and the distribution of digital products.
Apparate: Early-Exit Models for ML Latency and Throughput Optimization - Design
:::info Authors:
(1) Yinwei Dai, Princeton University (Equal contributions);
(2) Rui Pan, Princeton University (Equal contributions);
(3) Anand Iyer, Georgia Institute of Technology;
(4) Ravi Netravali, Georgia Institute of Technology.
:::
Table of Links2 Background and Motivation and 2.1 Model Serving Platforms
3.1 Preparing Models with Early Exits
3.2 Accuracy-Aware Threshold Tuning
3.3 Latency-Focused Ramp Adjustments
5 Evaluation and 5.1 Methodology
5.3 Comparison with Existing EE Strategies
7 Conclusion, References, Appendix
3 DESIGNApparate is an end-to-end system that automatically integrates early exits into models and manages their operation throughout the inference process. Its overarching goal is to optimize per-request latencies while adhering to tight accuracy constraints and throughput goals. Our key insight is in rethinking the way that EEs are configured and the benefits they are expected to deliver. In particular, rather than using EEs in the traditional way – where inputs exit model inference to provide both latency and computational benefits – Apparate focuses solely on latency savings by allowing results to exit, with inputs still running to completion. Foregoing true exiting (and thus, compute savings) eliminates batch size changes during inference (C4), while also granting Apparate with direct and continual feedback on EE accuracy (C3). This feedback, in turn, provides the requisite signals for Apparate’s strategy to continually adapt EE configurations to maximize latency savings while catering to resource constraints and workload dynamics (C1, C2).
\
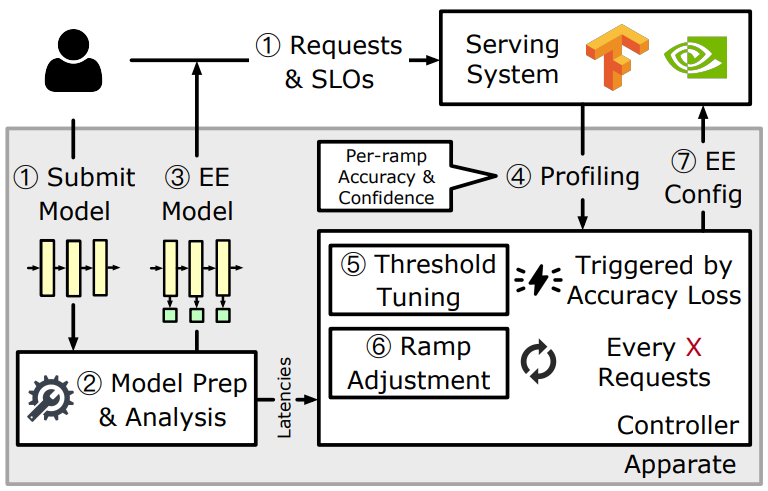
\ Figure 7 overviews Apparate’s workflow, which runs atop existing serving platforms. Users register inference jobs as normal 1, providing models and SLOs. In addition, Apparate introduces two parameters: (1) ramp aggression, which (along with compute restrictions) bounds the number of active ramps in terms of % impact on worst-case latency (and throughput), and (2) accuracy constraint which indicates how much (if any) accuracy loss is acceptable relative to running the submitted model on all inputs without exiting. With these inputs, Apparate’s controller begins by configuring the provided model with EEs 2, performing a graphlevel assessment to determine suitable positions for ramps, and training those ramps on bootstrap data (§3.1). The resulting model is passed to the serving platform for deployment 3, after which Apparate shifts to management mode. In this phase, as requests arrive and inference tasks are scheduled, Apparate’s controller gathers real-time feedback on both the utility of each ramp (overheads vs. latency savings) and achieved accuracies (relative to the original model) 4. This information is continually used to adapt the EE configuration 7 at different time scales: rapid threshold tuning for accuracy preservation (§3.2) 5, and less frequent ramp adjustments for latency optimization (§3.3) 6.
\ Note that Apparate’s controller runs on a CPU, with GPUs streaming per-ramp/batch profiling information in a nonblocking fashion. This is possible since inputs pass to the end of models with Apparate, irrespective of exiting decisions. Further, tasks associated with model handling and serving are handled by the underlying serving platform, e.g., loading from disk, queuing.
\
\
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
:::
\