and the distribution of digital products.
Building Asset and Risk Management on Codebase with Semgrep
\ We'll talk about base components of a stereotypical microservice in a Digital Products, what vulnerabilities are associated with these components, how the overall risk related to number and structure of objects processed in the service’s API, stored in the database or received in client methods of other services, how to extract the structure of these objects from the code using Semgrep rules and store them for analytics, how to assess the extracted structure and obtain resulting risk level, as well as how and where else we can use discovered data and measured risks.
\
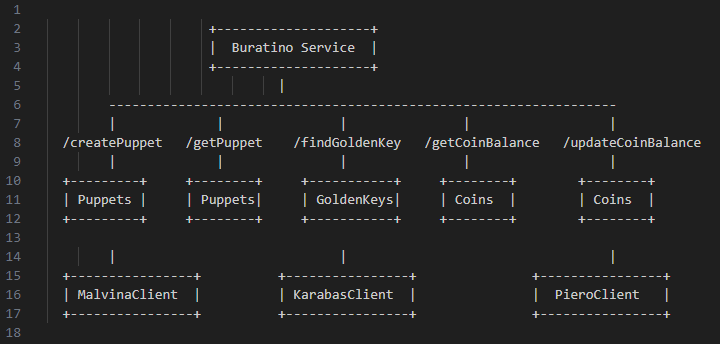
Understanding Microservice StructureMicroservices are typically organized around API handlers that interact with databases and external clients. In the case of the Buratino service, several handlers interact with different data entities and clients:
\
\
API Handlers:
/createPuppet - adds a new puppet entry to the database table public.Puppets.
/getPuppet - retrieves puppet details from the public.Puppets database table.
/findGoldenKey - looks up specific entries in the public.GoldenKeys table.
/getCoinBalance - fetches coin balance from the public.Coins table.
/updateCoinBalance - updates coin balance records in the same table.
\
Database: The handlers connect to various tables in the service's databases, including:
public.Puppets - stores puppet-related data, accessed by handlers like /createPuppet and /getPuppet.
public.GoldenKeys - used by handlers such as /findGoldenKey to store and retrieve special keys.
public.Coins - tracks coin balances, used by /getCoinBalance and /updateCoinBalance.
\
Clients: Handlers may also interact with external services via clients. For instance:
MalvinaClient - used to communicate with the Malvina service, likely to handle puppet-related operations outside the main database.
KarabasClient - another external service client for managing operations possibly related to golden keys or other assets.
PieroClient - handles operations possibly related to user balances or accounts, complementing database interactions in the Buratino service.
\
The sensitive data flowing between these components, both internal databases and external clients, creates potential risk vectors, which must be managed carefully to mitigate exposure.
\
Assessing Assets and RisksIn a microservice environment, risks are generally assessed by evaluating the likelihood of an event occurring and the potential impact of that event. This approach helps identify which areas of the system are most vulnerable and require immediate attention. Several key factors play a role in assessing risks:
\
IDOR (Insecure Direct Object Reference)
API handlers that expose sensitive data without proper access controls represent a significant risk. The more handlers in the system that interact with sensitive data, the higher the risk level. For instance, handlers like/getPuppet or /getCoinBalance may be vulnerable to IDOR attacks if they allow unauthorized access to user-specific data. More handlers with sensitive fields increase the potential attack surface, which heightens the risk.
\
SQL Injection (SQLi)
SQL injection vulnerabilities occur when user input is not sanitized and interacts directly with the database. Handlers like /createPuppet and /findGoldenKey that allow user input to directly query the database are particularly vulnerable. The more tables in the database that contain critical fields (such as personally identifiable information or financial data), the greater the risk. In databases with a high volume of sensitive records, the potential impact of SQLi is magnified.
\
RCE (Remote Code Execution)
Remote Code Execution risks arise when external inputs or processes lead to the execution of arbitrary code within the service. For example the/createPuppet handler can put client parameters to some kind of Template Engine and be vulnerable to SSTI, or some user input can be placed into cli tools. So more more handlers and complex interaction between services, the greater the risk.
