and the distribution of digital products.
Formal Definition of the Conscious Turing Machine Robot
:::info Authors:
(1) Lenore Blum ([email protected]);
(2) Manuel Blum ([email protected]).
:::
Table of Links2 Brief Overview of CtmR, a Robot with a CTM Brain
2.2 Conscious Attention in CtmR
2.3 Conscious Awareness and the Feeling of Consciousness in CtmR
2.4 CtmR as a Framework for Artificial General Intelligence (AGI)
3 Alignment of CtmR with Other Theories of Consciousness
4 Addressing Kevin Mitchell’s questions from the perspective of CtmR
7 Appendix
7.1 A Brief History of the Theoretical Computer Science Approach to Computation
7.2 The Probabilistic Competition for Conscious Attention and the Influence of Disposition on it
2.1 Formal Definition of CtmRCtmR is defined formally as a 7-tuple, (STM, LTM, Up-Tree, Down-Tree, Links, Input, Output). The seven components each have well-defined properties. We indicate these properties here.
\ For CtmR, the stage in the theater model is represented by a Short Term Memory (STM) that at any moment in time contains CtmR’s current conscious content. STM is not a processor; it is merely a buffer and broadcasting station. The N audience members[6] are represented by a massive collection of initially independent powerful (unconscious) processors that comprise CtmR's computational machinery and Long Term Memory, together called LTM. These processors compete to get their information on stage to be immediately broadcast to the audience.[7] (See Appendix 7.2 for a discussion of CtmR’s competition.)
\ CtmR has a finite lifetime T. 8 At time t = 0, all but the input and output LTM processors are “generic” with certain basic built-in properties, e.g., some learning/prediction correction algorithms, as well as a preference for choosing the positive over the negative. [9] Their functionalities evolve over time.
\ But for now, we designate some important LTM processors built in. These include: a Model-of-theWorld processor (MotWp), actually a collection of processors, for building models of CtmR’s inner and outer worlds; Sensation processors (with input from CtmR’s outer world via its various sensors[10]); Motor processors (with output to CtmR’s outer world via motor actuators[11]); and so on. We also allow off-the-shelf processors (like ChatGPT and Google) that extend CtmR’s capabilities.
\ All processors are in LTM so when we speak of a processor, we mean an LTM processor. While each processor may have its own distinct language, processors communicate within CtmR in Brainish, Brainish being CtmR’s rich multimodal inner language. Brainish words, gists, and phrases fuse sensory modalities (e.g., sight, sounds, smells, tactile) as well as dynamical processes. [12] The Brainish language evolves over CtmR’s lifetime.[13] Brainish can differ from one CtmR to another.
\ LTM processors compete in a well-defined (fast and natural) probabilistic competition (Appendix 7.2) to get their questions, answers, and information onto the stage (STM). The competition is hosted by the Up-Tree, a perfect binary tree[14] of height h which has a leaf in each LTM processor and root in STM. At each clock tick, a new competition starts with each processor putting a chunk of information into its Up-Tree leaf node.
\ A chunk is defined formally to be a tuple, , consisting of (in order of importance) a succinct Brainish gist of information, a valenced weight (to indicate the importance/urgency/value/confidence the originating processor assigns the gist), a pointer to the originating processor, and the time the chunk was created, plus some auxiliary information.
\ Each submitted chunk competes locally with its neighbor; a variation of the local winner moves up one level of the Up-Tree in one clock tick, now to compete with its neighbor. The process continues until a chunk reaches the Up-Tree root node in STM. The competition takes h clock ticks.
\ Notable about CtmR’s probabilistic competition is that the winner is independent of its submitting processor’s location. (See Appendix 7.2.) Clearly this is an important feature for a machine or brain; no moving around of processors is needed. And also, it is fairer than other binary tournaments (e.g., tennis or chess).
\ The chunk that gets onto the stage (STM) , i.e., the winning chunk, is called CtmR’s current conscious content and is immediately globally broadcast (in one clock tick) via the Down-Tree (a bush of height 1 with a root in STM and N branches, one leaf in each LTM processor) to the audience (of all LTM processors). [KM2] [KM5]
\ The single chunk in STM to be globally broadcast will enable CtmR to focus attention on the winning gist. “One” is not the “magical number” 7±2 proposed by George Miller (Miller G. A., 1956), but we are looking for simplicity and one chunk will do.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
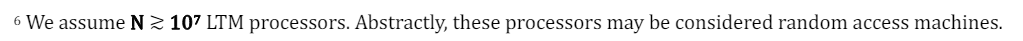
\ [7] As an example of the theater analogy, consider the “What’s her name?” scenario: Suppose at a party, we see someone we know but cannot recall her name. Greatly embarrassed, we rack our brain to remember. An hour later when we are home, her name pops into our head (unfortunately too late). What’s going on?
\ Racking our brain to remember caused the urgent request “What’s her name?” coming from LTM processor p to rise to the stage (STM) which in turn was immediately broadcast to the audience.
\ Some (LTM) processors try to answer the query. One such processor recalls we met in a neuroscience class; this information gets to the stage and is broadcast triggering another processor to recall that what’s-her-name is interested in “consciousness”, which is broadcast. Another processor p’ sends information to the stage asserting that her name likely begins with S.
\ But sometime later the stage receives information from processor p’’ that her name begins with T which prompts processor p’’’ (who has been paying attention to all the broadcasted information) to claim with great certainty that her name is Tina – which is correct. The name is broadcast from the stage, our audience of processors receives it, and we finally remember her name. Our conscious self has no idea how her name was found.
\ (Based on the correct outcome, learning algorithms internal to each processor, cause processor p’ to lower the importance (|weight|) it gives its information and cause p’’ to increase the importance.)
\ [8] For the general CtmR theory, both T (lifetime) and N (number of LTM processors) are parameters. Time t = 0, 1, 2, 3, … , T is measured in discrete clock ticks.
\ [9] This built-in preference creates a predilection for survival.
\ [10] Ears, eyes, nose, skin, … .
\ [11] Arms, hands, legs, … .
\ [12] A succinct Brainish gist is like a frame in a dream.
\ [13] Paul Liang is developing a computational framework for Brainish (Liang, 2022).
\ [14] A perfect binary tree is a binary tree in which all leaf nodes are at the same depth. This depth is also the height of the tree. If h is the height of a perfect binary tree, then the tree has N = 2h leaves. Each node, except the root node, has a unique neighbor. For simplicity, we choose a perfect binary tree in this chapter.