and the distribution of digital products.
FreeEval: Efficient Inference Backends
2 Background and 2.1 Automatic Evaluation Methods for LLMs
3 Design and Implementation and 3.1 Design Principles
3.2 FreeEval Architecture Overview and 3.3 Extensible Modular Design
3.5 Efficient Inference Backends
4 Conclusion, Ethical Considerations, and References
3.5 Efficient Inference BackendsFreeEval’s high-performance inference backends are designed to efficiently handle the computational demands of large-scale LLM evaluations.
\ The inference backends in FreeEval support both open-source models and proprietary models
\

\ with APIs, providing researchers with flexibility in choosing the LLMs they wish to evaluate. For all models, FreeEval support concurrent inference given a fixed number of workers. We implement a caching mechanism for queries based on hash values of the request. We hash the request prompt and inference config, and store locally the request content and response for each individual request. By checking the cache before making a query, FreeEval skips cached requests, enabling quick recovery from exceptions and saving inference costs. This is particularly beneficial when implementing and debugging new evaluation methods. Caching also ensures reproducibility, as all requests, parameters, and responses are saved and can be inspected using FreeEval’s visualization tools.
\ For open-source models, we leverage Huggingface’s text-generation-inference (TGI) (Contributors, 2023a) package which is a productionready high-performance inference toolkit. We implement a load-balancing technique in conjunction with the continuous batching feature provided by TGI to maximize GPU utilization on multi-node multi-GPU clusters. For proprietary models, we also implement a rate-limiting mechanism so that users could define their total number of requests per minute, to avoid causing too much stress on API providers.
\ We evaluate FreeEval’s performance by comparing the execution times (excluding dataset downloading times) for llama-2-7b-chat-hf model on 3 common datasets using different toolkits. Our experiments are done on the same Ubuntu machine
\
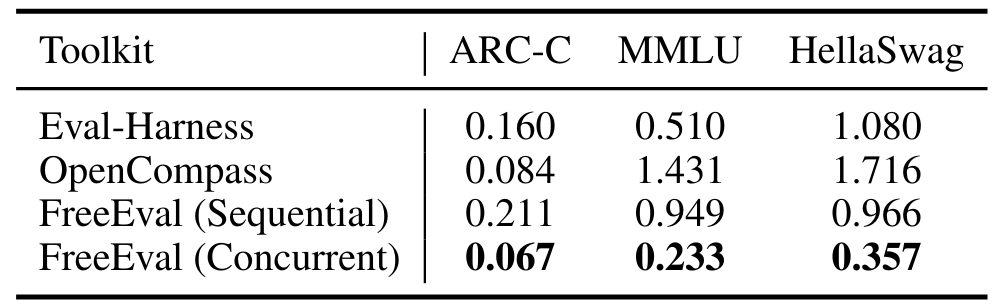
\ with a single NVIDIA A800 80GB PCIe GPU and Intel Xeon Gold CPU. As shown in Table 3, even on a single GPU, FreeEval (with concurrent execution enabled) exhibit significant advantage on all benchmark datasets.
\ The inference backends in FreeEval are designed to seamlessly integrate with the evaluation methods and meta-evaluation components of the framework. As illustrated in Figure 3, initializing the inference backends and running parallel inference is straightforward and user-friendly. This simplicity allows developers of new evaluation methods to focus on prompting or interactions between models, using the backends sequentially. As a result, implementing interactive evaluation methods, such as those proposed by Li et al. (2023a); Chan et al. (2023); Yu et al. (2024), becomes much easier and more accessible to researchers.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
:::info Authors:
(1) Zhuohao Yu, Peking University;
(2) Chang Gao, Peking University;
(3) Wenjin Yao, Peking University;
(4) Yidong Wang, Peking University;
(5) Zhengran Zeng, Peking University;
(6) Wei Ye, Peking University and a corresponding author;
(7) Jindong Wang, Microsoft Research;
(8) Yue Zhang, Westlake University;
(9) Shikun Zhang, Peking University.
:::
\