and the distribution of digital products.
Apparate: Early-Exit Models for ML Latency and Throughput Optimization - Overall Results
:::info Authors:
(1) Yinwei Dai, Princeton University (Equal contributions);
(2) Rui Pan, Princeton University (Equal contributions);
(3) Anand Iyer, Georgia Institute of Technology;
(4) Ravi Netravali, Georgia Institute of Technology.
:::
Table of Links2 Background and Motivation and 2.1 Model Serving Platforms
3.1 Preparing Models with Early Exits
3.2 Accuracy-Aware Threshold Tuning
3.3 Latency-Focused Ramp Adjustments
5 Evaluation and 5.1 Methodology
5.3 Comparison with Existing EE Strategies
7 Conclusion, References, Appendix
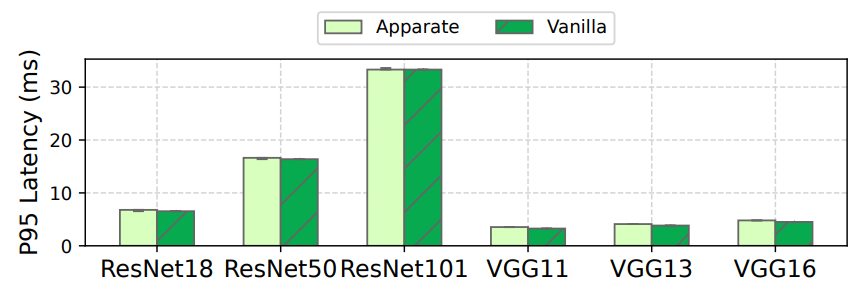
5.2 Overall ResultsFigures 13- 16 compare Apparate with vanilla model serving and optimal exiting across our workloads. Overall, Apparate significantly lowers latencies compared to serving vanilla models, while always adhering to the imposed 1% accuracy constraint. For instance, median speedups range from
\
\ 40.5-91.5% (2.7-30.5 ms) for CV workloads, and jump to 70.2-94.2% (5.2-31.4 ms) at the 25th percentiles. NLP workloads follow a similar pattern, with median and 25th percentile savings ranging from 10.0-24.2% (3.9-25.3 ms) and 16.0-37.3% (4.8-53.2 ms), respectively. Importantly, across all workloads, Apparate’s tail latency (and thus impact on throughput) always falls within its granted budget (2% here) and is most often negligible (Figure 14).
\ Beyond this, there are several important trends to note. First, Apparate’s raw latency savings grow with increased model sizes, e.g., 25th percentile wins of 53.2ms, 28.4ms, 14.3ms, 5.5ms for GPT-2, BERT-large, BERT-base, and Distilbert-base on the Amazon dataset. This is because only the results exit models with Apparate, with inputs running to completion; thus, latency savings pertain entirely to serving times (not queuing delays), with exit impact being higher as model size (and thus, runtime) grows. Relative (%) latency savings follow the same pattern for CV workloads, e.g., Apparate’s median wins grow by 13.8% and 5.3% moving from the smallest to the biggest models in the ResNet and VGG families. However, relative wins remain relatively stable in NLP models, e.g., 15.8% and 13.7% for GPT2 and BERTlarge on Amazon Reviews. The reason for this difference is in the effectiveness of the models in each domain. Results and task performance are largely similar across the considered CV models, enabling Apparate to inject ramps early in (even larger) models. In contrast, results and task efficacy are far better with the larger models in NLP; thus, Apparate’s ramps fall in similar (relative) positions across the models.
\ Second, Apparate’s wins are larger for CV workloads than NLP workloads for two reasons. As previously noted, CV workloads use lighter models and lower request rates (bound by video fps), and thus incur far lower queuing delays. More importantly, in contrast to CV where spatiotemporal similarities across frames (and thus, requests) are high due to physical constraints of object motion in a scene, NLP requests exhibit less continuity, e.g., back-to-back reviews are not constrained in semantic similarity. The effects on Apparate’s adaptation of EE configurations are that (1) past data is less representative of future data, and (2) the duration until subsequent adaptation is shorter.
\ Lastly, Apparate’s wins for NLP are consistently higher with the Amazon dataset versus the IMDB dataset. The reason is that the IMDB dataset exhibits ‘harder’ inputs that require later-ramp exits. For instance, for GPT-2, average exit locations for the offline optimal exit strategy are at layers 2.2 and 2.7 for Amazon and IMDB, respectively; these numbers are 2.1 and 2.5 for BERT-base.
\ Comparisons with optimal. As shown in Figure 13, latency savings with Apparate for CV workloads largely mirror those of the optimal that tunes exiting decisions based on perfect knowledge of the upcoming workload, e.g., median savings are within 20.5% of the optimal. In contrast, building on the discussion above, the limited continuity across inputs in NLP workloads leads to a wider gap of 73.1-83.2% at the median (Figure 16). To further characterize Apparate’s performance on these workloads, we also consider a more realistic online optimal algorithm that relaxes the following elements. First, rather than per-sample adaptation of thresholds and ramps, ramp adjustments are set to operate only as fast as model definitions in the GPU can be updated. Second, rather than using perfect knowledge of upcoming inputs, decisions are made using only recent (historical) data; for each threshold or ramp adaptation decision, we tune based on the past {20, 40, 80} batches of inputs and select the decision that performs best on the upcoming data. As shown in Figure 16, Apparate’s median latency savings are within 16.9-52.1% of this (more) realistic optimal exiting strategy
\ Varying SLOs. SLOs affect serving system batching and queuing decisions, and thus Apparate’s benefits. To study this effect, we considered SLOs for each model that were 2× and 4× those in our default experiments (Table 5). Generally, higher SLOs induce larger serving batch sizes and higher per-request queuing delays (as inputs wait for the previous, slower inference batch to complete); this dampens Apparate’s relative latency savings which target model runtimes, but not queuing delays. Figure 17 illustrates this effect. For instance, median latency savings for GPT-2 drop from 16.3% to 6.8% as SLO grows by 4×. Note that, to illustrate this trend for CV workloads, we upsampled each video to 120 fps. The reason is that our serving platforms are workconserving and, at 30 fps, they are able to consistently schedule jobs with batch size 1 and low queuing delays given the low runtimes of the considered CV models.
\
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
:::
\