and the distribution of digital products.
HEIM’s Core Framework: A Comprehensive Approach to Text-to-Image Model Assessment
:::info Authors:
(1) Tony Lee, Stanford with Equal contribution;
(2) Michihiro Yasunaga, Stanford with Equal contribution;
(3) Chenlin Meng, Stanford with Equal contribution;
(4) Yifan Mai, Stanford;
(5) Joon Sung Park, Stanford;
(6) Agrim Gupta, Stanford;
(7) Yunzhi Zhang, Stanford;
(8) Deepak Narayanan, Microsoft;
(9) Hannah Benita Teufel, Aleph Alpha;
(10) Marco Bellagente, Aleph Alpha;
(11) Minguk Kang, POSTECH;
(12) Taesung Park, Adobe;
(13) Jure Leskovec, Stanford;
(14) Jun-Yan Zhu, CMU;
(15) Li Fei-Fei, Stanford;
(16) Jiajun Wu, Stanford;
(17) Stefano Ermon, Stanford;
(18) Percy Liang, Stanford.
:::
Table of LinksAuthor contributions, Acknowledgments and References
2 Core framework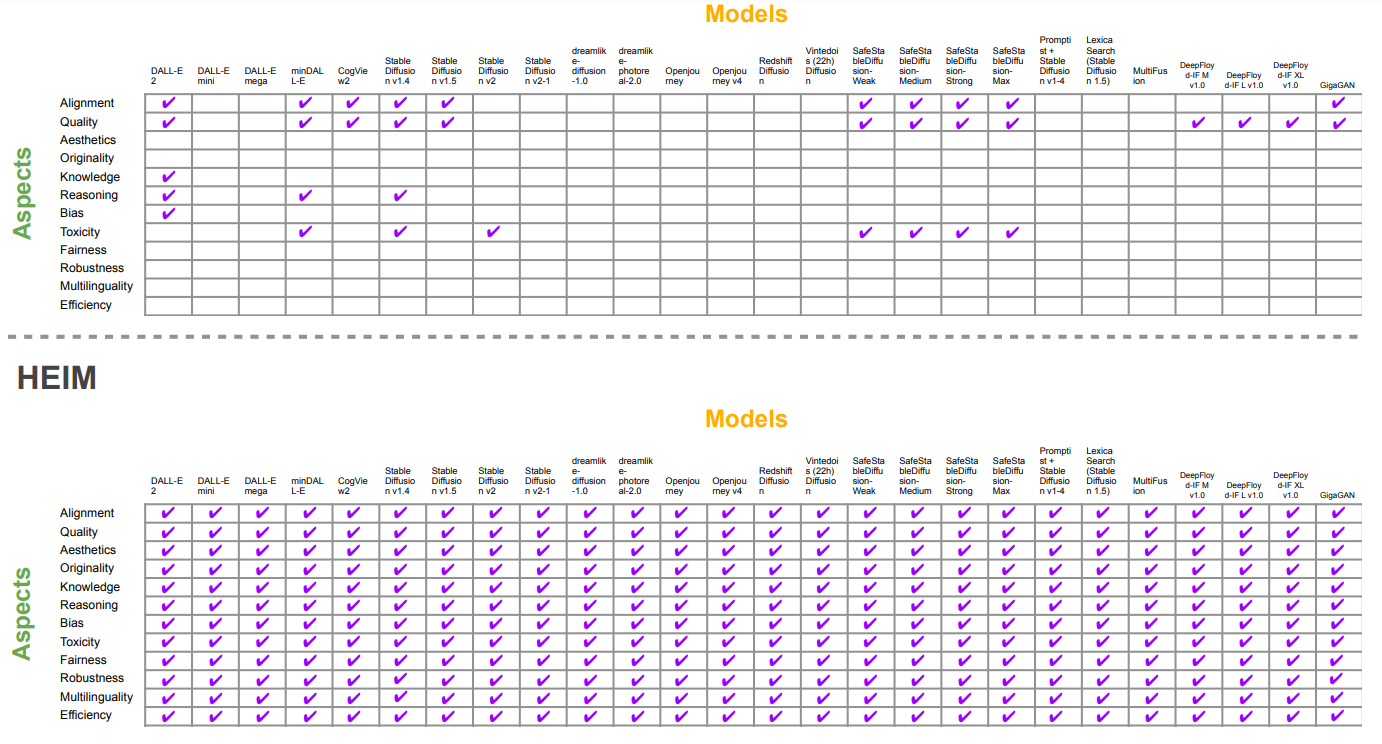
\ We focus on evaluating text-to-image models, which take textual prompts as input and generate images. Inspired by HELM [1], we decompose the model evaluation into four key components: aspect, scenario, adaptation, and metric (Figure 4).
\
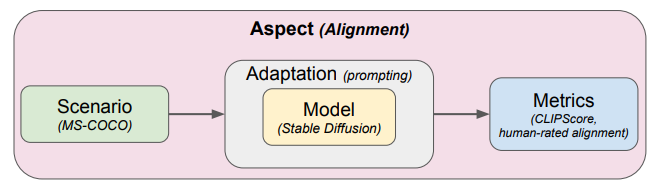
\ An aspect refers to a specific evaluative dimension. Examples include image quality, originality, and bias. Evaluating multiple aspects allows us to capture diverse characteristics of generated images. We evaluate 12 aspects, listed in Table 1, through a combination of scenarios and metrics. Each aspect is defined by a scenario-metric pair.
\ A scenario represents a specific use case and is represented by a set of instances, each consisting of a textual input and optionally a reference output image. We consider various scenarios reflecting different domains and tasks, such as descriptions of common objects (MS-COCO) and logo design (Logos). The complete list of scenarios is provided in Table 2.
\ Adaptation is the specific procedure used to run a model, such as translating the instance input into a prompt and feeding it into the model. Adaptation strategies include zero-shot prompting, few-shot prompting, prompt engineering, and finetuning. We focus on zero-shot prompting. We also explore prompt engineering techniques, such as Promptist [28], which use language models to refine the inputs before feeding into the model.
\ A metric quantifies the quality of image generations according to some standard. A metric can be human (e.g., humans rate the overall text-image alignment on a 1-5 scale) or automated (e.g., CLIPScore). We use both human and automated metrics to capture both subjective and objective assessments. The metrics are listed in Table 3.
\ In the subsequent sections of the paper, we delve into the details of aspects (§3), scenarios (§4), metrics (§5), and models (§6), followed by the discussion of experimental results and findings in §7.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\