\
Log Exposure
Excessive logging of sensitive data can increase risk, as logs may contain personal or financial information. So more handlers that process sensitive data (e.g., user credentials or financial transactions), the greater the risk.
\ To measure risk, it's crucial to consider both the sensitivity of the data and the volume of data handled by each service or API endpoint. Generally, the more sensitive data that crosses a service’s boundary (through API handlers, databases, or client interactions), the higher the risk.
\
Extracting Objects from the Code with SemgrepTo effectively assess and manage risks in a microservice architecture, we should extract and analyze key objects from the codebase:
\
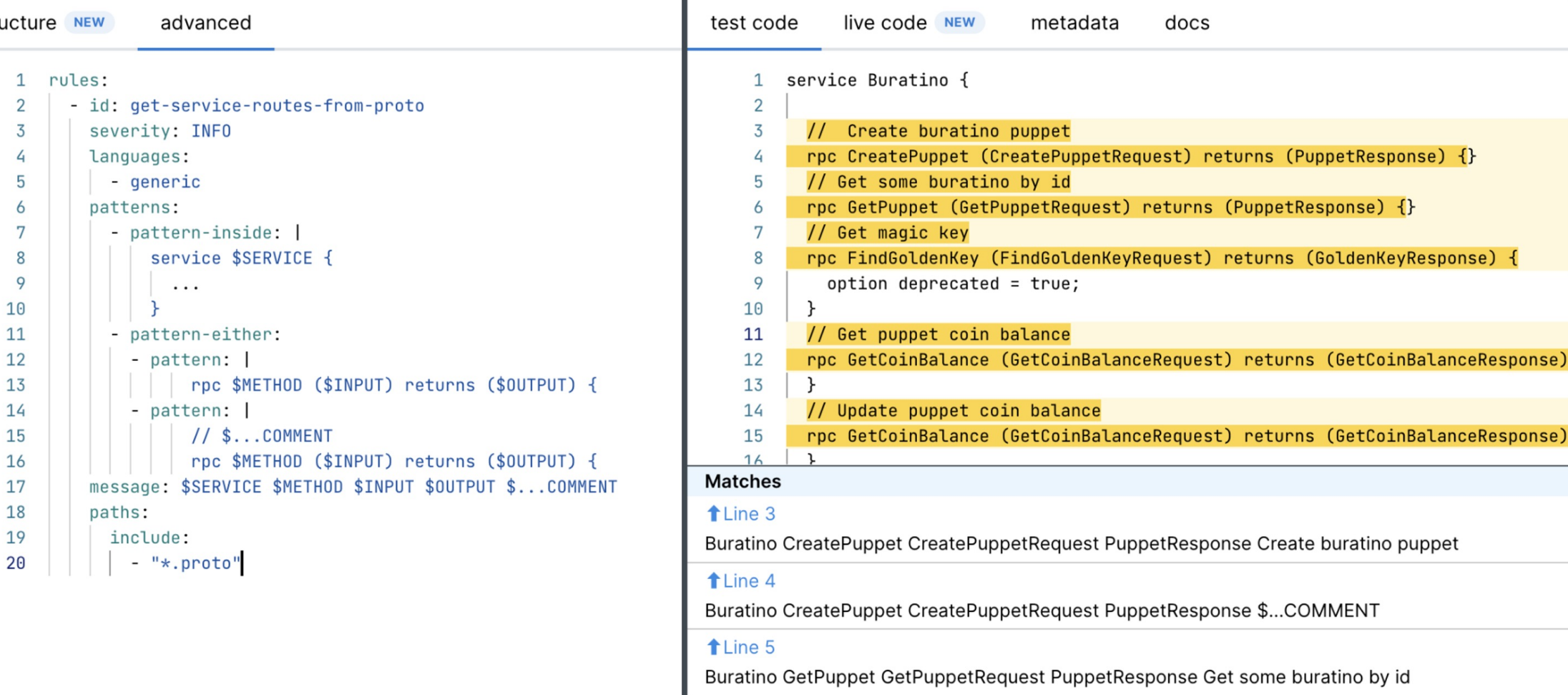
API Handler Schemas
Extract the structure of API handlers from formats like protobuf, GraphQL, or Swagger. These schemas define the input and output data for each handler, such as the parameters passed to /createPuppet or /getCoinBalance. Sensitive fields, such as PII or financial information, are critical in this analysis, as the presence of more such fields in handlers increases the potential attack surface.
