and the distribution of digital products.
The Evolution of Apache SeaTunnel’s Technical Architecture and Its Applications in the AI Field
\ With the growing demand for data integration, Apache SeaTunnel, as a new generation of data synchronization engine, has not only continuously evolved in its technical architecture but has also shown unique value in AI applications. At the CommunityOverCode Asia 2024 conference, Apache SeaTunnel PMC Chair Gao Jun delved into SeaTunnel’s technical evolution, analyzed its application cases in the AI field, and provided insights into future development plans.
Building a Data Integration System from ScratchThe initial motivation for building a data integration system stemmed from the need to synchronize data across various sources to target databases, such as from MySQL to MySQL, or PostgreSQL to Oracle. The variety of data sources prompted the design of flexible source and target connectors.
Source Connectors & Sink ConnectorsThe design of SeaTunnel abstracts the process between data sources and targets. It loads plugins via SPI, allowing data to be written from the source to the target.
\
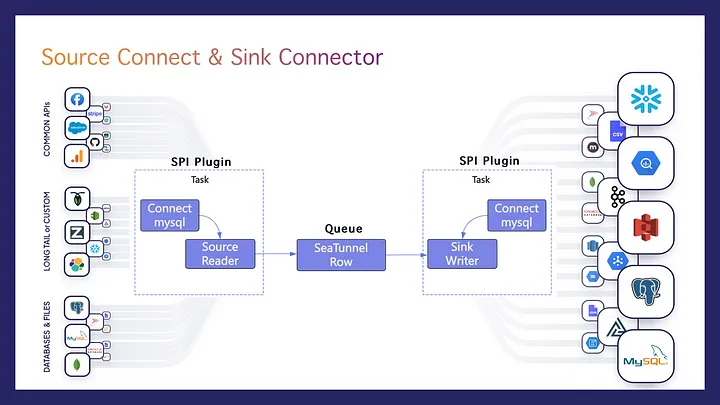
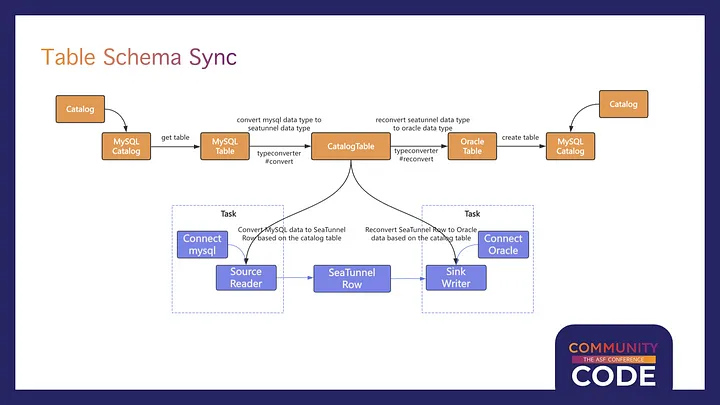
If the target lacks the source’s table structure, a CatalogTable interface is needed to read the source's table structure, transforming it into a format like a MySQL table, and then converting it to the corresponding target structure. This ensures efficient data queue management and table structure synchronization through simple code before data flows between different systems.
\
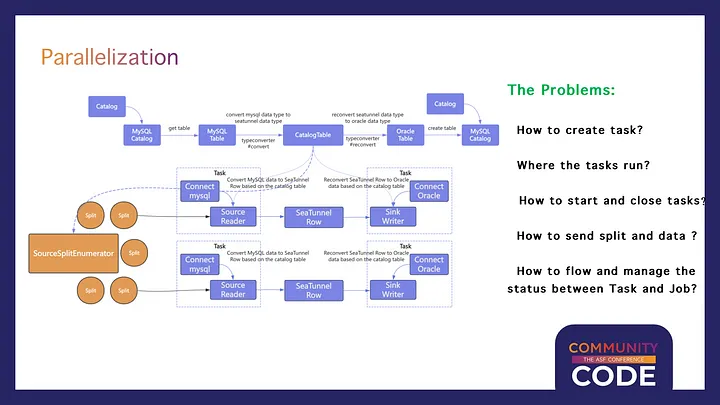
In designing SeaTunnel, we paid special attention to multiple aspects of parallel processing, including task creation, execution location, startup and shutdown, data partitioning, and state flow management between tasks and jobs. SeaTunnel transforms single-threaded tasks into multi-threaded processes, where an enumerator splits massive amounts of data into instances and sends them to the Source Reader. Each Reader executes a SQL query, enabling parallel data reading.
