and the distribution of digital products.
The HackerNoon Newsletter: AI Is Mapping Hidden Connections—And It’s Just Getting Started (2/14/2025)
:::info Authors:
(1) Tianyi Cui, University of Washington ([email protected]);
(2) Chenxingyu Zhao, University of Washington ([email protected]);
(3) Wei Zhang, Microsoft ([email protected]);
(4) Kaiyuan Zhang, University of Washington ([email protected]).
:::
:::tip Editor's note: This is Part 1 of 6 of a study detailing attempts to optimize layer-7 load balancing. Read the rest below.
:::
Table of Links2.2 Load balancers
3 SmartNIC-based Load Balancers and 3.1 Offloading to SmartNICs: Challenges and Opportunities
3.2 Laconic Overview
3.3 Lightweight Network Stack
3.4 Lightweight synchronization for shared data
3.5 Acceleration with Hardware Engine
4.2 End-to-end Throughput
4.3 End-to-end Latency
4.4 Evaluating the Benefits of Key Techniques
4.5 Real-world Workload
A Appendix
Load balancers are pervasively used inside today’s clouds to scalably distribute network requests across data center servers. Given the extensive use of load balancers and their associated operating costs, several efforts have focused on improving their efficiency by implementing Layer-4 load-balancing logic within the kernel or using hardware acceleration. This work explores whether the more complex and connection-oriented Layer-7 load-balancing capability can also benefit from hardware acceleration. In particular, we target the offloading of load-balancing capability onto programmable SmartNICs. We fully leverage the cost and energy efficiency of SmartNICs using three key ideas. First, we argue that a full and complex TCP/IP stack is not required for Layer-7 load balancers and instead propose a lightweight forwarding agent on the SmartNIC. Second, we develop connection management data structures with a high degree of concurrency with minimal synchronization when executed on multi-core SmartNICs. Finally, we describe how the load-balancing logic could be accelerated using custom packet-processing accelerators on SmartNICs. We prototype Laconic on two types of SmartNIC hardware, achieving over 150 Gbps throughput using all cores on BlueField-2, while a single SmartNIC core achieves 8.7x higher throughput and comparable latency to Nginx on a single x86 core.
1 IntroductionLoad balancers are a fundamental building block for data centers as they balance the service load across collections of application servers [38, 45, 46]. Load balancers were initially built as specialized hardware appliances but are now typically deployed as software running on commodity servers or VMs. This deployment model provides a greater degree of customizability and adaptability than the older hardwarebased designs, but it also can result in high costs for cloud providers and application services, given the purchase costs and the energy consumption of general-purpose servers [8]. Application services often go to great lengths to consolidate and reduce their use of load balancers to obtain desired cost savings [2, 4, 5].
\ Given the extensive use and cost of load balancers, several efforts have focused on improving their efficiency, especially Layer-4 (L4) load balancers, by embedding the load balancing logic in a lower, possibly hardware-accelerated, layer. Katran [16] is accelerated using eBPF code inside the Linux kernel, thus intercepting and processing packets within the kernel and minimizing the number of transitions to userlevel load-balancing code. ClickNP [32] tackles some aspects of the L4 load balancing logic (especially NAT-like capabilities) on an FPGA-enabled SmartNIC and exploits the parallel processing capabilities of FPGA devices. SilkRoad [38] uses a combination of a programmable switch and an end-host to store the state associated with L4 load balancers and perform the dataplane transformations related to the load-balancing operation within a switch pipeline.
\ While these efforts have made considerable gains in optimizing L4 load balancing that balances traffic at the network layer, data center services often rely on application-layer load-balancing capabilities found only in Layer-7 (L7) load balancers. In particular, services would like to route flows based on the attributes of the client request, preserve session affinity for client requests, provide access control, and so on [7]. But, these features make it harder for L7 load balancers to adopt the hardware-acceleration techniques used for L4 load balancers. A fundamental challenge is that the L7 load-balancing operation is based on information embedded within connection-oriented transport protocols, thus seeming to require a full-stack network processing agent on the load balancer to handle TCP/HTTP connections. Consequently, today’s L7 load balancers are generic software solutions incurring high processing costs on commodity servers.
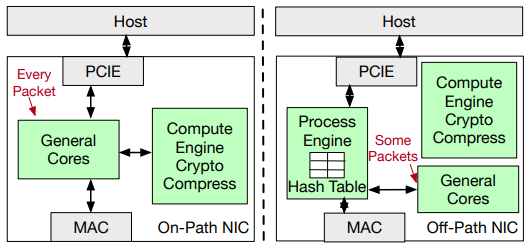
\ In this work, we examine whether we can improve the efficiency of L7 load balancers using programmable networking hardware. We focus on SmartNICs that provide general-purpose computing cores augmented with packet-processing hardware. SmartNICs are particularly attractive targets as their compute cores can host arbitrary protocol logic while their packet-processing accelerators can perform dataplane transformations efficiently. A SmartNIC thus combines the capabilities of traditional host computing with the emerging capabilities of programmable switches and is an appropriate target for L7 load balancers. Our work is also partly motivated by the increasing deployment of SmartNICs within data centers as a cost-effective and energy-efficient computing substrate for networking tasks.
\ Several challenges have to be addressed in offloading loadbalancing functionality to SmartNICs. First, SmartNIC cores are wimpy, equipped with limited memory, and inefficient at running general-purpose computations. To the extent possible, we should use lightweight network stacks instead of generic, full-functionality stacks present inside OS kernels. Second, efficient multi-core processing on the SmartNICs presumes lightweight synchronization for access to concurrent data structures, and this is particularly relevant as we slim down the network processing logic. Third, the effective use of accelerators for packet transformations is necessary to enhance the computing capability of SmartNICs.
\ We design and implement Laconic, a SmartNIC-offloaded load balancer that addresses the challenges raised above. A key component of our system is a lightweight network stack that represents a co-design of the application-layer load-balancing logic with the transport layer tasks. This lightweight network stack performs complex packet processing only on a subset of the packets transmitted through the load balancer. For the rest of the packets, the network stack performs simple rewriting of packets and relies on the client and the server to provide end-to-end reliability and congestion control. For SmartNICs with packet-processing accelerators, this design allows most of the packets to be processed using hardware-based flow-processing engines, thus providing significant efficiency gains. We also develop connection management data structures that are highly concurrent and minimize expensive mutual exclusion operations. We note that some of our design contributions also apply to a generic server-based design, but they have a multiplicative effect on SmartNICs by factoring out a fast path that can be executed on the hardware packet engines.
\ We built Laconic and tailored it to two different types of SmartNICs: Marvell LiquidIO3 and Nvidia BlueField-2. Laconic provides both Layer-4 and Layer-7 functionality and implements commonly used Layer-7 interposition logic for balancing connections to backend services. For large messages, Laconic running on BlueField-2 with one single ARM core can achieve up to 8.7x higher throughput than widely-used Nginx running on a more powerful x86 core. For small messages, Laconic on BlueField-2 can achieve higher throughput with comparable or even lower latency compared with Nginx. On LiquidIO3, the throughput of Laconic is 4.5x higher compared with x86 Nginx. We also demonstrate the Laconic performance with real-world workload and present detailed microbenchmarks on the benefits of key ideas.
\
\
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
:::
\