and the distribution of digital products.
DeepSeek vs ChatGPT vs Perplexity vs Qwen vs Claude vs DeepMind: More AI Agents and New AI Tools
Hello AI Enthusiasts!
\ Welcome to the fourth edition of "This Week in AI Engineering"! \n \n Ever since the DeepSeek boom, all the leading AI companies have been updating their models and releasing their own AI agents left, right, and center. \n \n We’ll be getting into all these updates along with some must-know tools to make developing AI agents and apps easier.
Qwen Series: Open-Source Model Family Achieves New Milestones in Multilingual PerformanceQwen has expanded its open-source language model ecosystem, introducing four models ranging from 1.8B to 72B parameters, marking a significant advancement in multilingual AI capabilities.
\ Technical Architecture:
- Model Family Design: Introduced distinct variants including Qwen-Chat, Code-Qwen, Math-Qwen-Chat, Qwen-VL, and Qwen-Audio-Chat with targeted optimizations.
\
- Context Processing: Extended 32K token context window implemented through continual pretraining with RoPE optimization.
\
- Training Scale: Has extensive pretraining on 2-3 trillion tokens with multilingual optimization.
\ Performance Metrics:
- Memory Efficiency: Optimized resource usage from 5.8GB (1.8B model) to 61.4GB (72B model).
\
- Context Handling: Validated through "Needle in a Haystack" evaluations with consistent accuracy across long contexts.
\
- Training Optimization: Enhanced SFT and RLHF implementation with quality-controlled comparison data.
\ Development Features:
- Alignment Optimization: Refined SFT process with diverse, complex training data (Instag and Tulu 2).
\
- Agent Framework: AgentFabric implementation for custom AI agent configuration via a chat interface.
\ The series represents a significant leap in open-source language model development, particularly in multilingual capabilities and practical deployment scenarios, while maintaining efficient resource utilization.