\
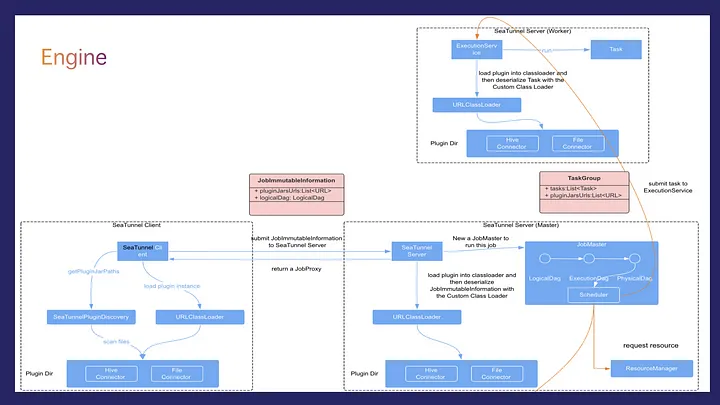
With so many task instances, when do they start, and end, and for how long? What is the order of execution? This is where the SeaTunnel engine plays a crucial role. It provides a unified data synchronization and integration solution, supporting various data sources and targets, and handling large-scale data flows.
\
The emergence of increasingly complex data integration engines is driven by evolving demands. In this context, Apache SeaTunnel was born.
Design GoalsThe design goals of SeaTunnel include:
- Ease of Use: Synchronization tasks can be created and executed with simple configurations and commands.
- Monitorable Synchronization Process: Automatically collects metrics during synchronization, such as data volume, performance metrics, and data latency.
- Rich Data Source Ecosystem: Supports a wide range of databases, message queues, cloud storage, cloud components, data lakes, warehouses, SaaS services, and user-defined data sources.
- Comprehensive Scenario Support: Supports all data integration scenarios, including offline, real-time, full, incremental, CDC, entire database CDC synchronization, DDL changes, and dynamic table addition.
- Data Consistency Guarantee: Ensures no data loss, no duplication, exact once processing, and supports checkpointing and resumption.
- Resource Efficiency: Optimizes memory, and CPU threads, and allows database connection sharing for multi-table synchronization.
SeaTunnel’s architecture comprises target databases, source databases, and data synchronization and integration components. The middle layer includes abstract APIs such as Table API, Source API, Sink API, Engine API, Catalog API, and Type Converter API, among others. Connectors built on these APIs can run on multiple engines, including SeaTunnel’s native Zeta engine, currently the fastest data synchronization engine in our tests. Additionally, SeaTunnel supports translating connectors into Spark and Flink connectors through a translation layer, enabling them to run on Spark and Flink engines.
\
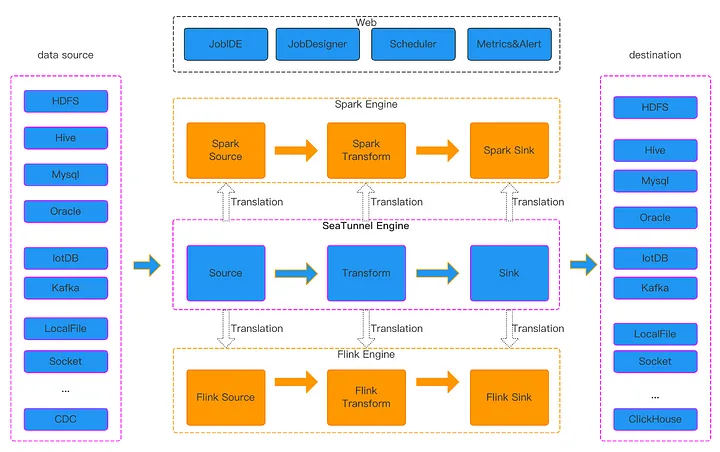
Currently, the SeaTunnel community supports over 160 data source connectors, with ongoing rapid iteration and updates.
Decoupling Connector API from EngineSeaTunnel is a data synchronization tool designed for data integration scenarios, providing a complete set of connector APIs, including source, transform, target, checkpoint, and translation APIs. It supports multiple engines and versions, addressing the decoupling issue from computing engines while offering unified stream-batch processing APIs and JDBC multiplexing.
