and the distribution of digital products.
Cross-Prompt Attacks and Data Ablations Impact SLM Robustness
Part 1: Abstract & Introduction
Part 2: Background
Part 3: Attacks & Countermeasures
Part 4: Experimental Setup
Part 5: Datasets & Evaluation
Part 6: Attack, Countermeasure Parameters, & Baseline: Random Perturbations
Part 7: Results & Discussion
Part 8: Transfer Attacks & Countermeasures
Part 9: Conclusion, Limitations, & Ethics Statement
Part 10: Appendix: Audio Encoder Pre-training & Evaluation
Part 11: Appendix: Cross-prompt attacks, Training Data Ablations, & Impact of random noise on helpfulness
Part 12: Appendix: Adaptive attacks & Qualitative Examples
\
A.3 Cross-prompt attacksIn Table 7, we report the results of jailbreaking the models using cross-prompt attack strategies. In particular, for each target question, we use 10 randomly selected perturbations (from successful attacks on the model). We report an attack successful if atleast one of the 10 perturbations is able to jailbreak the system. We observe that cross-prompt attacks are less effective than samplespecific attacks. However, they do show slightly more success in attacking than random perturbations. The reason for this could be the mismatched length between the perturbation and the target audio, which required truncation or replication of the perturbation. Further study is required to assess the possibility of more sophisticated cross-prompt attacks that leverage information about the audio length to tailor the perturbation accordingly.
A.4 Training Data AblationsIn Table 8, we study the usefulness of incorporating general instruction tuning data during cross-modal instruction fine-tuning stage for SLM models. We identify three of the best performing ASR pretrained and safety-aligned SLM models from Table 2 to conduct this study.
\ As discussed in Section 4.1, we observe that incorporating TTS data of Alpaca improves the helpfulness of SLMs on general questions. We further notice that such models have capabilities to outperform their counterparts in safety and relevance as well, especially when the backbone LLMs are taken out-of-the-box without any safety alignments (Flan-T5 (3B) and Mistral-7B). However, when backbone LLMs are tuned for harmlessness (Mistral-7B-FT), we observe that there is a healthy tension between helpfulness and harmlessness, indicating merits of using general instruction data as well as a further scope for improving safety alignment of SLMs.
\
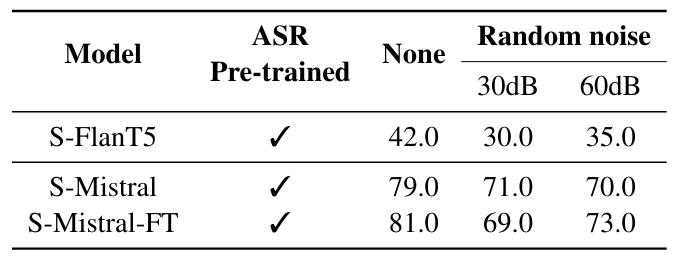
\
We study the effect of random noise perturbations on helpfulness questions against three in-house SLM models, trained with ASR modality preadaptation. We demonstrate the results in Table 9 and compare the results with the original spoken questions without any perturbations. We observe that for models with strong helpfulness capabilities, random noising can effect at most 15% of their usefulness. We believe that the robustness of SLMs for helpfulness can be improved by adding more general instruction tuning data and by noisy data augmentations during training. We leave this exploration to future work.
\ \
:::info Authors:
(1) Raghuveer Peri, AWS AI Labs, Amazon and with Equal Contributions (raghperi@amazon.com);
(2) Sai Muralidhar Jayanthi, AWS AI Labs, Amazon and with Equal Contributions;
(3) Srikanth Ronanki, AWS AI Labs, Amazon;
(4) Anshu Bhatia, AWS AI Labs, Amazon;
(5) Karel Mundnich, AWS AI Labs, Amazon;
(6) Saket Dingliwal, AWS AI Labs, Amazon;
(7) Nilaksh Das, AWS AI Labs, Amazon;
(8) Zejiang Hou, AWS AI Labs, Amazon;
(9) Goeric Huybrechts, AWS AI Labs, Amazon;
(10) Srikanth Vishnubhotla, AWS AI Labs, Amazon;
(11) Daniel Garcia-Romero, AWS AI Labs, Amazon;
(12) Sundararajan Srinivasan, AWS AI Labs, Amazon;
(13) Kyu J Han, AWS AI Labs, Amazon;
(14) Katrin Kirchhoff, AWS AI Labs, Amazon.
:::
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\