\
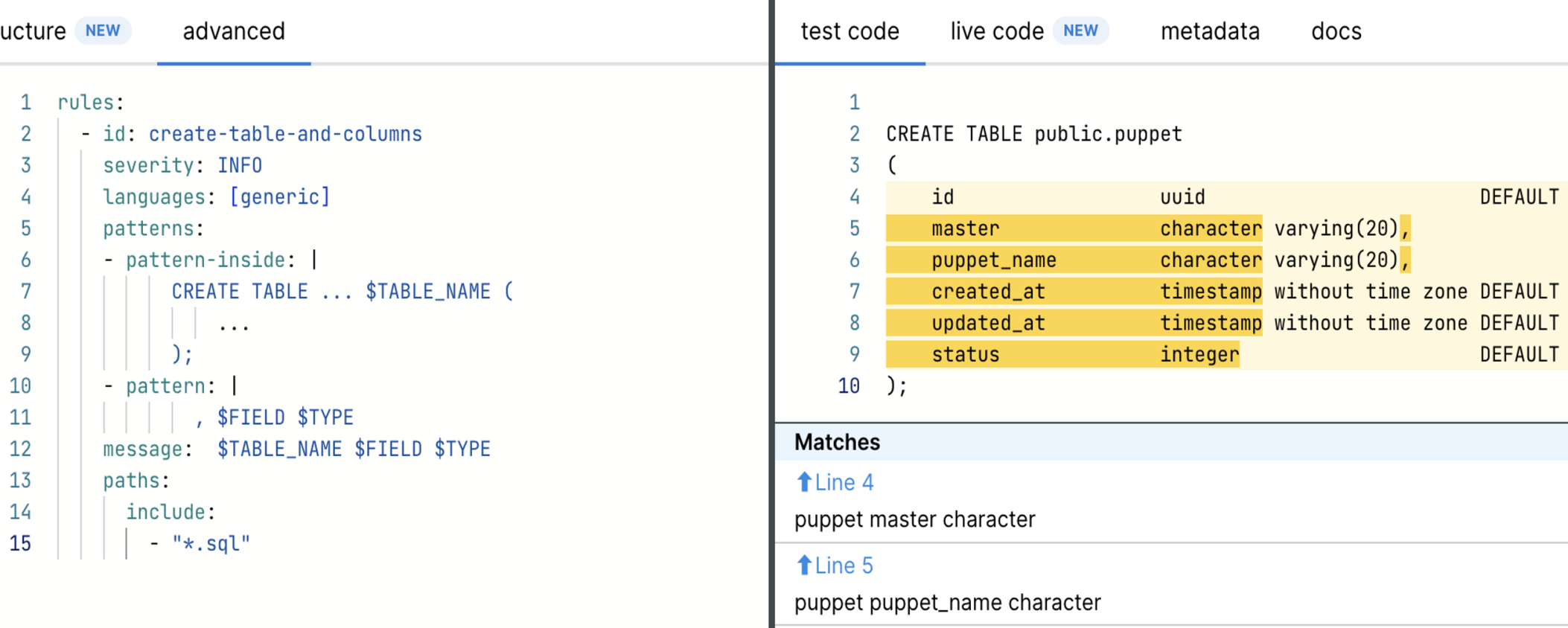
Database Schemas
Extract database schemas from the models and migrations in the code. This provides a clear picture of how sensitive data is structured in tables like Puppets, GoldenKeys, or Coins.