\

SeaTunnel’s source connector supports both offline and real-time operation modes, easily switched by the job mode in the environment configuration. The Source connector enables parallel reading, dynamic partition discovery, field projection, multi-table reading, and exactly-once semantics support, and adapts to Zeta, Spark, and Flink’s Checkpoint mechanism.
\

By setting job.mode in the environment configuration to BATCH or DataMING, SeaTunnel's Sink connector can easily switch between offline and real-time synchronization modes.
\

Features of the Sink connector include:
- SaveMode support, offering flexible options for target performance and data handling.
- Automatic table creation with template modification support, freeing up hands in multi-table synchronization scenarios.
- Exact-once semantics, ensuring no data loss or duplication, and Checkpoint mechanism adaptation for Zeta, Spark, and Flink engines.
- CDC support, handling database log events.
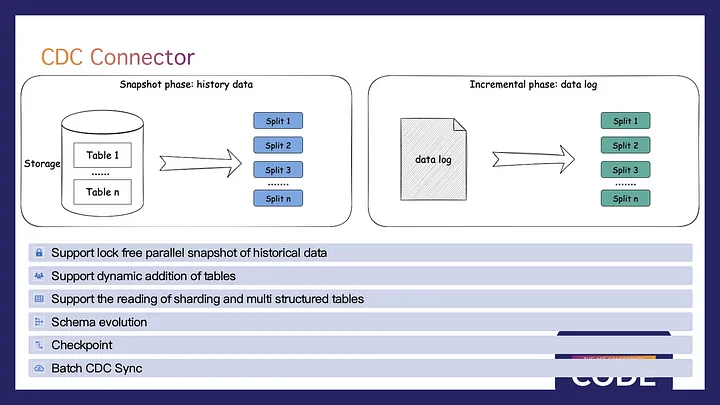
SeaTunnel’s Change Data Capture (CDC) mainly serves CDC synchronization. The connector supports lock-free snapshot reading, dynamic table discovery, multi-table synchronization and writing, schema evolution, checkpointing, and CDC bulk data synchronization, catering to offline data synchronization needs.
\
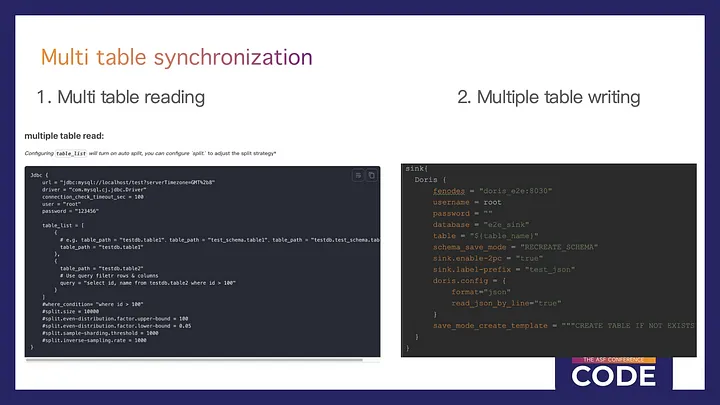
SeaTunnel supports multi-table data reading and writing, enabling rapid multi-table data operations with simple configurations.
\
SeaTunnel Zeta, as a new-generation data synchronization engine, boasts features not found in other computing engines:
- Independent of third-party components and big data platforms.
- Masterless, with an embedded distributed grid for persistent memory storage.
- Supports WAL, allowing job recovery even after a full cluster restart.
- The distributed snapshot algorithm ensures data consistency.
- Finer-grained data synchronization monitoring metrics.
- Event notification mechanism support.
- Class loader isolation and caching, enhancing system stability and performance.
Recently, the community has made strides in AI applications, adding support for various vector data types, such as BINARYVECTOR, FLOATVECTOR, FLOAT16VECTOR, BFLOAT16VECTOR, SPARSEFLOATVECTOR, and more, providing robust support for data processing in the AI field.
Looking ahead, the community plans to introduce specialized Transforms for precise processing of vector data types.