DeepSeek vs GPT-4 vs Qwen: Advanced Architecture Benchmarks and Performance AnalysisThe latest benchmark evaluations reveal a significant architectural battle between Qwen 2.5-Max's efficient MoE implementation, DeepSeek-V3's massive parameter scaling, and GPT-4's dense architecture optimization. Qwen 2.5-Max leverages 64 specialized expert networks with dynamic activation, achieving 30% computational reduction while maintaining superior performance across technical benchmarks.
\ Program Structure:
- Qwen 2.5-Max: Has 72B parameter MoE model, 20T training tokens, 128K context window, 64 expert networks.
- DeepSeek-V3: Caries 671B parameters (37B active per token), 14.8T training tokens, 2.788M H800 GPU hours.
- GPT-4: With a dense architecture and 192 token contexts, it is optimized for multi-modal processing. \n
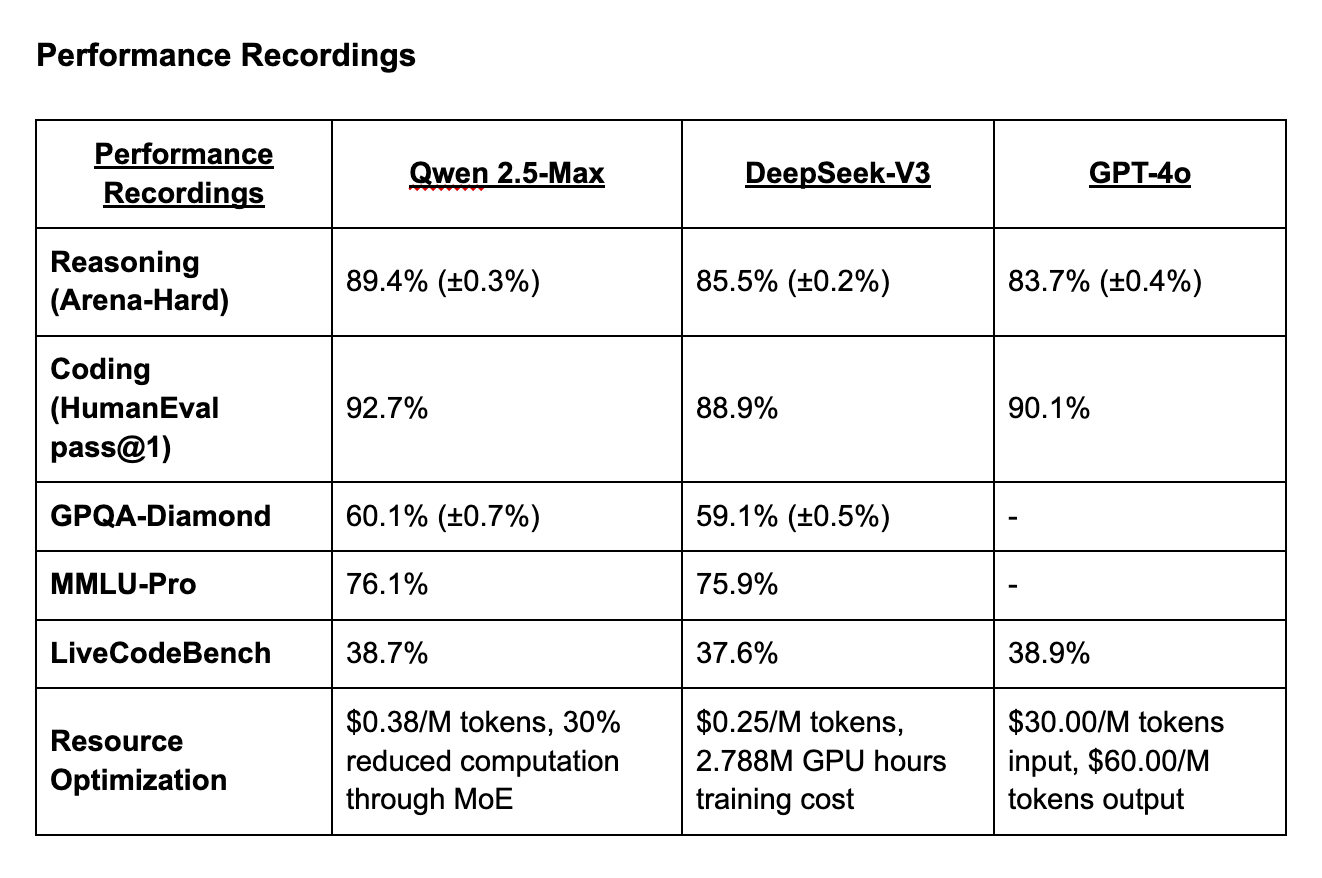
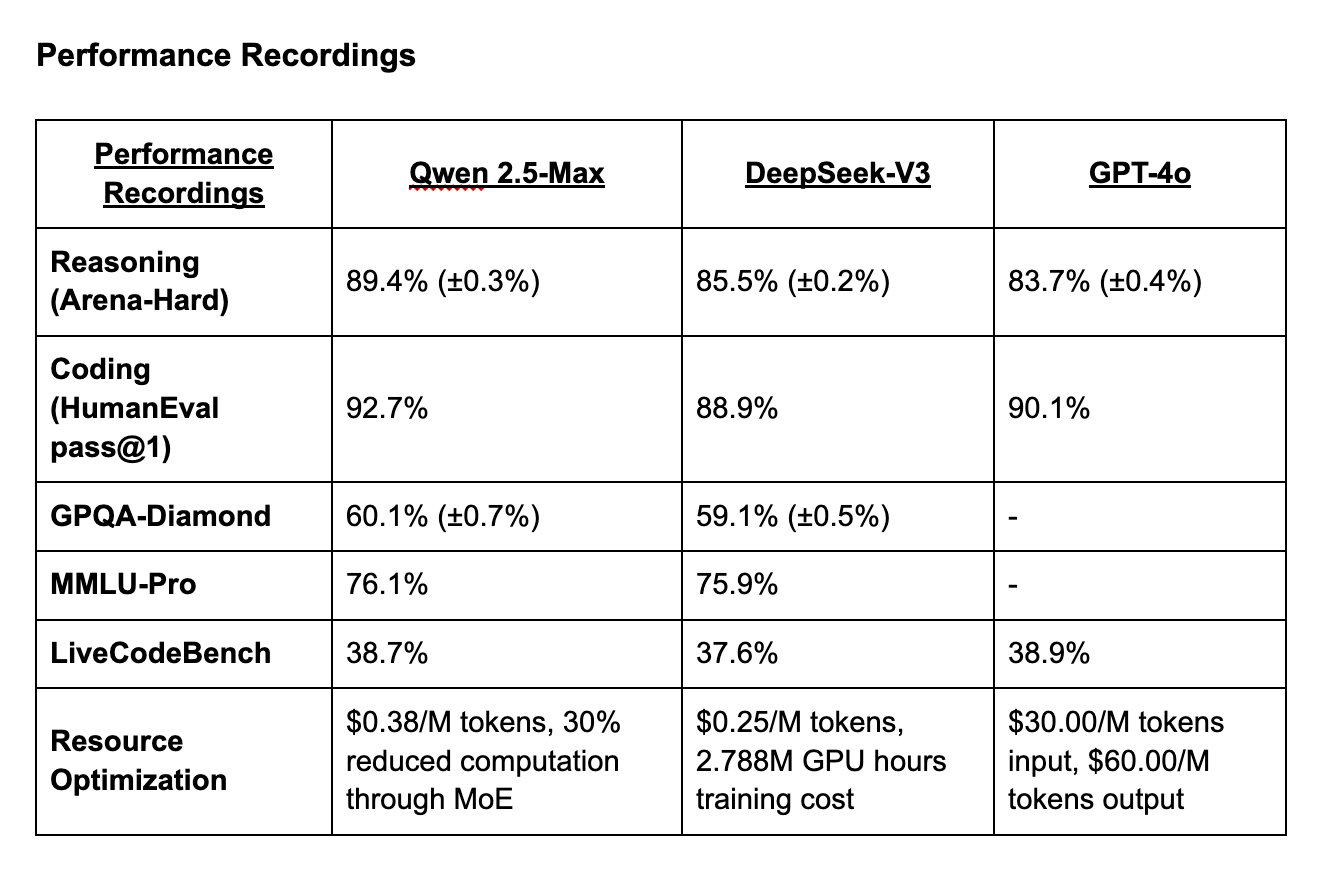
DeepSeek-V3 leverages massive model size with efficient parameter activation, while GPT-4 maintains competitive performance through dense architecture optimization.
OpenAI's Operator: Advancing Browser Automation with the Computer-Using Agent ModelOpenAI has introduced Operator, a cutting-edge browser automation agent powered by GPT-4o's vision capabilities. The research preview showcases the Computer-Using Agent (CUA) model, setting new benchmarks in automated web interaction and task execution.
Model Architecture
- Computer-Using Agent (CUA): It Integrates GPT-4o’s vision with advanced reasoning.
\
- Screenshot-based visual processing: Allows precise GUI element recognition.
\ Core Capabilities
- Browser Interaction: Supports directly manipulating web elements using simulated mouse and keyboard inputs.
\
- Task Management: Executes multiple workflows in parallel with isolated conversation threads.
\
- Visual Processing: Detects and interacts with GUI elements in real-time.