\
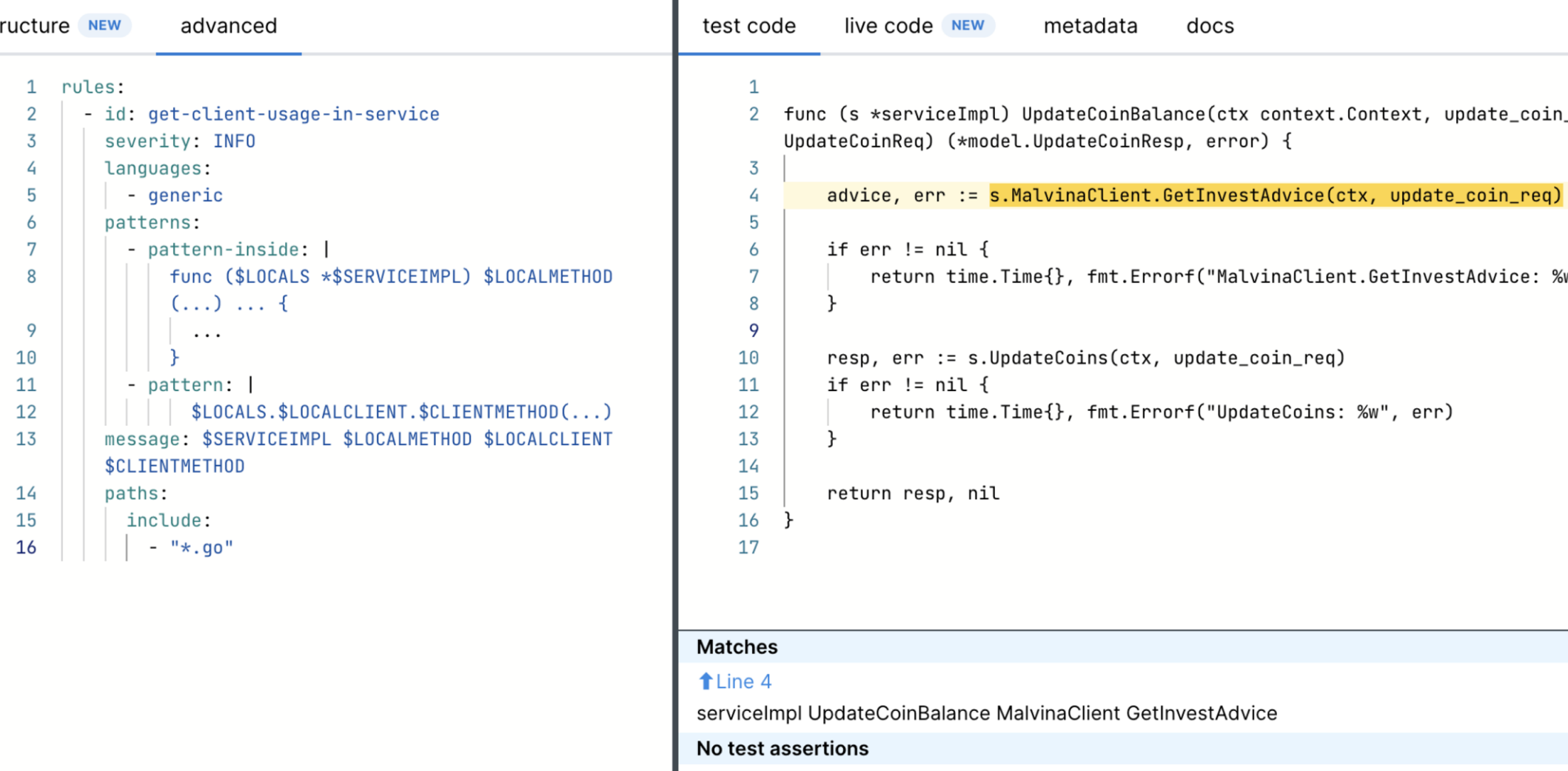
Client Interaction Schemas
Extract client names, methods, and schemas. These represent interactions between the microservice and external clients like MalvinaClient, KarabasClient, and PieroClient.
