable Redshift Concurrency Scaling: Scale up to 10 times the preset capacity, though this incurs additional costs.
- Use DolphinScheduler’s Concurrency Control: Create task groups, set resource capacities, and control the concurrency of tasks scheduled to Redshift, avoiding cluster overload.
When developing with Redshift using DolphinScheduler, it is recommended to use the SQL Operator, but the Shell Operator can also be used to execute SQL files with the sql -f xxx.sql command.
\
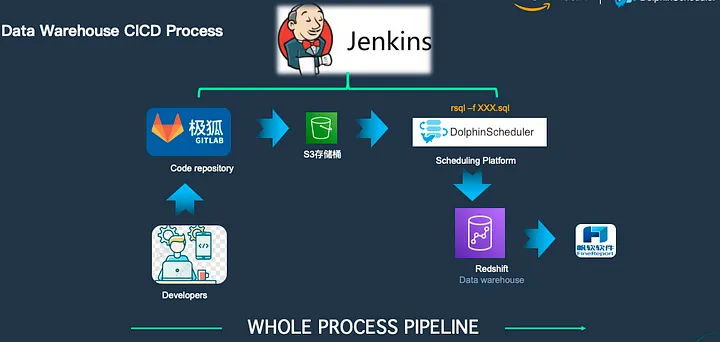
The advantage of this approach is its integration with the CI/CD process. Developers can develop code on their personal computers via GitLab, and upon submission, it automatically uploads to an S3 bucket. DolphinScheduler supports reading code files from the S3 bucket and submitting them for execution in Redshift.
For example, after code is pushed to GitLab via Jenkins, it automatically uploads to an S3 bucket. Once the file is created in DolphinScheduler’s resource center, it automatically writes the file to S3 and updates DolphinScheduler’s metadata, achieving seamless integration with CI/CD.
ConclusionToday, we shared experiences and practices on integrating EMR and EMR Serverless with DolphinScheduler, as well as the integration of Redshift with DolphinScheduler. Below are my expectations and outlook for the DolphinScheduler community:
- SQL Syntax Tree Parsing for Lineage: I hope DolphinScheduler can provide data lineage generation based on SQL syntax tree parsing, especially at the field level.
- Introduction of AI Agents in Workflow Orchestration: I hope that in the future, DolphinScheduler will consider introducing AI agents in workflow orchestration or introducing an AI agent Operator.
Previously, WhaleOps has listed its product WhaleStudio (a commercial version based on Apache DolphinScheduler and SeaTunnel) on the AWS Marketplace. Welcome to visit the site to learn more about the product and subscribe: https://aws.amazon.com/marketplace/pp/prodview-563cegc47oxwm?sr=0-1&ref_=beagle&applicationId=AWSMPContessa.