\ OpenAI is actively collaborating with DoorDash, Instacart, and Uber to deploy Operator in real-world applications while ensuring strict security and privacy standards.
Google DeepMind's Mind Evolution: Search Strategy for Enhanced LLM InferenceGoogle DeepMind has introduced Mind Evolution, which has achieved remarkable improvements on practical tasks, pushing Gemini 1.5 Flash from a 5.6% to 95.2% success rate on TravelPlanner benchmarks.
\ Technical Implementation:
- Solution Generation: LLM-driven prompt-based initial population creation and Critic-Author dialogue system for solution evaluation.
\
- Compute Requirements: Presents 167 API calls vs single baseline call, 3M tokens vs 9K baseline.
\ Performance Metrics:
- TravelPlanner Success: 95.2% for Gemini 1.5 Flash, 99.9% for Gemini 1.5 Pro.
\
- StegPoet Results: 43.3% on Flash, 79% on Pro for complex steganography tasks.
\ Token Usage:
- 3 million tokens per comprehensive solution, compared to 9,000 baseline.
\ The system demonstrates significant improvements in complex planning tasks without requiring formal solvers, though at increased computational cost.
Perplexity Assistant: Multi-Modal AI Agent for Advanced Mobile Task AutomationPerplexity AI has launched its mobile assistant, introducing a sophisticated multi-modal AI system that combines screen analysis, voice processing, and cross-app automation capabilities.
\ Technical Capabilities:
- Visual Analysis: 90% accuracy in screen content interpretation.
\
- Input Processing: Multi-modal support (voice, touch, camera, screen).
\ Core Features:
- Real-Time Processing: Camera-based object and text recognition.
\
- Cross-App Automation: Integrated booking and scheduling systems.
\
- Event Intelligence: Automated date verification and reminder setting.
\ The system demonstrates advanced capabilities in task automation while maintaining free access, though current limitations include wake-word activation and occasional contact management issues.