\
Dangerous Function Calls
Identify and flag potentially dangerous function calls, such as those involved in cryptography, authentication, or input validation. These functions, when misused or improperly configured, can create security vulnerabilities. For instance, insecure cryptographic functions used in handling sensitive data, or improperly validated user input, could lead to breaches such as RCE or SSTI.
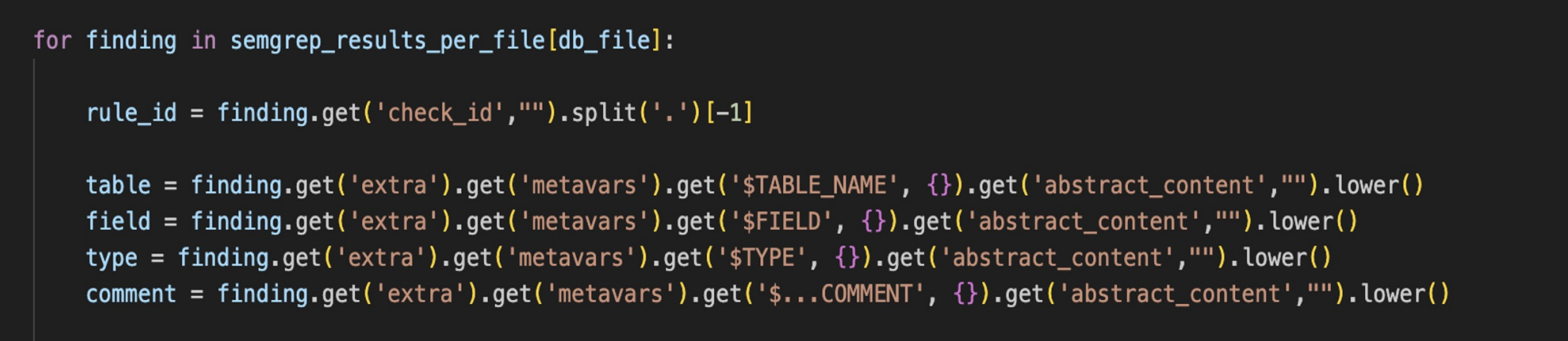
\ We can use simple Semgrep rules to find patterns in code and extract from json reports captured objects and fields names via metavars. Just copy and paste code pattern into semgrep rule and replace objects and fields names with $METAVAR names:
\
Database schema\
\
Protobuf\
\
Client call\
\
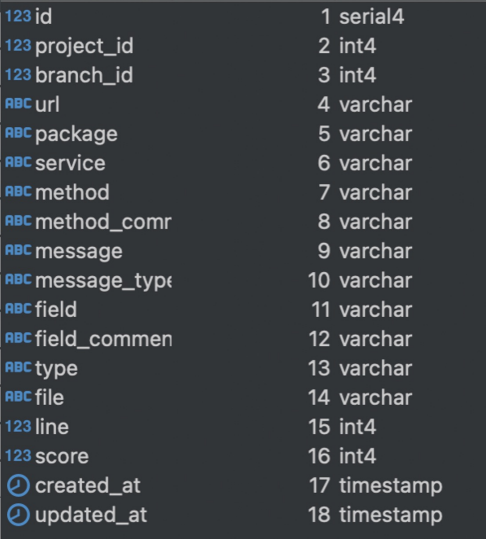
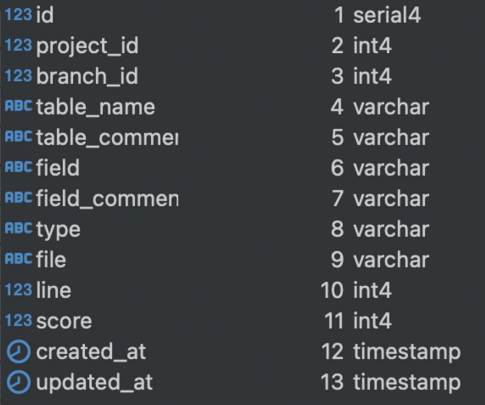
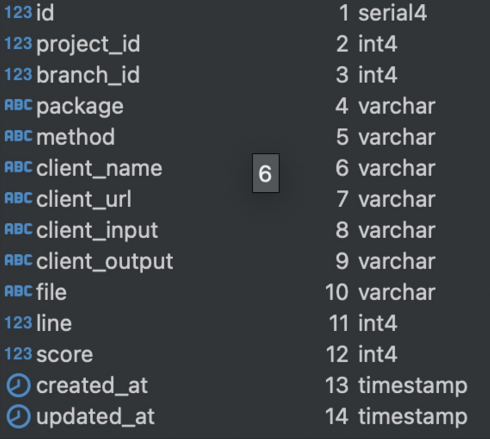
Extracting results\
\
\ \
Scoring Risks for Extracted ObjectsOnce key objects like API handlers, database tables, and client interactions are extracted from the codebase, it is time to assign risk scores for them. In this context, we assume that the volume of data is not retrievable from the code, so the risk scoring will focus on data sensitivity, complexity, and exposure. This approach allows us to prioritize security efforts based on the inherent risk of the objects themselves, without considering the number of records stored or processed.
\
Key Factors in Risk ScoringSensitive Data Fields
High-risk fields, such as financial data (e.g., "balance", "account_number") or PII (e.g., "name", "email"), are scored based on their potential impact. The more sensitive the data, the higher the score.
API Handler Scoring
API handlers that process sensitive data receive higher scores. For example:
