and the distribution of digital products.
Anchor Data Augmentation (ADA): A Domain-Agnostic Method for Enhancing Regression Models
:::info Authors:
(1) Nora Schneider, Computer Science Department, ETH Zurich, Zurich, Switzerland ([email protected]);
(2) Shirin Goshtasbpour, Computer Science Department, ETH Zurich, Zurich, Switzerland and Swiss Data Science Center, Zurich, Switzerland ([email protected]);
(3) Fernando Perez-Cruz, Computer Science Department, ETH Zurich, Zurich, Switzerland and Swiss Data Science Center, Zurich, Switzerland ([email protected]).
:::
Table of Links2 Background
3.1 Comparison to C-Mixup and 3.2 Preserving nonlinear data structure
4 Experiments and 4.1 Linear synthetic data
4.2 Housing nonlinear regression
4.3 In-distribution Generalization
4.4 Out-of-distribution Robustness
5 Conclusion, Broader Impact, and References
\ A Additional information for Anchor Data Augmentation
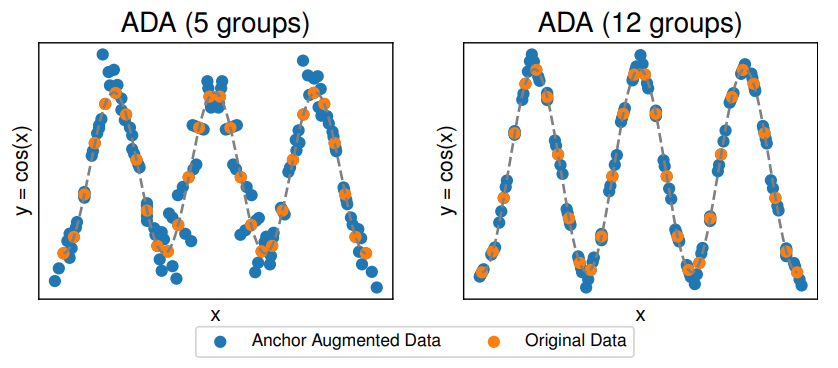
3 Anchor Data AugmentationIn this section, we introduce Anchor Data Augmentation (ADA), a domain-independent data augmentation method inspired by AR. ADA does not require previous knowledge about the data invariances nor manually engineered transformations. As opposed to existing domain-agnostic data augmentation methods [10, 45, 46], we do not require training of an expensive generative model, and the augmentation only adds marginally to the computation complexity of the training. In addition, since ADA originates from a causal regression problem, it can be readily applied to regression problems. Even when ADA does not improve performance, its effect on performance remains minimal.
\

\

\
\

\
:::info This paper is available on arxiv under CC0 1.0 DEED license.
:::
\