Perplexity Sonar Pro: Real-Time Search API with Advanced Citation ArchitecturePerplexity has launched Sonar Pro API, introducing an advanced web intelligence system that combines real-time search capabilities with automated citation generation, achieving 0.858 F-score on SimpleQA benchmarks while maintaining sub-100ms query latency.
\ Technical Architecture:
- Query Infrastructure: Asynchronous processing with 150ms average response time, supporting up to 500 concurrent requests/second.
\
- Context Processing: Extended window up to 100K tokens, dynamic memory allocation with 95% cache hit rate.
\
- Integration Layer: RESTful API endpoints with WebSocket support, JSON/gRPC protocols, and 128-bit SSL encryption.
\ Performance Metrics:
- Query Speed: 85ms average latency (p99 < 150ms) for standard queries.
\
- Throughput: 30K queries/minute with auto-scaling support up to 100K QPM.
\ Enterprise Implementation:
- Deployment Success: 20% throughput increase at Copy AI, 8-hour weekly efficiency gain.
\
- Security Protocol: SOC2 Type II compliant with role-based access control.
Anthropic has launched Citations, a sophisticated API feature for Claude 3.5 Sonnet and Haiku that enables precise source verification through automated document analysis. The system demonstrates significant improvements in citation accuracy while streamlining the development process.
Technical Architecture:
- Document Processing: Automated sentence-level chunking for PDFs and text files.
\
- Integration Layer: Has Native support in Messages API and Vertex AI.
\ Performance Features:
- Accuracy Improvement: 15% gain in recall accuracy over custom implementations.
\
- Granularity: Provides sentence-level chunking with custom content support with citation format reducing output costs.
\ Real-World Impact:
- Citation Density: 20% increase in references per response.
\
- Processing Flexibility: Supports documents without requiring file storage.
\ The system has demonstrated substantial improvements in enterprise applications, with Thomson Reuters reporting enhanced accuracy in legal documentation and Endex achieving zero hallucinations in financial research implementations.
Humanity's Last Exam: Redefining AI Model EvaluationThe Center for AI Safety and Scale AI has introduced Humanity's Last Exam (HLE), a groundbreaking benchmark that uncovers critical weaknesses in state-of-the-art language models.
\ Benchmark Design:
- Dataset Construction: 3,000 highly specialized questions developed by nearly 1,000 subject matter experts.
\
- Knowledge Scope: Covers over 100 academic disciplines, including cutting-edge research areas.
\ Model Performance:
HLE Accuracy Rankings:
- o3-mini (high computing): 13.0% accuracy, 93.2% calibration error.
\
- DeepSeek-R1: 9.4% accuracy, 81.8% calibration error.
\
- Gemini Thinking: 7.7% accuracy, 91.2% calibration error.
\
- GPT-4o: 3.3% accuracy, 92.5% calibration error.
\ Comparison with Traditional Benchmarks:
- On standard academic tests like MMLU, models score above 85% accuracy.
\
- In HLE, no model surpasses 13%, revealing major performance gaps.
\
- All models exhibit over 80% calibration error, indicating significant overconfidence.
- Browser-Use: This tool simplifies the integration of AI agents with web browsers by extracting all interactive elements from websites. This allows agents to focus on specific tasks, enhancing their functionality. Ideal for individual developers and open-source projects, it also offers custom solutions for teams and businesses needing advanced features and support.
\
- Cline 3.2: Cline 3.2 is an AI-powered coding assistant designed to enhance developer productivity. Utilizing advanced natural language processing (NLP) and machine learning (ML) techniques, it offers real-time code suggestions, error detection, and context-aware autocompletion. Cline 3.2 streamlines coding tasks, making software development more efficient and accessible for all developers.
\
ByteDance Doubao 1.5 Pro: ByteDance's Doubao 1.5 Pro is an advanced large language model that employs a sparse Mixture of Experts (MoE) architecture, optimizing performance with fewer activation parameters. It significantly outperforms competitors like GPT-4o in various benchmarks while maintaining lower inference costs. This model is designed for efficiency, achieving a gross margin of 50% due to its cost-effective training methods and flexible chip support
\
And that wraps up this issue of "This Week in AI Engineering."
\ Thank you for tuning in! Be sure to share this newsletter with your fellow AI enthusiasts and subscribe to get the latest updates directly in your inbox.
\ Until next time, happy building!