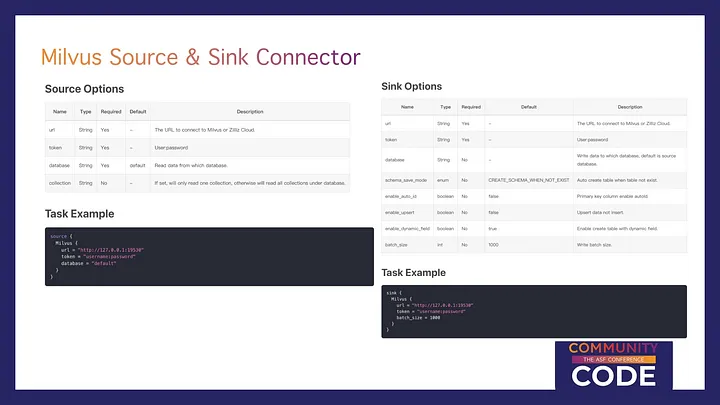
Currently, version 2.3.6 of SeaTunnel has introduced source and target connectors for Milvus, enabling more efficient vector data processing for AI applications.
\
To meet the needs of more users, the community is planning to add and optimize several new features.
Introduction of SeaTunnel Zeta Master/Worker ArchitectureSeaTunnel Zeta introduces a new Master/Worker architecture, allowing multiple versions of Hadoop or Hive synchronization tasks to run simultaneously in the same environment.
\
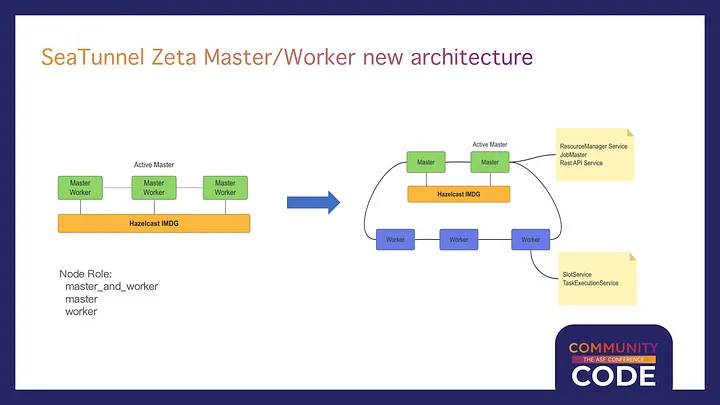
Note: Due to the time lag in organizing this article, this feature has already been implemented in version 2.3.6.
Creating SeaTunnel Jobs with SQLSeaTunnel Zeta supports creating data synchronization tasks directly using SQL statements, simplifying the job configuration process.
Note: This feature has also been implemented in version 2.3.6.
\

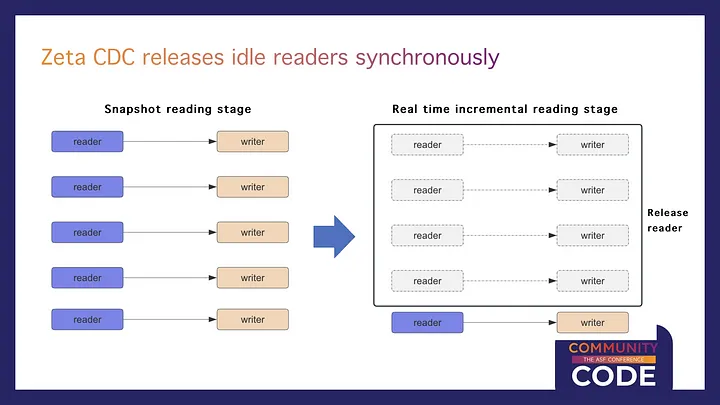
Zeta CDC has improved the synchronization release mechanism for idle readers, optimizing performance during snapshot reading and real-time incremental reading phases.
\
By refactoring the ClassLoader and plugin loading mechanism, SeaTunnel Zeta can run multiple versions of Hadoop or Hive synchronization tasks simultaneously in the same environment, enhancing system compatibility and flexibility.
Note: This feature has also been implemented in version 2.3.6.
CDC Synchronization Monitoring OptimizationSeaTunnel’s CDC synchronization will support monitoring metrics at the granularity of DML event types, improving observability.
Event Notification Mechanism SupportSeaTunnel Zeta supports an event notification mechanism, allowing specific event triggers during the data synchronization process, and enhancing system interactivity and automation.
ConclusionAs a top-level project of the Apache Software Foundation, SeaTunnel’s technical architecture evolution and applications in the AI field demonstrate the immense potential of open-source data integration tools. We look forward to working with the community to further advance SeaTunnel’s development. If you have any questions or suggestions, feel free to comment.
\