/getCoinBalance, which handles financial data, will have a higher score than /createPuppet, which processes less sensitive information.
Database Scoring
Risk is based on the sensitive fields stored and how many API handlers access the database:
A table like Coins, which stores "balance" and "account_number", and is accessed by multiple handlers, would receive a high score.
Client Interaction Scoring
Clients are scored based on the sensitive data exchanged and the complexity of interactions:
A client like MalvinaClient, which handles sensitive data and communicates with multiple handlers, will have a higher risk score.
\
Risk Scoring ExampleLet’s assert risks for each found object:
\ Table: Coins
Sensitive Fields: "balance" (score 10), "account_number" (score 9), "transaction_id" (score 8)
Handlers: Accessed by /getCoinBalance and /updateCoinBalance (score 6)
Total Database Score: 10 + 9 + 8 + 6 = 33
\ Client Call: MalvinaClient.GeInvestAdvice
Sensitive Data: Transmits "balance" (score 10), "account_number" (score 9)
Complexity: Used in multiple handlers (score 6)
Total Client Call Score: 10 + 9 + 6 = 25
\ By aggregating the risk scores for individual API handlers, database tables, and client interactions, a comprehensive risk profile for each service can be developed.
\ Total Service Risk Score (Buratino Service) = 25 (API) + 33 (Database) + 25 (Client) = 83
\ This aggregated risk score gives a holistic view of the overall risk for the Buratino service. Services with higher scores should receive higher security priority:
\
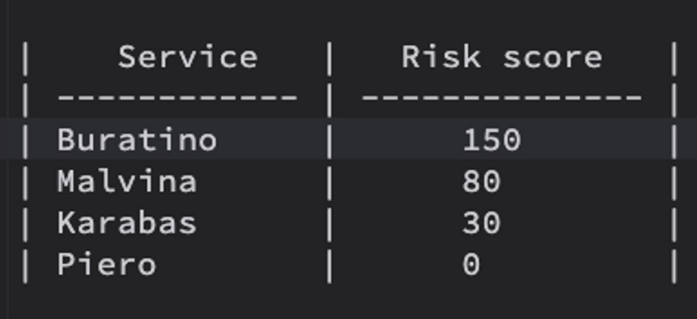
\ It’s important to monitor changes in the risk scores over time, especially as new features, API handlers, or database fields are added. Automated monitoring tools can alert security teams when significant changes occur, such as:
New API handlers processing and storing sensitive data.
