and the distribution of digital products.
DreamLLM: Synergistic Multimodal Comprehension and Creation: Text-Conditional Image Synthesis
2 Background & Problem Statement
2.1 How can we use MLLMs for Diffusion Synthesis that Synergizes both sides?
3.1 End-to-End Interleaved generative Pretraining (I-GPT)
4 Experiments and 4.1 Multimodal Comprehension
4.2 Text-Conditional Image Synthesis
4.3 Multimodal Joint Creation & Comprehension
5 Discussions
5.1 Synergy between creation & Comprehension?
5. 2 What is learned by DreamLLM?
B Additional Qualitative Examples
E Limitations, Failure Cases & Future Works
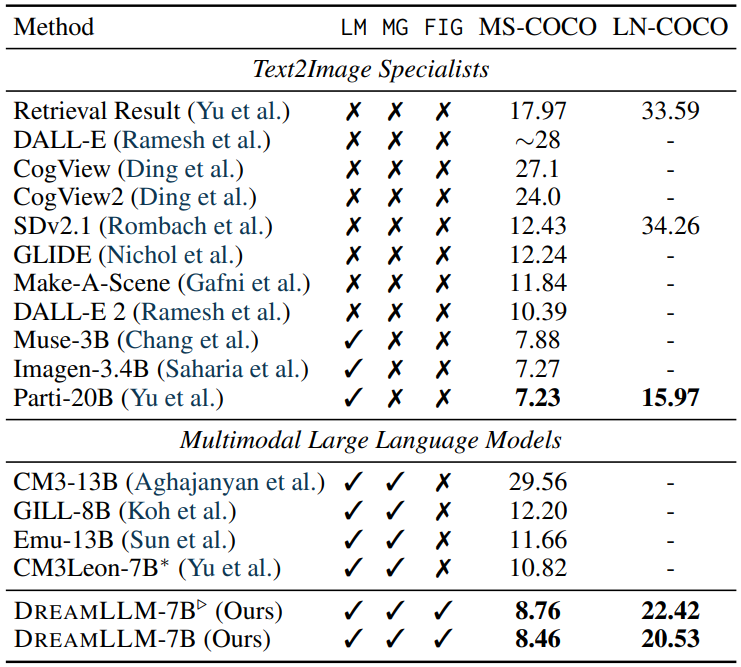
4.2 TEXT-CONDITIONAL IMAGE SYNTHESISText-conditional image synthesis is one of the most commonly used techniques for creative content generation that follows human’s fabulous imaginations through free-form languages.
\ We assess text-conditional image synthesis on the MS-COCO validation set (Lin et al., 2014) and LN-COCO, the COCO subset of Localized Narratives (PontTuset et al., 2020), following prior works (Xu et al., 2018; Yu et al., 2022b).
\ The MS-COCO dataset primarily contains high-level image abstractions with shorter captions, whereas LN-COCO provides more comprehensive image descriptions (Yu et al., 2022b). DREAMLLM samples 8 images per text prompt on MSCOCO by CLIP score ranking, following previous works (Ramesh et al., 2022).
\ On LN-COCO, DREAMLLM samples one image per prompt without CLIP ranking since the text is too long and exceeds the CLIP length limit. Note that Parti samples 16 images per prompt with CoCa (Yu et al., 2022a).
\ Our evaluation metric is the zero-shot Fréchet Inception Distance (FID) (Heusel et al., 2017), the results of which are presented in Table 2. We note three key observations: i) Our DREAMLLM shows a significant FID improvement over the Stable Diffusion baseline after stage-I alignment, reducing the score by 3.67 and 11.83 on MS-COCO and LN-COCO respectively. Further, FID improvements of 3.97 and 13.73 are achieved after pretraining and supervised fine-tuning.
\ The substantial improvement on LN-COCO underscores DREAMLLM’s superior capability in processing long-context information. ii) When compared to prior specialist models, DREAMLLM delivers competitive results based on the SD image decoder. iii) DREAMLLM consistently outperforms concurrent MLLMs-based image synthesis methods. For instance, DREAMLLM-7B surpasses Emu-13B by a significant 3.20 FID on MS-COCO. See qualitative results on text-to-image synthesis in Fig. 10 and Fig. 11 in Appendix B.
\
\
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
:::
:::info Authors:
(1) Runpei Dong, Xi’an Jiaotong University and Internship at MEGVII;
(2) Chunrui Han, MEGVII Technology;
(3) Yuang Peng, Tsinghua University and Internship at MEGVII;
(4) Zekun Qi, Xi’an Jiaotong University and Internship at MEGVII;
(5) Zheng Ge, MEGVII Technology;
(6) Jinrong Yang, HUST and Internship at MEGVII;
(7) Liang Zhao, MEGVII Technology;
(8) Jianjian Sun, MEGVII Technology;
(9) Hongyu Zhou, MEGVII Technology;
(10) Haoran Wei, MEGVII Technology;
(11) Xiangwen Kong, MEGVII Technology;
(12) Xiangyu Zhang, MEGVII Technology and a Project leader;
(13) Kaisheng Ma, Tsinghua University and a Corresponding author;
(14) Li Yi, Tsinghua University, a Corresponding authors and Project leader.
:::
\