New client interactions with critical data.
\
This continuous monitoring ensures that the security posture is constantly updated and adapted to evolving risks.
\

\
Leveraging Risk Scores for Actionable InsightsWith risk scores in hand, application secuirty teams can:
\
Prioritize remediation of vulnerabilities flagged by static analysis tools.
Determine the order of penetration tests or security audits.
Manage access policies to services and databases more effectively.
\
This process also enhances data governance by identifying sensitive data routes (e.g., Personally Identifiable Information, or PII) and ensuring they are properly managed.
\ Risk scores can be also employed in various ways, such as:
\
- Setting vulnerability remediation priorities.
- Managing service and database access approvals.
- Identifying and addressing misconfigured PII storage and routing.
\ Additionally, infrastructure assets from tools like Terraform or Ansible, as well as network rules and NGINX configurations, can also be extracted with this approach and integrated into the risk evaluation process.
\
ConclusionEffective asset and risk management within a product codebase is key to maintaining security in a microservice architecture. Automated tools like Semgrep streamline the process of identifying and assessing risks, allowing security teams to focus their efforts on the areas that matter most. By incorporating a risk-based approach, organizations can better prioritize security efforts and ensure the protection of sensitive data.
\ \ You can try same approach for scoring your assets in code and monitoring critical changes with my sample discovery service for Gitlab:
https://github.com/dmarushkin/appsec-discovery
\
\
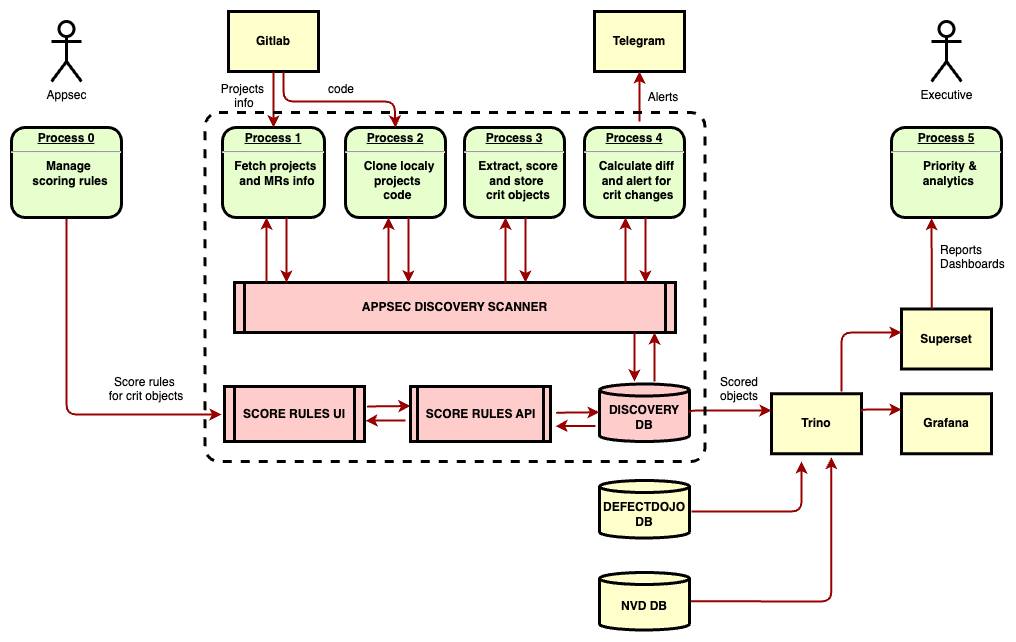
Or just grub only semgrep discovery rules to build you oun automation.
\ \